Compare commits
653 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| f701f64a57 | |||
| e532bfbe62 | |||
| aaa790ed70 | |||
| 6f4194cc08 | |||
| a67f47fe66 | |||
| 262a38b05c | |||
| ac189d1fbe | |||
| 4f8072b3b7 | |||
| a5905da88e | |||
| cc8d481e9e | |||
| 186b7d385a | |||
| ce305bed27 | |||
| 7c567c3d50 | |||
| 4357391adc | |||
| 5d96a16133 | |||
| 35fb2cf211 | |||
| 164954ef6f | |||
| b1cc546f09 | |||
| e66492d2ad | |||
| b3d3140ecd | |||
| 44ca636fce | |||
| e502a3601a | |||
| 0c4bc76552 | |||
| fdd48e7285 | |||
| a173c68676 | |||
| 09572f5c5e | |||
| 526771722f | |||
| 779868f95d | |||
| 7b4cc65e55 | |||
| 313c8f06ac | |||
| 01607f6993 | |||
| 54d84c3141 | |||
| cd109ca788 | |||
| 936f25eda3 | |||
| a8798ff612 | |||
| 5d06cf8cab | |||
| 2c8f644fb5 | |||
| 426498623e | |||
| 7cde4ddfcc | |||
| 949a1352c8 | |||
| d94d4aceab | |||
| cc681a9b8b | |||
| 83ffbba390 | |||
| ea86bb5880 | |||
| 07fc718ddc | |||
| 4c6fddcef4 | |||
| 859f34afbe | |||
| f949b9ca93 | |||
| 2526c118c8 | |||
| 5412dd2904 | |||
| a966e8d6a2 | |||
| 5fc24d5406 | |||
| 2156655a2a | |||
| 3d8f5d13e2 | |||
| e359d2a0cf | |||
| 898672ead8 | |||
| 5e47eeee0d | |||
| 1f28ee184e | |||
| a3c61c35df | |||
| 03d186cde6 | |||
| 4cd892c8c6 | |||
| 001a745a07 | |||
| a54dd12fef | |||
| 21e4a686e0 | |||
| 918b2458ab | |||
| 5d01e0f579 | |||
| 2fb37f0984 | |||
| c2eb52b58c | |||
| 17908d356c | |||
| 11575b9a00 | |||
| 571e4a1123 | |||
| 98763db632 | |||
| e96b47f3b4 | |||
| 5edb0a651a | |||
| 75b994926f | |||
| 8408e5be4c | |||
| 2fa8fe7a07 | |||
| cfdda33af6 | |||
| cc9f0957a7 | |||
| dde834d527 | |||
| b0afaadac2 | |||
| 8a299de099 | |||
| 112e72eb21 | |||
| cdf3b851dd | |||
| c9d3a905b9 | |||
| f7545bc2e0 | |||
| aa597d3013 | |||
| a4d3499d7f | |||
| 9732a8d47b | |||
| 181d8f25c5 | |||
| 6f207843a7 | |||
| fd1442565a | |||
| 5bc91de6c4 | |||
| ebbdde2012 | |||
| dc7b4b9805 | |||
| f44471a03e | |||
| e6f254dd36 | |||
| e7a8f76903 | |||
| 901922ea99 | |||
| 5d8ba9606c | |||
| 0db6c0f846 | |||
| 594e531f75 | |||
| 140d7aebb1 | |||
| 2da4434098 | |||
| 53e76af638 | |||
| 1c0ca47312 | |||
| fb091df7a6 | |||
| 4da514c1b6 | |||
| 4edb305830 | |||
| 4eb75699be | |||
| 7433a36783 | |||
| 9e2fdf8cda | |||
| 92919265d2 | |||
| d1fa52004f | |||
| 90e89d03b5 | |||
| a130e47969 | |||
| b6c0bf7ea9 | |||
| 8880394aaa | |||
| 850440dc77 | |||
| 9cecc37416 | |||
| 62b52b9544 | |||
| 0cb5331eeb | |||
| d12eff253c | |||
| 14691cfb66 | |||
| 0715b8c0ad | |||
| 711c9bcdcc | |||
| a83bb5fd1e | |||
| 1aafe7f8ce | |||
| a4436dd631 | |||
| 52cf22faea | |||
| 1a1e16b269 | |||
| 111b1157ad | |||
| dd5559d099 | |||
| b4773aea25 | |||
| 953002f37e | |||
| 1e51ecb9bb | |||
| 4ebe4c3260 | |||
| cc3603362d | |||
| e105376786 | |||
| 83d828e33d | |||
| 82fc2b348a | |||
| 4a2ab71b47 | |||
| ccff1891e1 | |||
| d124eed3bb | |||
| 2af749d6d6 | |||
| 813eef2feb | |||
| bc47450f6b | |||
| 80f839561e | |||
| 5679943bdd | |||
| 1e555e0efc | |||
| 7ec5eaeb9c | |||
| 0b5f210a74 | |||
| ce95936bcd | |||
| e837a6017f | |||
| aa7eec4910 | |||
| 46dd9c3ee0 | |||
| f49835d472 | |||
| 015f1c526c | |||
| ab0015ac4d | |||
| 15a6ee68ca | |||
| a43f5dd8b3 | |||
| 0cc481b7d5 | |||
| 30fe972d3a | |||
| 31c5dabcdf | |||
| 58acb0f3fa | |||
| 969e49b36b | |||
| 09abd788cf | |||
| 1ce19b9fbf | |||
| c949818173 | |||
| c1bf2af077 | |||
| c37ca54195 | |||
| 53c0934821 | |||
| 02c8fe13ec | |||
| fbcb6517cb | |||
| 68b025edde | |||
| 4e0383d799 | |||
| 090e92d53c | |||
| 45384d1645 | |||
| 007318cd79 | |||
| 7d192d8d45 | |||
| aee989c965 | |||
| f46c933c52 | |||
| 71e5981858 | |||
| 8597d5e44d | |||
| 36d343250a | |||
| 6f5e4a2f2b | |||
| 7acba6623f | |||
| 96819d7f12 | |||
| 7090284fc7 | |||
| 8c1c09b8de | |||
| 31e45c00a4 | |||
| 27c04dbcff | |||
| d2ef58240c | |||
| dc75d7c277 | |||
| fadd4baa09 | |||
| b4fde3fd59 | |||
| 44eccfe81b | |||
| 4a5ceee2ba | |||
| 28b6e45d26 | |||
| a77180f8d8 | |||
| 1e76cf888d | |||
| c7f1e7786b | |||
| c2ac891e7f | |||
| 4678f92131 | |||
| 1769182cf6 | |||
| ee4ba42fc8 | |||
| d4b671695f | |||
| 293196b0b7 | |||
| d97b95791a | |||
| e4b20c0438 | |||
| 70c81c5cda | |||
| a5d22a412b | |||
| ca085c916e | |||
| ea5ee3d65f | |||
| 76a1e542cb | |||
| da5e66316f | |||
| 988b549cb4 | |||
| 1582fea05f | |||
| 27c14f7256 | |||
| 5d8da8a8ec | |||
| b75d3b0ab3 | |||
| d357fb5f86 | |||
| ce686d2865 | |||
| a4ab556bff | |||
| 67c93ebd8b | |||
| 02630deba3 | |||
| 35d8b74bef | |||
| 1a23f13e6d | |||
| 9b8bc68f2d | |||
| 3638151430 | |||
| 52a86933a8 | |||
| 2d180700bd | |||
| 43ddce66a3 | |||
| a00ce0918c | |||
| 79abdab5bc | |||
| 39b1abf8a8 | |||
| 49e4303217 | |||
| 1f9961cc14 | |||
| b458caaad6 | |||
| c1184d9be3 | |||
| 8b19211983 | |||
| 7b3a79f820 | |||
| a681a10854 | |||
| e3ddb6f4ea | |||
| 84dfebbc6f | |||
| c8b2be8114 | |||
| 30c19b96be | |||
| a188c7c6c6 | |||
| 4dfa4385c9 | |||
| dd1b1bd4e3 | |||
| 599b98dd65 | |||
| f8930ff3fc | |||
| 7032c6e93e | |||
| f3cdba01da | |||
| 83f5c7b5a4 | |||
| a6a746d7b6 | |||
| f3d4becfe4 | |||
| 327a932237 | |||
| e854c9ea7d | |||
| 2a9b9fa2bd | |||
| f43c3fe837 | |||
| e64d7ab559 | |||
| a5012d52d0 | |||
| 301c10865c | |||
| e4570449a7 | |||
| 2dedde124c | |||
| 1a9e82bcc2 | |||
| 8778d18d47 | |||
| 854ce1a45b | |||
| 9d98f957c8 | |||
| a9bdaf4a81 | |||
| 7248aad768 | |||
| 04d4e7a379 | |||
| 6e485094a6 | |||
| ff2282d0a8 | |||
| 5e4041502c | |||
| 0ee3fb2c8e | |||
| a17172db7b | |||
| 7f500e8250 | |||
| 755518dbad | |||
| c0bd0d8f0e | |||
| 2acf7ebeda | |||
| 750f26b84d | |||
| d6e822ac16 | |||
| 48f86614ef | |||
| d225ce79d9 | |||
| 9b582aa960 | |||
| dc02b3c59b | |||
| 44d2c78207 | |||
| c31a9e530d | |||
| 6678695682 | |||
| d2ca955df2 | |||
| 35420bc133 | |||
| c9b640865c | |||
| 77f9ae41d7 | |||
| 691a7c9313 | |||
| cb4ec97df1 | |||
| a493d784ea | |||
| 47b39f510d | |||
| 2f51d42f0d | |||
| a10ee4d587 | |||
| 304ba3ff5b | |||
| 8c8c2c0fc5 | |||
| 7df977c2c1 | |||
| 64e7692815 | |||
| 8bb9701d90 | |||
| 7ee6c9b53f | |||
| 3621308b22 | |||
| 3ec701c986 | |||
| fcba8f5764 | |||
| 9cf531c3d3 | |||
| e8bcccaeb7 | |||
| cffdc93842 | |||
| 9c71b46545 | |||
| 25ae93afca | |||
| a9e8b51a01 | |||
| ca41d998be | |||
| 7baabe4170 | |||
| e24e6a0fd5 | |||
| a5300857fb | |||
| 2ee69fc08c | |||
| ca314473e5 | |||
| 83c5e2d55d | |||
| c6dee0f890 | |||
| 45630e4c42 | |||
| 443f54dbd3 | |||
| 79e4924736 | |||
| 3649e0325c | |||
| 29121521da | |||
| e3395dc7aa | |||
| dd1961fe1f | |||
| aeeab0669e | |||
| 532af89cd2 | |||
| 838134fa15 | |||
| 5ce695ee32 | |||
| 8f30f48143 | |||
| 19126b9198 | |||
| 16fe1d9c1d | |||
| 5a2c4d4090 | |||
| 1014c0c289 | |||
| 6a3873909f | |||
| 329d47f391 | |||
| 87038e44a4 | |||
| 4e1f4c0c2c | |||
| 074e1f73b7 | |||
| 8f1d9882a5 | |||
| 2039fb6242 | |||
| f10a34ede7 | |||
| 78b813b777 | |||
| 42e19a6e32 | |||
| 57f7599c2b | |||
| f3392c0db2 | |||
| 5e70015cba | |||
| 07fedfb1d5 | |||
| 41d358b9cf | |||
| ffcb4f8bcc | |||
| d8f2ccb733 | |||
| f7a4128bcc | |||
| 5e20ef08d4 | |||
| 919aae7108 | |||
| ca3c31f6a1 | |||
| 8c23ce06d4 | |||
| 15c1878f5e | |||
| 28ec3e0f75 | |||
| e46cc1ba19 | |||
| 1f4d809c30 | |||
| 4969eaf016 | |||
| 64919665db | |||
| 5aea00e492 | |||
| 1d2fdd3f27 | |||
| fba6d319ea | |||
| 05cece3214 | |||
| 2aed66b24c | |||
| 5d8ba1c980 | |||
| 4b9e20dce6 | |||
| a0eed53b27 | |||
| d0108236d9 | |||
| 0c5eb0720c | |||
| 1589df2d0d | |||
| 6e0ce1d5af | |||
| c2baf6f750 | |||
| 4ac1e9ec6c | |||
| 547bd96218 | |||
| aa281635f2 | |||
| e996f3e63d | |||
| 50c70f96dd | |||
| fec9aa5697 | |||
| a771a783d1 | |||
| 7f25cd87ef | |||
| 7ac843aacd | |||
| 285bdae154 | |||
| 198ba2e2b1 | |||
| 4b32f3c013 | |||
| 20b15adc57 | |||
| 9cae4a2572 | |||
| af1e659336 | |||
| 150ac54eee | |||
| 78b481718d | |||
| bf2552e76d | |||
| d9339df886 | |||
| c98c90ea75 | |||
| f4393e5bf4 | |||
| 76fd698cd8 | |||
| f8c607f3f7 | |||
| 568450afb9 | |||
| 66cb8c41a8 | |||
| 5539ae33f8 | |||
| 1500ff3e70 | |||
| 13505859a3 | |||
| 661955fae8 | |||
| 9779c9c4f6 | |||
| ad624a109f | |||
| e8f0230224 | |||
| 55631ad9cb | |||
| a97db08155 | |||
| 3a2bb63dc2 | |||
| 6e809dc7e7 | |||
| 40ea7cb4a0 | |||
| 11d2407a8a | |||
| 225583816b | |||
| b113022dd0 | |||
| caed2fde28 | |||
| 65c90b368c | |||
| 081de57156 | |||
| f808f05487 | |||
| 143492fa92 | |||
| 56f69b29b1 | |||
| 8e824d1472 | |||
| e6e36117da | |||
| fa91dead87 | |||
| 1b2a1a8608 | |||
| 5e5923eed4 | |||
| cd2b8ea1c9 | |||
| abebbe2b62 | |||
| 2c13d7ab92 | |||
| 4a60b7953a | |||
| efbb64608b | |||
| 01a7e47181 | |||
| 9b21ef693a | |||
| 9cb4e905a2 | |||
| 047cc6723d | |||
| 5d1f575f55 | |||
| 2b05d7d95a | |||
| fe27c2e2c6 | |||
| 66063876ed | |||
| f9c08c910b | |||
| 6b117e3479 | |||
| 8361f69004 | |||
| d75bcef324 | |||
| 8012e35128 | |||
| 354102a2b4 | |||
| 50353a4055 | |||
| 6fabfd6e4a | |||
| ae193505ce | |||
| 06457ce879 | |||
| e7b97b6f12 | |||
| ff2d12392c | |||
| 19f1e725c5 | |||
| cd24d8b496 | |||
| a11415a976 | |||
| 19277ce19e | |||
| 61bac1d0f0 | |||
| 3239fc6a81 | |||
| 765f648aa0 | |||
| ac88ddfbb7 | |||
| 91a20d03db | |||
| 25d5dfef07 | |||
| 9bdcac4a46 | |||
| d3df44d7f2 | |||
| 11c976fc76 | |||
| b94b4e4f05 | |||
| 1b7d7b4b13 | |||
| 2b5a331b20 | |||
| 363718a9af | |||
| 577b0d709b | |||
| a1fdf2c87f | |||
| 53c65eafca | |||
| c942363301 | |||
| 7e8b2f8721 | |||
| c9b6956265 | |||
| 49ffafddc6 | |||
| 106a5bb3a3 | |||
| 04f8571979 | |||
| 9ca714e01d | |||
| 6a2f7042c1 | |||
| 1f2861de71 | |||
| f4c61e2465 | |||
| d54cff97b6 | |||
| ddfcf0927d | |||
| b03fc2b053 | |||
| 0afad0fb8a | |||
| bb142f335c | |||
| ad7eebdf94 | |||
| 6593efdc69 | |||
| 7e79891403 | |||
| 0a34b0b15f | |||
| 6d01afb2d4 | |||
| 1165a66a09 | |||
| 9957908b7e | |||
| 573b6fac23 | |||
| b4aa6bfb20 | |||
| 4e95ebc73d | |||
| 9575039bae | |||
| a7ee3bb8c3 | |||
| 1f7752c974 | |||
| 47c64d9a93 | |||
| a042620459 | |||
| 77e2e42d10 | |||
| 779ed5577e | |||
| 08480789cd | |||
| d11b592d42 | |||
| 3fea449d4e | |||
| b256c0cf17 | |||
| df471eca9b | |||
| b43eee6e45 | |||
| 169c53fa83 | |||
| c821fa7fb4 | |||
| 9674388efa | |||
| 275dba5723 | |||
| cc367df19c | |||
| 3a65be0d90 | |||
| e1ab2ccdda | |||
| 8a0f494bdd | |||
| d8ec74ac1f | |||
| c38c720a52 | |||
| f498a7bb60 | |||
| 73f5010d5b | |||
| 0f80e44136 | |||
| 48e08c4277 | |||
| 5206941e23 | |||
| 0797d671c5 | |||
| 5fe21a5cb6 | |||
| 0efcce3f25 | |||
| 12964551ef | |||
| bf239499ce | |||
| c21042fe4a | |||
| 96cfe9457c | |||
| ec4b797da7 | |||
| 714b2bce84 | |||
| 20dcd88b9d | |||
| c52492ed71 | |||
| 4844ef4800 | |||
| e12e9574c9 | |||
| d3ab5a341f | |||
| 30c78cd379 | |||
| 92135102fa | |||
| 5e8bff44c2 | |||
| fc89d485c5 | |||
| 771efaa441 | |||
| 78b7680ac5 | |||
| 6836a993a6 | |||
| 6030f8a4b4 | |||
| a7f5003eea | |||
| bc51391b7b | |||
| 9a746b451d | |||
| 2145ebf682 | |||
| f2be9b1fca | |||
| e47b3f1abc | |||
| a33099e805 | |||
| d32f4937f9 | |||
| 073ea143de | |||
| f025b61dd8 | |||
| 7b5f304fd3 | |||
| b24238bfe5 | |||
| b4abd4046d | |||
| 20b94c28c2 | |||
| d90c44d997 | |||
| cc01e4d708 | |||
| 03590ee840 | |||
| a61958d2a3 | |||
| 0711a83bea | |||
| 66d91ca00a | |||
| 066b8c0eda | |||
| d3254c6fd3 | |||
| 75620b2452 | |||
| 911d9415e1 | |||
| cfb687c227 | |||
| 8936917311 | |||
| 39b3f7c511 | |||
| dd9bf6f298 | |||
| ecc024932f | |||
| fd2f8d0ce6 | |||
| 3c10799db7 | |||
| 60d8a7042a | |||
| 45c8034d9e | |||
| 44e5571ae1 | |||
| 3e7a4aad11 | |||
| f1dfa10883 | |||
| 7f0bb838fc | |||
| ec1ee19f46 | |||
| 22e3930eb9 | |||
| e423af99ce | |||
| 8b35358458 | |||
| d3acb2c790 | |||
| bd6df5248b | |||
| 2d83a14bf5 | |||
| 9922131572 | |||
| 986f8ee91a | |||
| 56eaa2c05f | |||
| 7867528196 | |||
| 68d9188671 | |||
| 97edbd528c | |||
| a0bf862e40 | |||
| 39a21a7a69 | |||
| 43c17896c5 | |||
| fc48734fa6 | |||
| 1e9b52e49c | |||
| 70a98421d5 | |||
| 39c999123e | |||
| 0399c18ef4 | |||
| d1d8deccbf | |||
| 5e6aea62bf | |||
| 64eccfdc03 | |||
| 52f7cb24a6 | |||
| d9dd4f1f76 | |||
| bca9876624 | |||
| 164f11e1ac | |||
| a883ad8142 | |||
| 3c03bdd7df | |||
| 1fa954736d | |||
| 68beeea12c | |||
| ea4a0a62da | |||
| b6ff0db8bc | |||
| b739cc5eb2 | |||
| e4a3ba349d | |||
| a4558e3c86 | |||
| 93a0e2c82f | |||
| 338bfae25f | |||
| 47a3c99968 | |||
| 48a4a3650b | |||
| a1ec3cb229 | |||
| 347e872043 | |||
| 2f5d11f500 | |||
| b347041e26 | |||
| f784c13812 | |||
| abbd5256cf | |||
| d211c42050 | |||
| 2f569c1226 | |||
| e3f3327e12 | |||
| 5c853c876f | |||
| 2a469611ff | |||
| dbffed7b5f | |||
| 26eaface98 | |||
| 6e5a08d3ed | |||
| e8e6726014 | |||
| db13bc5c68 | |||
| 099671eedc | |||
| dec11d9272 | |||
| 221608e9ec | |||
| fb25c51e9b | |||
| 01fb2e83b2 | |||
| 11860f2719 | |||
| 848d43e2cd |
89
ESPR-Evaluation/1-Current-Evidence.md
Normal file
|
|
@ -0,0 +1,89 @@
|
||||||
|
# On an RCT for ESPR.
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
> There is a certain valuable way of thinking, which is not yet taught in schools, in this present day. This certain way of thinking is not taught systematically at all. It is just absorbed by people who grow up reading books like Surely You’re Joking, Mr. Feynman or who have an unusually great teacher in high school.
|
||||||
|
>
|
||||||
|
> Most famously, this certain way of thinking has to do with science, and with the experimental method. The part of science where you go out and look at the universe instead of just making things up. The part where you say “Oops” and give up on a bad theory when the experiments don’t support it.
|
||||||
|
>
|
||||||
|
> But this certain way of thinking extends beyond that. It is deeper and more universal than a pair of goggles you put on when you enter a laboratory and take off when you leave. It applies to daily life, though this part is subtler and more difficult. But if you can’t say “Oops” and give up when it looks like something isn’t working, you have no choice but to keep shooting yourself in the foot. You have to keep reloading the shotgun and you have to keep pulling the trigger. You know people like this. And somewhere, someplace in your life you’d rather not think about, you are people like this. It would be nice if there was a certain way of thinking that could help us stop doing that.
|
||||||
|
|
||||||
|
\- Eliezer Yudkowsky, https://www.lesswrong.com/rationality/preface
|
||||||
|
|
||||||
|
## The evidence on CFAR's workshops.
|
||||||
|
|
||||||
|
The evidence for/against CFAR in general is of interest here, because I take it as likely that it is very much correlated with the evidence on ESPR. For example, if reading programs in India show that dividing students by initial level improves their learning outcome, then you'd expect similar processes to be at play in Kenya. Thus, if the evidence on CFAR were robust, we might be able to afford being less rigorous when it comes to ESPR.
|
||||||
|
|
||||||
|
I've mainly studied [CFAR's 2015 Longitudinal Study](http://www.rationality.org/studies/2015-longitudinal-study) together with the more recent [Case Studies](http://rationality.org/studies/2016-case-studies) and the [2017 CFAR Impact report](http://www.rationality.org/resources/updates/2017/cfar-2017-impact-report). Here, I will make some comments about them, but will not review their findings.
|
||||||
|
|
||||||
|
The first study notes that a control group would be a difficult thing to implement, noting it would require finding people who would like to come to the program and forbidding them to do so. The study tries to compensate for the lack of a control by being statistically clever. This study seems to be as rigorous as you can get without a RCT.
|
||||||
|
|
||||||
|
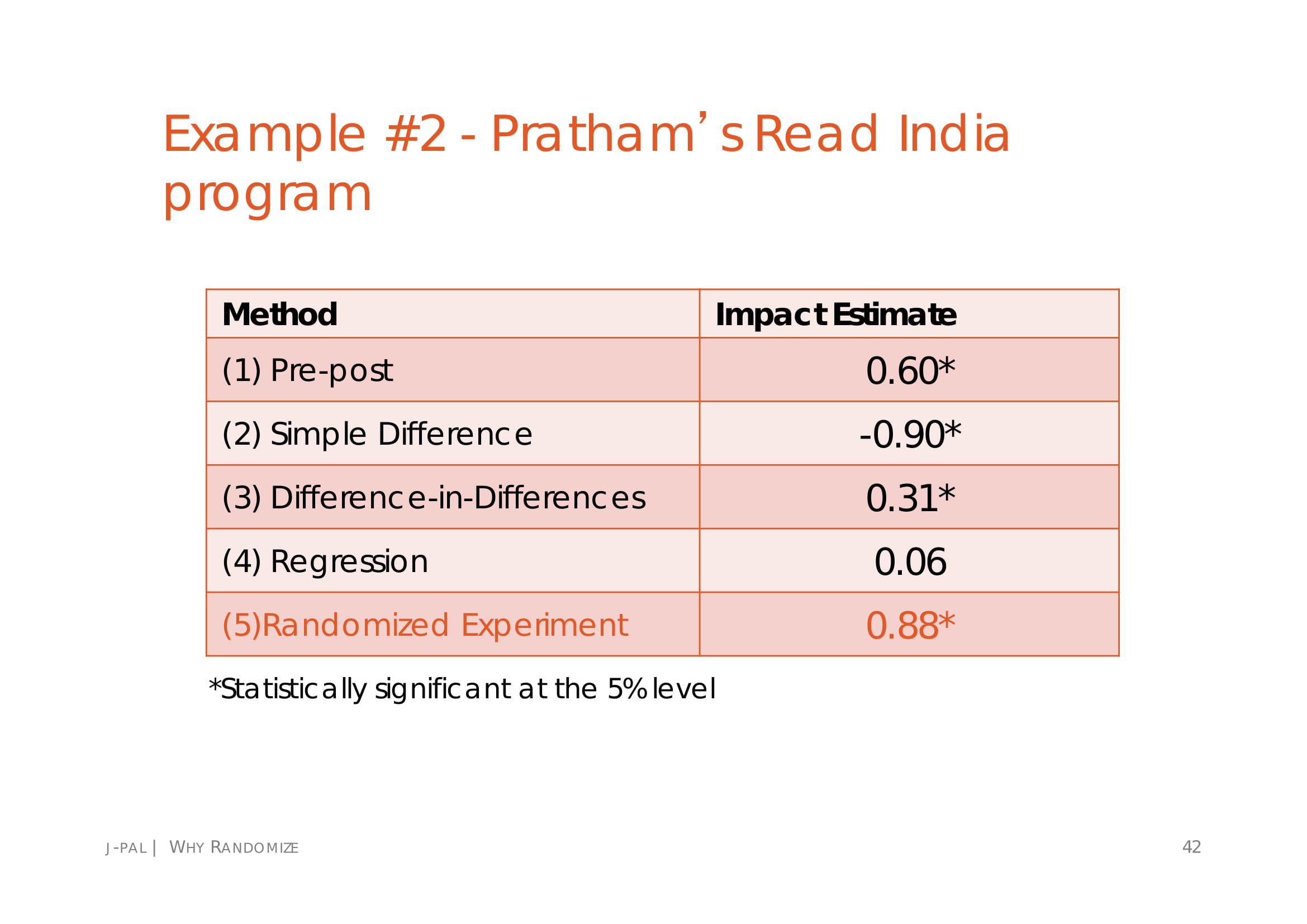
But I feel like that is only partially sufficient. The magnitude of the effect found could be wildly overestimated; MIT's Abdul Latif Jameel Poverty Action Lab provides the following slides [1]:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
I find them scary; depending on the method used to test your effect, you can get an effect size that is 4-5 times as great as the effect you find with an RCT, or about as great, in the other direction. The effects the CFAR study finds, f.ex. the one most prominently displayed in CFAR's webpage, an increased life satisfaction of 0.17 standard deviations (i.e., going from 50 to 56.75%) are small enough for me to worry about such inconveniences.
|
||||||
|
|
||||||
|
Thus, I feel that an RCT could be delayed on the strength of the evidence that CFAR currently has, including its logical model (see below), but not indefinitely. In particular, if CFAR had plans for more ambitious expansion, it would be a good idea to run an RCT before. If MIT's JPAL, didn't specialize on poverty interventions, I would suggest teaming up with them, and it seems like a good idea to try anyways. JPAL would provide strategies like the following: we can randomly admit people for either this year or the next, and take as the control the group which has been left waiting. It is not clear to me why this hasn't been done yet.
|
||||||
|
|
||||||
|
With regards to the second and third documents, I feel that they provide powerful intuitions for why CFAR's logical model is not totally bullshit. This would be something like: CFAR students are taught rationality techniques + have an environment in which they can question their current decisions and consider potentially better choices = they go on to do more good in the world, f.ex. by switching careers. From the Case Studies mentioned above:
|
||||||
|
|
||||||
|
> Eric (Bruylant) described the mindset of people at CFAR as “the exact opposite of learned helplessness”, and found that experiencing more of this mindset, in combination with an increased ability to see what was going on with his mind, was particularly helpful for making this shift.
|
||||||
|
|
||||||
|
Yet William MacAskill's book, *Doing Good Better*, is full with examples of NGOs with great sounding premises, e.g., Roundabout Water Solutions, which were woefully uneffective. Note that Arbital, one of CFAR's success stories, has now failed. Additionally, when reading CFAR's own [Rationality Checklist](http://www.rationality.org/resources/rationality-checklist), I notice that to acquire the mental movements mentioned seems more like a long term project, and less like a skill acquirable in 4 days. This is something which CFAR itself also underscores.
|
||||||
|
|
||||||
|
Furthermore, asking alumni to estimate the impact does not seem at all like a good idea to estimate impact, particularly when these people are sympathetic to CFAR, i.e., . To get a better idea of why, take the outside view and substitute CFAR for Center for Non Violent Communication: CNVC.
|
||||||
|
|
||||||
|
[1]: Obtained from MIT's course *Evaluating Social Programs* (Week 3), accessible at https://courses.edx.org/courses/course-v1:MITx+JPAL101x+2T2018/course/.
|
||||||
|
|
||||||
|
## Outside view: The evidence on Non Violent Communication (NVC).
|
||||||
|
|
||||||
|
The [Center for NonViolent Communication](https://www.cnvc.org/about-us/projects/nvc-research) provides a list of all the research about NVC known to them, of which Juncadella \([2016](https://www.cnvc.org/sites/default/files/NVC_Research_Files/Carme_Mampel_Juncadella.pdf)\) provides an overview up to 2013, after which not much else has been undertaken. From this review: *"Eleven of the 13 studies used quantitative desings. Seven used a control group and 4 a pre-post testing comparison. Of the 7 studies that used a control group, none used a random assignation of participants. In five, the treatment and control were assigned by researcher action and criteria, and in two, the assignment protocol is not reported"*.
|
||||||
|
|
||||||
|
The main problems the research presents is that it is a little bit chaotic: although Steckal, (1994) provides a measuring instrument whose consistency seems to have been validated, every researcher seems to use their own instruments, and investigate an slightly different question, i.e., for different demographics, in different settings, with different workshop lengths. All in all, there seems to be a positive effect, but its value is very uncertain.
|
||||||
|
|
||||||
|
NVC is also supported by testimonial evidence that is both extremely copious and extremely effusive, to be found in Marshall Rosenberg's book *Non Violent Communication: A Language of Life*, and in their webpage. Additionally, the logical model also appears consistent and robust: by providing a way to connect with our emotions and needs, and those of others, NVC workshops provide participants with the skills necessary to relate with others, reduce tension, etc. At any point
|
||||||
|
|
||||||
|
Given the above, what probability do I assign to NVC being full of bullshit? i.e., that the \~$3,000 courses it offers are only more expensive, not significantly more effective than the $15 book? Actually quite high. NVC seems to have a certain disdain of practical solutions: f.e.x, in Q4 from the measure developed by Steckal "When I listen to another in a caring way, I like to analyze or interpret their problems", an affirmative answer is scored negatively.
|
||||||
|
|
||||||
|
Sense of community. Prediction Spain. Scrap whole section?
|
||||||
|
|
||||||
|
## ESPR as distinct from CFAR.
|
||||||
|
|
||||||
|
It must be noted that ESPR gets little love from the main organization, being mainly run by volunteers, with some instructors coming in to give classes. Eventually, it might make sense to institute espr as a different organization with a focus on Europe instead of as an American side project.
|
||||||
|
|
||||||
|
## ESPR's Logical model.
|
||||||
|
I think that the logical model underpinning ESPR is fundamentally solid, i.e., as solid as CFAR's, given that it's pretty solid. In the words of a student which came back this year as a Junior Counselor:
|
||||||
|
|
||||||
|
> [Teaches] ESPR smart people not to make stupid mistakes. Examples: betting, prediction markets decrease overconfidence. Units of exchange class decreases likelihood of spending time, money, other currency in counterproductive ways. The whole asking for examples thing prevents people from hiding behind abstract terms and to pretend to understand something when they don't. Some of this is learned in classes. A lot of good techniques from just interacting with people at espr.
|
||||||
|
>
|
||||||
|
> I've had conversations with otherwise really smart people and thought “you wouldn't be stuck with those beliefs if you'd gone though two weeks of espr”
|
||||||
|
>
|
||||||
|
> ESPR also increases self-awareness. A lot of espr classes / techniques / culture involves noticing things that happen in your head. This is good for avoiding stupid mistakes and also for getting better at accomplishing things.
|
||||||
|
>
|
||||||
|
> It is nice to be surrounded by very smart. ambitious people. This might be less relevant for people who do competitions like IMO or go to very selective universities. Personally, it is a fucking awesome and rare experience every time I meet someone really smart with a bearable personality in the real world. Being around lots of those people at espr was awesome. Espr might have made a lot of participants consider options they wouldn't seriously have before talking to the instructors like founding a startup, working on ai alignment, everything that galit talked about etc
|
||||||
|
>
|
||||||
|
> espr also increased positive impact participants will have on the world in the future by introducing them to effective altruism ideas. I think last year’s batch would have been affected more by this because I remember there being more on x-risk and prioritizing causes and stuff [1].
|
||||||
|
|
||||||
|
> I spent 15 mins
|
||||||
|
> =)
|
||||||
|
|
||||||
|
Additionally, ESPR gives some of it's alumni the opportunity to come back as Junior Counselors, which take on a possition of some responsibility, and keep improving their own rationality skills.
|
||||||
|
|
||||||
|
[1]. This year, being in Edimburgh, we didn't bring in an FHI person to give a talk. We did have an AI risk panel, and ea/x-risk were important (~10%) focus of conversations. However, I will make a note to bring someone from the FHI next year. We also continued grappling with the boundaries between presenting an important problem and indoctrinating and mindfucking impressionable young persons.
|
||||||
|
|
||||||
|
## Perverse incentives
|
||||||
|
|
||||||
|
As with CFAR's, I think that alumni profiles in the following section provide useful intuitions. However, while perhaps narratively compelling, there is no control group, which is supremely shitty. **These profiles may not allow us to falsify any hypothesis**, i.e., to meaningfully change our priors, because these students come from a pool of incredibly bright applicants. The evidence is weak in that with the current evidence, I would feel uncomfortable saying that ESPR should be scaled up.
|
||||||
|
|
||||||
|
To the extent that OpenPhilantropy prefers these and other weak forms of evidence *now*, rather than stronger evidence two-three years later, OpenPhilantropy might be giving ESPR perverse incentives. Note that with 20-30 students per year, even after we start an RCT, there must pass a number of years before we can amass some meaningful statistical power (see the power calculations). On the other hand, taking a process of iterated improvement as an admission of failure would also be pretty shitty.
|
||||||
|
|
||||||
|
The questions designing a RCT poses are hard, but the bigger problem is that there's an incentive to not ask them at all. But that would be agaist CFAR's ethos, as outlined in the introduction.
|
||||||
|
|
||||||
|
## Alternatives to espr: The cheapest option.
|
||||||
|
One question which interests me is: what is the cheapest version of the program which is still cost effective? What happens if you just record the classes, send them to bright people, and answer their questions? What if you set up a course on edx? Interventions based on universities and highschools are likely to be much cheaper, given that neither board nor flight, nor classrooms would have to be paid for. Is there a low-cost, scalable approach?
|
||||||
|
|
||||||
|
I'm told that some of the cfar instructors have strong intuitions that in-person teaching is much more effective, based on their own experience and perhaps also on a 2012 small rct, which is either unpublished or unfindable.
|
||||||
|
|
||||||
|
Still, I want to test this assumption, because, almost by definition, to do so would be pretty cheap. As a plus, we can take the population who takes the cheaper course to be a second control group.
|
||||||
180
ESPR-Evaluation/3-Power-calculations.md
Normal file
|
|
@ -0,0 +1,180 @@
|
||||||
|
# Power calculations
|
||||||
|
|
||||||
|
Using R we will do some power calculations
|
||||||
|
Necessary library pwr, loads with library(pwr)
|
||||||
|
Necessary function: pwr.t2n.test
|
||||||
|
See: https://www.statmethods.net/stats/power.html
|
||||||
|
|
||||||
|
Optimistic: We reach everyone
|
||||||
|
Pessimistic: We reach 66% of treatment and control group.
|
||||||
|
|
||||||
|
## Year 1, pessimistic projections
|
||||||
|
ith n-treatment=20, n-control = 20, power = 0.9,sig.level= 0.05, power = 0.9, minimal detectable effect in standard deviations (d) = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 20
|
||||||
|
n2 = 20
|
||||||
|
d = 1.051997
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
## Year 1, optimistic projections
|
||||||
|
With n_treatment=30, n_control = 60, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 30
|
||||||
|
n2 = 60
|
||||||
|
d = 0.7328756
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
With n = ?, power = 0.9,sig.level= 0.05, power = 0.9, minimal detectable effect = 0.5
|
||||||
|
|
||||||
|
Two-sample t test power calculation
|
||||||
|
|
||||||
|
n = 85.03128
|
||||||
|
d = 0.5
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
NOTE: n is number in *each* group
|
||||||
|
|
||||||
|
|
||||||
|
## Year 2, pessimistic projections
|
||||||
|
With n_treatment=40, n_control = 40, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 40
|
||||||
|
n2 = 40
|
||||||
|
d = 0.7339255
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
## Year 2, optimistic projections
|
||||||
|
With n_treatment=60, n_control = 120, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 60
|
||||||
|
n2 = 120
|
||||||
|
d = 0.5153056
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
|
||||||
|
## Year 3, pessimistic projections
|
||||||
|
With n_treatment=60, n_control = 60, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 60
|
||||||
|
n2 = 60
|
||||||
|
d = 0.5967207
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
## Year 3, optimistic projections
|
||||||
|
With n_treatment=90, n_control = 180, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 90
|
||||||
|
n2 = 180
|
||||||
|
d = 0.4200132
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
## Year 4, pessimistic projections
|
||||||
|
With n_treatment=80, n_control = 80, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 80
|
||||||
|
n2 = 80
|
||||||
|
d = 0.5156619
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
## Year 4, optimistic projections
|
||||||
|
With n_treatment=120, n_control = 240, power = 0.9,sig.level= 0.05, minimal detectable effect = ?
|
||||||
|
|
||||||
|
t test power calculation
|
||||||
|
|
||||||
|
n1 = 120
|
||||||
|
n2 = 240
|
||||||
|
d = 0.3633959
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
## Population necessary to detect an effect size of 0.2 with significance level = 0.05 and power = 0.9
|
||||||
|
|
||||||
|
Here the free variable was d= minimal detectable effect
|
||||||
|
With n = ?, power = 0.9,sig.level= 0.05, power = 0.9, minimal detectable effect = 0.2
|
||||||
|
|
||||||
|
Two-sample t test power calculation
|
||||||
|
|
||||||
|
n = 526.3332
|
||||||
|
d = 0.2
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
NOTE: n is number in *each* group
|
||||||
|
|
||||||
|
here the free variable was n, the population of the treatment group
|
||||||
|
son = population of the treatmente group = population of the control group
|
||||||
|
necessary to detect an effect of 0.2
|
||||||
|
|
||||||
|
## Population necessary to detect an effect size of 0.5 with significance level = 0.05 and power = 0.9
|
||||||
|
|
||||||
|
Two-sample t test power calculation
|
||||||
|
|
||||||
|
n = 85.03128
|
||||||
|
d = 0.5
|
||||||
|
sig.level = 0.05
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
NOTE: n is number in *each* group
|
||||||
|
|
||||||
|
## Population necessary to detect an effect size of 0.2 with significance level = 0.10 and power = 0.9
|
||||||
|
|
||||||
|
Two-sample t test power calculation
|
||||||
|
|
||||||
|
n = 428.8664
|
||||||
|
d = 0.2
|
||||||
|
sig.level = 0.1
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
NOTE: n is number in *each* group
|
||||||
|
|
||||||
|
|
||||||
|
## Population necessary to detect an effect size of 0.5 with significance level = 0.10 and power = 0.9
|
||||||
|
|
||||||
|
Two-sample t test power calculation
|
||||||
|
|
||||||
|
n = 69.19719
|
||||||
|
d = 0.5
|
||||||
|
sig.level = 0.1
|
||||||
|
power = 0.9
|
||||||
|
alternative = two.sided
|
||||||
|
|
||||||
|
NOTE: n is number in *each* group
|
||||||
|
|
||||||
|
|
||||||
|
## Conclusions.
|
||||||
|
Even after 4 years, under the most optimistic population projections (i.e., every participant answers our surveys every year, and 60 students who didn't get selected also do), we wouldn't have enough power to detect an effect size of 0.2 standard deviations with significance level = 0.05. However, it seems feasible to detect the kinds of effects which would justify the upward of $150.000 / year costs of ESPR within 3 years. The minimum effect which justifies the costs of ESPR should be determined beforehand, as should the axis along which we measure. I would also suggest to expand the RCT to SPARC once its feasibility has been tested at ESPR.
|
||||||
|
|
||||||
212
ESPR-Evaluation/4-Measurements.md
Normal file
|
|
@ -0,0 +1,212 @@
|
||||||
|
# Measurements
|
||||||
|
|
||||||
|
Note: This is a work in progress. The end result would be to create a several survey such as [this](https://docs.google.com/forms/d/1RRKImKZKePSvdWu6aj2zOngSa9PJMfcSH9eCxy3XdfQ/viewform?edit_requested=true), to be taken before the camp, x months after the camp and 2 years after the camp.
|
||||||
|
|
||||||
|
## Difficulties
|
||||||
|
|
||||||
|
The changes which through ESPR could be induced in the students are, in some sense, fuzzy and soft. There is some tension between measuring what is easiest to measure and measuring what we're actually interested in, and we firmly choose the second kind. For example, when measuring openness, we don't care about questions such as:
|
||||||
|
|
||||||
|
I see Myself as Someone Who...
|
||||||
|
- Is original, comes up with new ideas
|
||||||
|
- Is curious about many different things
|
||||||
|
- Is ingenious, a deep thinker
|
||||||
|
- Has an active imagination
|
||||||
|
- Is inventive
|
||||||
|
- Values artistic, aesthetic experiences
|
||||||
|
- Prefers work that is routine
|
||||||
|
- Likes to reflect, play with ideas
|
||||||
|
- Has few artistic interests
|
||||||
|
- Is sophisticated in art, music, or literature
|
||||||
|
|
||||||
|
From John, O. P., & Srivastava, S. (1999). The Big-Five trait taxonomy: History, measurement, and theoretical perspectives. In L. A. Pervin & O. P. John (Eds.), *Handbook of personality: Theory and research* (Vol. 2, pp. 102–138). New York: Guilford Press.
|
||||||
|
|
||||||
|
But instead want to ask things such as:
|
||||||
|
- What was the last time you tried out something new?
|
||||||
|
- How often do you try something new?
|
||||||
|
- How much have you explored vs specialized in the last year?
|
||||||
|
- What was the last time you did something which you thought had a <=5% chance of succeeding?
|
||||||
|
|
||||||
|
Note that the 2015 CFAR Longitudinal study takes a different approach:
|
||||||
|
> "We relied heavily on existing measures which have been validated and used by psychology researchers, especially in the areas of well-being and personality. These measures typically are not a perfect match for what we care about, but we expected them to be sufficiently correlated with what we care about for them to be worth using"
|
||||||
|
|
||||||
|
For example, they used the questions written above, but they'd be insufficient to capture the effects of CoZE, one of the highest impact activities in a CFAR Workshop.
|
||||||
|
|
||||||
|
## Things we want to measure.
|
||||||
|
**- and ways to measure them.**
|
||||||
|
|
||||||
|
Recommend a song which lasts roughly as long as it should take to complete the survey.
|
||||||
|
|
||||||
|
Every time you lie or exaggerate, a kitten dies. By answering this survey, you help make the world a better place.
|
||||||
|
|
||||||
|
If you find yourself fatigued by the length of the survey feel free to take a break and come back. It is also preferable to just go to the end and turn in what you have. Some questions are
|
||||||
|
explicitly marked 'bonus' or 'optional' meaning they are especially skippable.
|
||||||
|
|
||||||
|
1. Demographic information:
|
||||||
|
Ask for consent for aggregation / doing a study on this. ✓
|
||||||
|
Can we include your survey data in a public dataset? ✓
|
||||||
|
Ask for the email. Followup survey. ✓
|
||||||
|
Ikea: birthdate: dd.mm.yyyy + initials + first letter of the country you were born with.
|
||||||
|
Age / Sex assigned at birth / Gender / Country (if many, the one you most identify with) / Ethnic group (most identify) / sexual orientation ✓
|
||||||
|
|
||||||
|
1. Choices influenced by espr.
|
||||||
|
- Average prestigiousness of the universities to which the apply / to which they get in.
|
||||||
|
- % people who are not going to university.
|
||||||
|
- Do you feel like you've made a life-changing choice in the last year?
|
||||||
|
If you have: Write a brief tweet.
|
||||||
|
- Do you feel like your life has significantly changed in the last year?
|
||||||
|
If you have: Write a brief tweet.
|
||||||
|
- Do you feel like the course of your life has significantly changed in the last year?
|
||||||
|
If you have: Write a brief tweet.
|
||||||
|
|
||||||
|
1. Self-Confidence/ Modern Survival Skills.
|
||||||
|
- I think I could do pretty well in a Zombie Apocalypse. ✓
|
||||||
|
- It wouldn't bother me excessively if I woke up in a random city in the world with nothing but my clothes on. ✓
|
||||||
|
|
||||||
|
1. Decisiveness.
|
||||||
|
- To what extent do you agree with the statement: I am a decisive person.
|
||||||
|
- To what extent would your friends agree with the statement: You are a decisive person.
|
||||||
|
- What was the last time you did something which you thought had <=5% of succeeding? Why did you attempt it? Also, describe it. ✓
|
||||||
|
- To what extent do you struggle with doing things you've decided to do? ✓
|
||||||
|
|
||||||
|
1. Openess to new experiences?
|
||||||
|
- What was the last time you tried out something new? ✓
|
||||||
|
- How often do you try something new?
|
||||||
|
|
||||||
|
1. People, connections.
|
||||||
|
- What is the approximate number of people who you interacted with in the past week? ✓
|
||||||
|
- What is the approximate number of people you'd be willing to confide in about something personal? ✓
|
||||||
|
- What is the approximate number of people who would let you crash at their place if you needed somewhere to stay? ✓
|
||||||
|
Their numerical responses were then capped at 300, log transformed, and averaged into a single measure of social support.
|
||||||
|
|
||||||
|
1. Attitudes towards EA.
|
||||||
|
There is no right or wrong answers. Our philosophical positions are very diverse, and even include nietzschean philosophy.
|
||||||
|
- Do you know what Effective Altruism is
|
||||||
|
- Yes / No but I've heard of it / No.✓
|
||||||
|
- Do you self-identify as an Effective Altruist?✓
|
||||||
|
- Has Effective Altruism caused you to make donations you otherwise wouldn't?✓
|
||||||
|
- Do you expect Effective Altruism to cause you to make donations in the future which you otherwise won't?✓
|
||||||
|
- If that is the case, what % of your earnings do you expect to donate to ea charities (like Against Malaria Foundation, Malaria Consortium, Schistosomiasis Control Initiative, Evidence Action's Deworm the World Initiative, GiveWell, 80.000 hours, etc) over your life?
|
||||||
|
- Ask this privately
|
||||||
|
- What's your overall opinion of Effective Altruism? ✓
|
||||||
|
- If you had to distribute 1 billion dollars to different charities, on the basis of which criteria would you do it?
|
||||||
|
|
||||||
|
1. Attitudes towards existential risk.
|
||||||
|
- Are you familiar with the term "existential risk"?
|
||||||
|
- Without searching the internet, looking at Wikipedia, etc., how would you describe the concept in a short tweet?
|
||||||
|
- If you had heard about it, how much of a threat do you think it poses?
|
||||||
|
- In percentage points, how likely do you judge it that your career will in some way be related to existential risk? And directly related?
|
||||||
|
|
||||||
|
1. Attitudes towards AI Safety
|
||||||
|
- Are you familiar with the field of AI Safety?
|
||||||
|
- Have you read any papers related to the field?
|
||||||
|
- If you knew about it beforehand, how much of a threat do you think it poses?
|
||||||
|
- How would you describe the concept in a short tweet? ✓
|
||||||
|
- In percentage points, how likely do you judge it that your career will in some way be related to AI Safety? And directly related? ✓
|
||||||
|
|
||||||
|
|
||||||
|
**Sofware upgrade**
|
||||||
|
|
||||||
|
1. Introspective power. Internal Design. Habits.
|
||||||
|
- I undestand myself ✓
|
||||||
|
- I have fiddled with the different parts of myself.
|
||||||
|
- I work to change the parts of myself which I don't like. ✓
|
||||||
|
- I purposefully create habits. ✓
|
||||||
|
- When was the last time you did this? ✓
|
||||||
|
|
||||||
|
1. Position towards emotions.
|
||||||
|
- Emotions as your allies. ✓
|
||||||
|
- To what extent do you agree with the following:
|
||||||
|
- Emotions are my allies, ✓
|
||||||
|
- Emotions often give me useful information. ✓
|
||||||
|
- Emotions often hinder me, ✓
|
||||||
|
- I would prefer to feel less. ✓
|
||||||
|
- I often ignore my emotions. ✓
|
||||||
|
- I am in touch with my emotions. ✓
|
||||||
|
|
||||||
|
1. Life optimization
|
||||||
|
- I have in place mechanisms for constant, iterated improvement of my life.✓
|
||||||
|
- Write a short tweet about it.
|
||||||
|
- Units of exchange: I often explicitly consider the tradeoffs between money, time, prestige, etc., when making decisions.
|
||||||
|
- When was the last time you've done that (if ever)
|
||||||
|
- Write a short tweet about it.
|
||||||
|
- Think about your current set of skills, your habits, the things you spend your time on, how you interact with other people, the intellectual questions that you find engaging, the goals you’re aiming towards, and the challenges that you’re currently facing going forward. Next, think about how you were one year ago on each of these dimensions. How different are you now from how you were one year ago?
|
||||||
|
- Not at all different / Slightly different / Somewhat different / Very different / Extremely different. ✓
|
||||||
|
- [optional] In about one tweet, what is one difference that stands out as being particularly large or significant? ✓
|
||||||
|
- Can you think of any changes that you’ve made in the past month to your daily routines or habits in order to make things go better? These can be tiny changes (e.g., adjusted the curtains on my bedroom window so that less light comes in while I’m sleeping) or large ones. Spend about 60 seconds recalling as many examples of these kinds of changes as you can and listing them here. (If you want to skip this question, leave it blank. If you spend the 60 seconds and no specific examples come to mind, write "none.") ✓
|
||||||
|
-
|
||||||
|
|
||||||
|
1. Mental illness.
|
||||||
|
I actually don't care about the "Post-espr depression".
|
||||||
|
While having a mental illness sucks, there is no right or wrong answer. Some of the best people I know face depression, aspergers, etc.
|
||||||
|
- Have you been diagnosed with a mental illness?
|
||||||
|
- Do you think you have a mental illness?
|
||||||
|
- If so, which?
|
||||||
|
|
||||||
|
1. Goal clarity
|
||||||
|
With regards to my goals,
|
||||||
|
- I know what my goals are. ✓
|
||||||
|
- I feel that different parts of myself are aligned. ✓
|
||||||
|
- I feel that the different parts of myself are more aligned than 1y ago. ✓
|
||||||
|
- when an internal conflict arises, I have adequate tools to resolve it. ✓
|
||||||
|
|N: I copied the first person from somewhere else.
|
||||||
|
|
||||||
|
1. Communication
|
||||||
|
- I can nonviolently communicate with the people I care about.
|
||||||
|
Too abstract.
|
||||||
|
- When I talk to people, they perceive that I'm speaking in good faith. ✓
|
||||||
|
- I successfully assert my needs to others. ✓
|
||||||
|
- The last time I had a discussion, it was resolved gracefully. ✓
|
||||||
|
- When I debate with people, there is often a satisfying conclusion.
|
||||||
|
|
||||||
|
1. Stupid mistakes.
|
||||||
|
- How often do you make stupid mistakes?
|
||||||
|
- When was the last stupid mistake you made? ✓
|
||||||
|
- Write a short tweet about it.
|
||||||
|
- Did you implement any measures to avoid making that specific stupid mistake in the future? ✓
|
||||||
|
- If so, write a short tweet about it. ✓
|
||||||
|
|
||||||
|
1. Life satisfaction
|
||||||
|
- How satisfied are you with your life as a whole?
|
||||||
|
- To what extent do you agree with the statement: I am winning at life? ✓
|
||||||
|
- Stuckness: I feel like my life is stuck
|
||||||
|
|
||||||
|
1. Effective Approaches to Working on Projects
|
||||||
|
When I decide that I want to do something (like doing a project, developing a new regular practice, or changing some part of my lifestyle), I … ✓
|
||||||
|
- plan out what specific tasks I will need to do to accomplish it.
|
||||||
|
- try to think in advance about what obstacles I might face, and how I can get past them.
|
||||||
|
- seek out information about other people who have attempted similar projects to learn about what they did.
|
||||||
|
- end up getting it done.
|
||||||
|
The four items were averaged into a single measure of effective approaches to projects.
|
||||||
|
|
||||||
|
1. Probabilities / Calibration.
|
||||||
|
- Are you comfortable using probabilities? Do you use them in your daily life / When was the last time you explicitly assigned a probability to something?
|
||||||
|
- To what extent do you agree with the following: Thinking in terms of probabilities is a valuable tool in my skill repertoire.
|
||||||
|
- When was the last time you explicitly assigned a probability to something? Write a short tweet about it.
|
||||||
|
|
||||||
|
- "Calibration" is the practice of knowing how certain you are, even when you're not certain. For example, a bookie who says they're 90% certain of the outcome of each of a hundred horse races, and who is right about ninety out of those hundred horse races - is perfectly calibrated.
|
||||||
|
|
||||||
|
In these questions, you will be asked a question and then asked to give a calibration percent. The percent represents your probability that the answer is right. Suppose the question is "What country is the city of Paris located in?" and you are absolutely sure it is France. In that case, your calibration percent is 100 - you are 100% sure it is France.
|
||||||
|
|
||||||
|
But suppose you think there's a fifty-fifty chance it's either France or Germany. In that case, you might still answer France, but your calibration percent is only 50 - you are only 50% sure it's France.
|
||||||
|
|
||||||
|
Or suppose you have no idea, so you pick a country totally at random. In that case, you might think that if there are about one hundred possible countries, and it could be any of them, there's only about a 1% chance you're right. Therefore, you would put down a calibration percent of 1. Please answer on a scale from 0% (definitely false) to 100% (definitely true)
|
||||||
|
|
||||||
|
- Are you smiling right now?
|
||||||
|
- After each question: Without checking a source, estimate your subjective probability that the answer you just gave is correct.-
|
||||||
|
- Which is heavier, a virus or a prion?
|
||||||
|
- I'm thinking of a number between one and ten, what is it?
|
||||||
|
- What year was the fast food chain "Dairy Queen" founded? (Within five years)
|
||||||
|
- Alexander Hamilton appears on how many distinct denominations of US Currency?
|
||||||
|
- Without counting, how many keys on a standard IBM keyboard released after 1986, within ten?
|
||||||
|
- Too easy to cheat.
|
||||||
|
- What's the diameter of a standard soccerball, in cm within 2?
|
||||||
|
- How many calories in a reese's peanut butter cup within 20?
|
||||||
|
- What is the probability that supernatural events (including God, ghosts, magic, etc) have occurred since the
|
||||||
|
beginning of the universe?
|
||||||
|
- What is the probability that there is a god, defined as a supernatural intelligent entity who created the universe?
|
||||||
|
- What is the probability that any of humankind's revealed religions is more or less correct?
|
||||||
|
|
||||||
|
## Attribution
|
||||||
|
I took several questions from the 2016 LessWrong Diaspora Survey and the CFAR 2015 longitudinal study
|
||||||
|
CFAR's rationality checklist
|
||||||
|
http://www.rationality.org/resources/rationality-checklist
|
||||||
44
ESPR-Evaluation/5-Implementation.md
Normal file
|
|
@ -0,0 +1,44 @@
|
||||||
|
# Details of the implementation
|
||||||
|
|
||||||
|
## Talking with the staff about whether an RCT is a good idea.
|
||||||
|
|
||||||
|
Without the support of the staff, an RCT could not go forward. In particular, an RCT will require that we don't accept promising applicants, i.e., from the 2 most promising applicants, we'd want to have 1 in the control group. This to be a forced decision would probably engender great resentment.
|
||||||
|
|
||||||
|
Similarly, though we would prefer to have smaller groups, of 20, we wouldn't have enough power, even after 4 years if we went that route. Instead, we'd want to accept upwards of 32 students (-2 who, on expectation, won't get their visa on time). Other design studies, like ranking our applicants from 1 to 40, taking the best 20 and randomizing the last 20 (10 for ESPR, 10 for the control group) would appease the staff, but again wouldn't buy us enough power.
|
||||||
|
|
||||||
|
If we want our final alumni pool to be equally as good as in previous years, we would want to increase our reach, our advertising efforts say ~3x, i.e., to find 60 excellent students in total, 30 for the control and 30 for the treatment group. This would be possible by, f.ex., asking every previous participant to nominate a friend, by announcing the camp to the most prestigious highschools in countries with a rationality community, etc. An SSC post / banner wouldn't hurt. A successful effort in this area seems necessary for the full buy in of the staff, and might require additional funds.
|
||||||
|
|
||||||
|
## Spillovers.
|
||||||
|
|
||||||
|
If a promising person from the control group tried to apply the next year, we'd have to deny them the chance to come, or else lose the most promising people from the control group, losing validity.
|
||||||
|
|
||||||
|
We also don't want people on the control group to be disheartened because they didn't get in. For this, I suggest dividing our application in two steps: One in which we select both groups, and a coin toss.
|
||||||
|
|
||||||
|
If people have heard about ESPR, they might read writings by Kahneman, Bostrom, Yudkowsky, et al. If they aren't accepted, they might fulfill their need for cognition by continuing reading such materials. Thus, what we will measure will be the difference between applicants interested in rationality and applicants interested in rationality who go to ESPR, not between equally talented people with no previous contact. At any point, it would seem necessary to disallow explicit mentoring of applicants. Here, again, the full buy in of the staff is needed.
|
||||||
|
|
||||||
|
SPARC is another camp which teaches very similar stuff. I have considered doing the RCT both on ESPR and SPARC at the same time, but SPARC's emphasis on math olympiad people makes that a little bit sketchy. However, because they are still very similar interventions, we don't want to have a person in the control group going to SPARC. This might be a sore point.
|
||||||
|
|
||||||
|
## Stratification.
|
||||||
|
|
||||||
|
Suppose that after randomly allocating the students, we found that the treatment group was richer. This would *suck*, because maybe our effect is just them being, f.ex., healthier. In expectation, the two groups are the same, but maybe in practice they turn out not to be.
|
||||||
|
|
||||||
|
An alternative would be to divide the students into rich and poor, and randomly choose in each bucket. This is refered to as stratification, and buys additional power, though I still have to get into the gritty details. I'm still thinking about along which variables we want to stratify, if at all, and further reflection is needed.
|
||||||
|
|
||||||
|
Note to self: Paired random assignment might be a problem with respect to attrition (f.ex. no visa on time); JPAL recommends strata of at least 4 people.
|
||||||
|
|
||||||
|
## Measurements
|
||||||
|
|
||||||
|
The section of measurements was written by me, Nuño, alone. The next step would be to ask, f.ex. the teachers of each class to propose their own measurements, and combine them what we already have. In the case of NVC I have done a small literature review, so this is less vital, but still important.
|
||||||
|
|
||||||
|
## Incentives.
|
||||||
|
The survey takes 15-30 minutes to complete, and while I've tried to make it engaging and propose pauses, I think that an incentive is needed (i.e., the people in the control group might tell us to fuck off).
|
||||||
|
|
||||||
|
I initially thought about donating X USD to the AMF in their name every time they completed a survey, but I realized that this would motivate the most altruistical individuals the most, thus getting selection effects. Now, I'm leaning towards just giving the survey takers that amount of money.
|
||||||
|
|
||||||
|
As a lower bound, 40 people * 3 years * 2 surveys * 10 USD = 2400 USD, or 800 USD/year, as an upper bound, 60 people * 4 years * 4 surveys * 15 USD = 14400 USD or 3600 USD / year. I don't feel this is that significant in comparison to the total cost of the camp. More expensive, I think, is the time which I and others would work on this for free / the counterfactual projects we might undertake with that time. I am as of yet uncertain of the weight of this factor.
|
||||||
|
|
||||||
|
## Take off and burn.
|
||||||
|
|
||||||
|
To end with a high note, there is a noninsignificant probability that the first year of the RTC we realize we've made a number of grievous mistakes. I.e., it would surprise me if everything went without a hitch the first time. Personally, this only worries me if we don't learn enough to be able to pull it off the next year, which I happen to consider rather unlikely.
|
||||||
|
|
||||||
|
If that risk is unacceptable, we could partner with someone like IDInsight, MIT's JPAL, etc. The problem is that those organizations specialize in development interventions. It wouldn't hurt to ask, though.
|
||||||
BIN
ESPR-Evaluation/Designing-Surveys-Review/Gant.chart-001.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 156 KiB |
232
ESPR-Evaluation/Designing-Surveys-Review/Review.md
Normal file
|
|
@ -0,0 +1,232 @@
|
||||||
|
# Review of *The Power of Survey Design* and *Improving Survey Questions*
|
||||||
|
|
||||||
|
[Epistemic status: Confident.]
|
||||||
|
|
||||||
|
Simplicio: I have a question.
|
||||||
|
Salviati: Woe be upon me.
|
||||||
|
Simplicio: When people make surveys, how do they make sure that the questions measure what they want to measure?
|
||||||
|
|
||||||
|
## Outline
|
||||||
|
- Introduction.
|
||||||
|
- For the eyes of those who are designing a survey.
|
||||||
|
- People are inconsistent. Some ways in which populations are sistematically biased
|
||||||
|
- The Dark Arts!
|
||||||
|
- Legitimacy
|
||||||
|
- Don't bore the answerer
|
||||||
|
- Elite respondents.
|
||||||
|
- Useful categories
|
||||||
|
- Memory
|
||||||
|
- Consistency and ignorance
|
||||||
|
- Subjective vs objective questions
|
||||||
|
- Tactics
|
||||||
|
- Be aware of the biases
|
||||||
|
- Don't confuse the question with the question objective.
|
||||||
|
- An avalanche of advice.
|
||||||
|
- Closing thoughts
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
As part of my research on ESPR's impact, I've read two books on the topic of survey design, namely *The Power of Survey Design* (TPOSD) and *Improving survey questions: Design and Evaluation*.
|
||||||
|
|
||||||
|
They have given me an appreciation of the biases and problems that are likely to pop up when having people complete surveys, and I think this knowledge would be valuable to a variety of people in the EA and rationality communities.
|
||||||
|
|
||||||
|
For example, some people are looking into mental health as an effective cause area. In particular, in Spain Danica Wilbanks is working on trying to estimate the prevalence of mental health issues in the EA community. Something to consider in this case is that people with severe depression might be less likely to answer a survey, because doing so takes effort. So the actual proportion in the survey is likely to be an underestimate. Unless people with mental health issues are more likely to participate in a survey about the topic.
|
||||||
|
|
||||||
|
I've gotten some enjoyment and extra motivation out of inhabiting the state of mind of an [HPMOR Dark Lord](http://www.hpmor.com) while framing the study of these matters as learning the Dark Arts. May you share this enjoyment with me.
|
||||||
|
|
||||||
|
## For the eyes of those who are designing a survey:
|
||||||
|
|
||||||
|
You might want to read this review for the quicks, then:
|
||||||
|
|
||||||
|
a) If you don't want to spend too much time: Focus on [this checklist](), [this list of principles](), as well as [this neat summary I found on the internet]().
|
||||||
|
|
||||||
|
b) If you want to spend a moderate amount of time:
|
||||||
|
- Chapter 3 of *The Power of Survey Design* (68 pages) and/or Chapter 4 of *Improving survey questions* (22 pages) for general things to watch out for when writting questions. Chapter 3 of TPOSD is the backbone of the book.
|
||||||
|
- Chapter 5 of *The Power of Survey Design* (40 pages) for how to use the dark arts to have more people answer your questions willingly and happily.
|
||||||
|
|
||||||
|
c) For even more detail:
|
||||||
|
- The introductions, i.e. Chapter 1 and 2 of *The Power of Survey Design* (9 and 22 pages, respectively), and Chapter 1 of *Improving survey questions* (7 pages) if introductions are your thing, or if you want to plan your strategy. In particular, Chapter 2 of TPOSD has a cool Gantt Chart.
|
||||||
|
- Chapters 2 and 3 of *Improving survey questions* (38 and 32 pages, respectively) for considerations on gathering factual and subjective data, respectively.
|
||||||
|
- Chapter 5 of *Improving survey questions* (25 pages) for how to evaluate/test your survey before the actual implementation.
|
||||||
|
- Chapter 6 of *Improving survey questions* (12 pages) for kind of obvious advice about trying to find something like hospital records to validate your questionnaire with, or about repeating some important questions in slightly different form and get really worried if they don't answer the same thing.
|
||||||
|
|
||||||
|
[Here]() and [here]() are the indexes for both books. [libgen.io](libgen.io) might be of use to download an illegal copy.
|
||||||
|
|
||||||
|
Both books are clearly dated in some aspects: neither considers online surveys, as self-administered surveys were, back in the day, mailing surveys to people. The second suggests: "sensitive questions are put on a tape player (such as a *Walkman*) that can be heard only through earphones". However, I think that on the broad principles and considerations, both books remain useful guides.
|
||||||
|
|
||||||
|
## People are inconsistent. Some ways in which populations are sistematically biased
|
||||||
|
|
||||||
|
Here is a nonexhaustive collection of curious anecdotes mentioned in the first book:
|
||||||
|
|
||||||
|
- A Latinobarometro poll in 2004 showed that while a clear majority (63 percent) in Latin America would never support a military government, 55 percent would not mind a nondemocratic government if it solved economic problems.
|
||||||
|
|
||||||
|
- When asked about a fictitious “Public Affairs Act” one-third of respondents volunteered an answer
|
||||||
|
|
||||||
|
- The choice of numeric scales has an impact on response patterns: Using a scale which goes from -5 to produces a different distribution of answers than using a scale that goes from 0 to 10.
|
||||||
|
|
||||||
|
- The order of questions influences the answer. Wording as well: framing the question with the term "welfare" instead of with the formulation "incentives for people with low incomes" produces a big effect.
|
||||||
|
|
||||||
|
- Options that appear at the beginning of a long list seem to have a higher likelihood of being selected. For example, when alternatives are listed from poor to excellent rather than the other way around, respondents are more likely to use the negative end of the scale. Unless it's in a phone interview, or read out loud, in which case the last options are more likely.
|
||||||
|
|
||||||
|
- When asked whether they had visited a doctor in the last two weeks: Apparently, when respondents have had a recent doctor visit, but not one within the last two weeks, there is a tendency to want to report it. In essence, they feel that accurate reporting really means that they are the kind of person who saw a doctor recently, if not exactly and precisely within the last two weeks.
|
||||||
|
|
||||||
|
- The percentage of people supporting US involvement in WW2 almost doubled if the word "Hitler" appeared in the question.
|
||||||
|
|
||||||
|
Frankly, I find this so fucking scary. I guess that some part of me implictly had a model of people having a thought out position with respect to democracy, which questions merely elicited. As if.
|
||||||
|
|
||||||
|
## The Dark Arts!
|
||||||
|
|
||||||
|
Key extract: "Evidence shows that expressions of reclutance can be overcome" (p. 175, *The Power of Survey Design*, and Chapter 5 of the same book). I'm fascinated by this chapter, because the author has spent way more time thinking about this than the survey-taker: he is one or two levels above the potential answerer and can nudge his behavior.
|
||||||
|
|
||||||
|
As a short aside, the analogies to pick up artistry are abundant. One could caritatively summarize their position as highlighting that questions pertaining romance and sex will be answered differently depending on how they're posed, because people don't have an answer written in stone beforehand.
|
||||||
|
|
||||||
|
Of course, the questionnaire writer could write biased questions with the intention of producing the answers he wishes to obtain, but these books go in a subtle direction: Once good questions have been written, how do you convice people, perhaps initially reclutant, to take part in your survey? How do you get them to answer sensitive questions truthfully?
|
||||||
|
|
||||||
|
For example:
|
||||||
|
|
||||||
|
> Three factors have been proven to affect persuasion: the quantity of the arguments presented, the quality of the arguments, and the relevance of the topic to the respondent. Research on attitude change shows that the number of arguments (quantity) presented has an impact on respondent attitudes only if saliency is low (figure 5.6). Conversely, the quality of the arguments has a positive impact on respondents only if personal involvement is high (figure 5.7) When respondents show high involvement, argument quality has a much stronger effect on persuasion, while weak arguments might be counterproductive. At the same time, when saliency is low, the quantity of the arguments appears to be effective, while their quality has no significant persuasive effect (figure 5.8) (Petty and Cacioppo 1984).
|
||||||
|
> These few minutes of introduction will determine the climate of the entire interview. Hence, this time is extremely important and it must be used to pique the respondent’s interest...
|
||||||
|
|
||||||
|
Most importantly, how do you defend against someone who has carried out multiple randomized trials to map out the different behaviors you might adopt, and how to best persuade you in each of them? I feel that Tzvi's essay on people who "are out to get you" has mapped the possible behaviors you might adopt in defense. Chief among them is actually being aware.
|
||||||
|
|
||||||
|
### Legitimacy
|
||||||
|
|
||||||
|
At the beginning, make sure to assure legal confidentiality, maybe research the relevant laws in your jurisdiction and make reference to them. Name drop sponsors, include contact names and phone numbers. Explain the importance of your research, its unique characteristics and practical benefits.
|
||||||
|
|
||||||
|
There is a part of signalling [spelling] confidentiality, legitimacy, competence which involves actually doing the thing. For example, if you assure legal confidentiality, but then ask information which would permit easy deanonimization, people might notice and get pissed. But another part is merely: be aware of this dimension.
|
||||||
|
|
||||||
|
The first questions should be easy, pleasant, and interesting. Build up confidence in the survey's objective, stimulate their interest and participation by making sure that the respondent is able to see the relationship between the question asked and the purpose of the study.
|
||||||
|
|
||||||
|
Make sensitive questions longer, as they are then perceived as less threatening. Perhaps add a preface explaining that both alternatives are ok. Don't ask them at the beginning of your survey.
|
||||||
|
|
||||||
|
### Bears repeating: Don't bore the answerer.
|
||||||
|
Seems obvious. Cooperation will be highest when the questionnaire is interesting and when it avoids items difficult to answer, time-consuming, or embarrassing. In my case, making my survey interesting means starting with a prisoner's dilemma with real payoffs, which will double as the monetary incentive to complete the survey.
|
||||||
|
|
||||||
|
It serves no purpose to ask the respondent about something he or she does not understand clearly or that is too far in the past to remember correctly; doing so generates inaccurate information.
|
||||||
|
|
||||||
|
Don't ask a long sequence of very similar questions. This bores and irritates people, which leads them to answer mechanically. A term used for this is acquiescence bias: in questions with an "agree-disagre" or "yes-no" format, people tend to agree or say yes even when the meaning is reversed. In questions with a "0-5" scale, people tend to choose 2.
|
||||||
|
|
||||||
|
On the other hard, don't make them hord to hard. In general, telling the respondents a definition and asking them to clasify themselves, is too much work.
|
||||||
|
|
||||||
|
### Elite respondents
|
||||||
|
This section might be particularly relevant for the high-IQ crowd characteristic of the EA and LW movements. Again, the key movement is to match the level of cognitive complexity of the question with the respondent's level of cognitive ability, as not doing so leads to frustration. Looking back on my experiences as a survey participant, this does mirror my experience.
|
||||||
|
|
||||||
|
Elites are apparently quickly irritated if the topic of the questions is not of interest to them. Vague queries generate a sense of frustration, and lead to a perception that the study is not legitimate. Oversimplifications are noticed and disliked.
|
||||||
|
|
||||||
|
Start with a narrative question, add open questions at regular intervals throughout the form. Elites “resent being encased in the straightjacket of standardized questions” and feel particularly frustrated if they perceive that the response alternatives do not accurately address their key concern.
|
||||||
|
|
||||||
|
For example, the recent 80,000 Hours had the following question: "Have your career plans changed in any way as result of engaging with 80,000 Hours?". The possible answers were not really exhaustive, and in particularly, there was no option for "I made a big change, but only partially as a result of 80,000 Hours". Or "I made a big change, but I am really not sure of what the counterfactual scenario would have been". I remember that this frustrated me, because, as far as I remember the alternatives did not provide a clear way to express this.
|
||||||
|
|
||||||
|
*Improving Survey Questions* goes on at length about ensuring that people are asked questions to which they know the answers, and in some cases, "Have your career plans changed in any way as result of engaging with 80,000 Hours?" [look up which exact question was it] might be one of them. Perhaps an alternative would be to divide that question in:
|
||||||
|
|
||||||
|
- Have your career plans changed in any way in the last year?
|
||||||
|
- How big was that change?
|
||||||
|
- Did 80,000h have any influence on it?
|
||||||
|
- Where "100" means that 80,000h was unambiguously causally responsible [spelling] for that change, "50" means that you would have given it even odds to you making that change in the absence of any interaction with 80K, and "0" means that you're absolutely sure 80K had nothing to do with that change, how much has 80,000h influenced that change? responsibility [check spelling].
|
||||||
|
|
||||||
|
Yet I'm not confident that formulation is superior, and at some level, I trust 80K to have [done their homework](https://80000hours.org/2017/12/annual-review/).
|
||||||
|
|
||||||
|
## Useful categories.
|
||||||
|
|
||||||
|
### Memory
|
||||||
|
|
||||||
|
Events less than two weeks into the past can be remembered without much error. There are several ways in which people can estimate the frequency with which something happens, chiefly:
|
||||||
|
- Availability bias: How easy it is to remember X.
|
||||||
|
- Episodic enumeration: Recalling and counting occurrences of an event
|
||||||
|
- Resorting to some sense of normative frequency.
|
||||||
|
- etc.
|
||||||
|
|
||||||
|
Of these, episodic enumeration turns out to be the most accurate, and people use it more the less instances of the things there are. The wording of the question might be changed to facilitate episodic enummeration.
|
||||||
|
|
||||||
|
Asking a longer question, and communicating to responders the significance of the question has a positive effect on the accuracy of the answer. This means phrasing such as “please take your time to answer this question,” “the accuracy of this question is particularly important,” or “please take at least 30 seconds to think about this question before answering”.
|
||||||
|
|
||||||
|
If you want to measure knowledge, take into account that recognizing is easier than recalling. More people will be able to recognize a definition of effective altruism than be able to produce one on their own. If you use a multiple question with n options, and x% of people knew the answer, whereas (100-x)% didn't, you might expect that (100-x)/n % hadn't known the answer, but guessed correctly by chance, so you'd see that y% = x% + (100-x)/n % selected the correct option.
|
||||||
|
|
||||||
|
### Consistency and Ignorance.
|
||||||
|
|
||||||
|
In of our examples at the beginning, one third of respondents gave an opinion about a ficticious Act. This generalizes; respondents rarely admit ignorance. It is thus a good idea to offer an "I don't know", or "I don't really care about this topic". The recent SlateStarCodex Community Survey had a problem in this regard with respect to some questions, because once checked, they couldn't go unchecked.
|
||||||
|
|
||||||
|
With regards to consistency, it is a good idea to ask similar questions in different parts of the questionnaire to check the consistency of answers. Reverse some of the questions.
|
||||||
|
|
||||||
|
### Subjective vs objective questions
|
||||||
|
The author of *Improving Survey Questions* views the distinction between objective and subjective questions as very important. That there is no direct way to know about people's subjective states independent of what they tell us apparently has serious metaphysical implications. To this, he devotes a whole chapter.
|
||||||
|
|
||||||
|
Anyways, despite the lack of an independent measure, there are still things to do, chiefly:
|
||||||
|
- Place answers on a single well defined continuum
|
||||||
|
- Specify clearly what is to be rated.
|
||||||
|
|
||||||
|
And yet, the author goes full relativist:
|
||||||
|
> "The concept of bias is meaningless for subjective questions. By changing wording, response order, or other things, it is possible to change the distribution of answers. However, the concept of bias implies systematic deviations from some true score, and there is no true score... Do not conclude that "most people favor gun control", "most people oppose abortions"... All that happened is that a majority of respondents picked response alternatives to a particular question that the researcher chose to interpret as favorable or positive."
|
||||||
|
|
||||||
|
## Test your questionnaire
|
||||||
|
I appreciated the pithy phrases "Armchair discussions cannot replace direct contact with the population being analyzed" and "Everybody thinks they can write good survey questions". With respect to testing a questionnaire, the books go over different strategies and argues for some reflexivity when deciding what type of test to undertake.
|
||||||
|
|
||||||
|
In particular, the intuitive or traditional way to go about testing a questionnaire would be a focus group: you have some test subjects, have them take the survey, and then talk with them or with the interviewers. This, the authors argue, is messy, because some people might dominate the conversation out of proportion to the problems they encountered. Additionally, random respondents are not actually very good judges of questions.
|
||||||
|
|
||||||
|
Instead, no matter what type of test you're carrying out, having a table with issues for each question, filled individually and before any discussion, makes the process less prone to social effects.
|
||||||
|
|
||||||
|
Another alternative is to try to get in the mind of the respondent while they're taking the survey. To this effect, you can ask respondents:
|
||||||
|
- to paraphrase their understanding of the question.
|
||||||
|
- to define terms
|
||||||
|
- for any uncertainties or confusions
|
||||||
|
- how accurately they were able to answer certain question and how likely they think they or others would be to distort answers to certain questions
|
||||||
|
- if the question called for a numerical figure, how they arrived at the number.
|
||||||
|
|
||||||
|
F.ex.:
|
||||||
|
Question: Overall, how would you rate your health: excellent, very good, fair, or poor?
|
||||||
|
Followup question: When you said that your health was (previous answer), what did you take into account or think about in making that rating?
|
||||||
|
|
||||||
|
In the case of pretesting the survey, a division in conventional, behavioral and cognitive interview is presented, and the cases in which each of them are more adequate are outlined.
|
||||||
|
|
||||||
|
Considerations about tiring the answerer still apply: a long list of similar questions is likely to induce boredom. For this reason, ISQ recommends testing "half a dozen" questions at a time.
|
||||||
|
|
||||||
|
As an aside, if you want to measure the amount of healthcare consumed in the last 6 months, you might come up with a biased estimate even if your questions aren't problematic, and this would be because the people who just died consume a lot of healthcare, but can't answer your survey.
|
||||||
|
|
||||||
|
## Tactics
|
||||||
|
|
||||||
|
### Be aware of the biases
|
||||||
|
Be aware of the ways of the ways a question can be biased. Don't load your questions: don't use positive or negative adjectives in your question. Take into account social desirability bias: "Do you work" has implications with regards to status.
|
||||||
|
|
||||||
|
An good example given, which tries to reduce social desirability bias, is the following:
|
||||||
|
> Sometimes we know that people are not able to vote, because they are not interested in the election, because they can't get off from work, because they have family pressures, or for many other reasons. Thinking about the presidential elections last November, did you actually vote in that election or not?
|
||||||
|
|
||||||
|
Additionally, black respondents were significantly more likely to report that they had voted in the last election to a black interviewer than to a white interviewer. By the way, self-administered surveys are great at not creating bias because of the interviewer; answerers don't feel such a need to impress.
|
||||||
|
|
||||||
|
There is also the aspect of managing self-images: it's not only that the respondent may want to impress, it's also that she may want to think about herself in certain ways. You don't want to have respondents feel they're put in a negative (i.e., inaccurate) light. Respondents "are concerned that they'll be misclassified, and they'll distort the answers in a way they think will provide a more accurate picture" (i.e., they'll lie through their teeth). The defense against this is to allow the respondent to give context.
|
||||||
|
For example:
|
||||||
|
- How much did you drink last weekend?
|
||||||
|
- Do you feel that this period is representative?
|
||||||
|
- What is a normal amount to drink in your social context?
|
||||||
|
|
||||||
|
So, get into their head and manage the way they perceive the questions. Minimize the sense that certain answers will be negatively valued. "Permit respondents to present themselves in a positive way at the same time they provide the information needed".
|
||||||
|
|
||||||
|
In questions for which biases are likely to pop up, consider explicitly explaining to respondents that giving accurate answers is the most important thing they can do. Have respondents make a commitment to give accurate answers at the beginning; it can't hurt.
|
||||||
|
|
||||||
|
This, together with legitimacy signaling, has been tested, and it *reduces the number of books which well-educated people report reading*.
|
||||||
|
|
||||||
|
### Don't confuse question objective with question.
|
||||||
|
|
||||||
|
In the previous example, the question objective could be finding out what proportion of the population votes. Simply putting the objective in question form (f.ex., "Did you vote in the last presidential election?") is not enough.
|
||||||
|
|
||||||
|
**The soundest advice any person beginning to design a survey instrument could receive is to produce a good, detailed list of question objectives and an analysis plan that outlines how the data will be used**
|
||||||
|
|
||||||
|
If a researcher cannot match a question with an objective and a role in the analysis plan, the question should not be asked, tell us our authorities.
|
||||||
|
|
||||||
|
### An avalanche of advice.
|
||||||
|
|
||||||
|
The combined 464 pages contain a plethora of advice. To not feel overwhelmed, [this checklist](), [this list of principles](), or [this helpful summary I found on the internet]() might be helpful.
|
||||||
|
|
||||||
|
Ask one question at a time. For example: "Compared to last year, how much are you winning at life?" is confusing, and would be less so if it was divided into: "How much are you winning at life today?" and "how much were you winning at life last year?". If the question was particularly important, a short paragraph explaining what you mean by winning at life would be in order.
|
||||||
|
|
||||||
|
An aclatory paragraph would have to come before the question, as would other clarifications: after the respondent thinks she has read a question, she will not listen to the definition provided afterwards. Same for technical terms.
|
||||||
|
|
||||||
|
An avalanche of advice is can be gathered from our two books: Not avoiding the use of double negatives makes for confusing sentences, like this one. Avoid the use of different terms with the same meaning. Make your alternatives mutually exclusive and exhaustive. Don't make your questions all too long. As a rule of thumb, keep your question under of 20 words and 3 commas (unless you're trying to estimulate recall, or it's a question about sensitive topics). Remember that the longer the list of questions, the lower the quality of the data. And so on.
|
||||||
|
|
||||||
|
## Closing thoughts.
|
||||||
|
The rabbit hole of designing questionnaires is deep, but seems well mapped.
|
||||||
|
|
||||||
|
Because of the power of specialization, this doesn't need to become common knowledge, but I expect that a small number of people, f.ex., those who occasionally design community surveys, or those who want to estimate the impact of an activity, might benefit greatly from the pointers given here. I'd also be happy to lend a hand, if needed.
|
||||||
|
|
||||||
|
Boggling at the concept of a manual, I am grateful to have access to the wisdom of someone who has spent a lifetime studying the specific topic of interviews, and who provides a framework for me to think about them.
|
||||||
|
|
||||||
|
I appreciate that the books are doing 95% of the thinking for me, or in other words, that the authors have spent more than 20 times thinking about those things as I have. MIRI has been speaking about preparadigmatic fields, and I've noticed a notable jump between my previous diffuse intuitions and the structure which these books provide.
|
||||||
BIN
ESPR-Evaluation/Designing-Surveys-Review/Summary.pdf
Normal file
BIN
ESPR-Evaluation/Pre-post-1.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 148 KiB |
BIN
ESPR-Evaluation/Pre-post-2.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 165 KiB |
357
ESPR-Evaluation/Questionnaire-stable.md
Normal file
|
|
@ -0,0 +1,357 @@
|
||||||
|
Index:
|
||||||
|
|
||||||
|
Intro:
|
||||||
|
- Prisoner's dilemma
|
||||||
|
- Demographics.
|
||||||
|
|
||||||
|
Common endgoals:
|
||||||
|
- Life satisfaction
|
||||||
|
- Social
|
||||||
|
|
||||||
|
Epistemic rationality. Less sensitive.
|
||||||
|
- Calibration
|
||||||
|
- Thinking probabilistically
|
||||||
|
(- Changing your mind)
|
||||||
|
(- Noticing cognitive biases.)
|
||||||
|
|
||||||
|
Instrumental strategies
|
||||||
|
- Communication. NVC.
|
||||||
|
- Goals / clarity about goals.
|
||||||
|
- Internal design, introspections, emotions
|
||||||
|
emotional stability.
|
||||||
|
- Habits and self modification
|
||||||
|
- Trying out new things
|
||||||
|
- Communication
|
||||||
|
- Projects
|
||||||
|
- SPORT!
|
||||||
|
|
||||||
|
Interest in. Less sensitive.
|
||||||
|
- Effective Altruism
|
||||||
|
- Existential risk
|
||||||
|
- AI safety
|
||||||
|
|
||||||
|
## Introductory questions
|
||||||
|
|
||||||
|
What is the purpose of this study? The purpose of this study is to estimate the impact of ESPR. For this purpose, the answers to a baseline questionnaire (this one) from both participants and applicants which could have been participants will be compared with the answers from both groups to an followup questionnaire (after the camp has taken place).
|
||||||
|
Who is sponsoring this study? The Effective Altruism Funds, a program under the Center for Effective Altruism.
|
||||||
|
Who is doing the study? Nuño Sempere. For any questions, comments or complaints, I can be reached at nuno.semperelh@gmail.com
|
||||||
|
What kinds of questions will be asked? Questions about factors in which ESPR could have an effect, as well as questions about cofounders, like wealth or gender.
|
||||||
|
Are my answers confidential? Yes. Your answers will never be used in any way that would identify you. They will be combined with answers from other respondents to make a statistical report. Your email will only be used to send you the followup survey, and will not be made public.
|
||||||
|
Do I get any compensation? Yes, and the exact payoff depends on a prisonner's dilemma! (see the first question).
|
||||||
|
|
||||||
|
Do you consent to having your survey responses be used for research purposes?
|
||||||
|
|
||||||
|
Do you consent to having your answers added to a public dataset?
|
||||||
|
|
||||||
|
Do you promise to give accurate answers, to the best of your ability?
|
||||||
|
|
||||||
|
## Prisoner's dilemma with real payoffs.
|
||||||
|
Reasoning for the question: Studies show that beginning with an stimulating question increases participation and data quality. We also want to give a small incentive to people who answer this questionnaire, and we think that this is a cool way to do it.
|
||||||
|
|
||||||
|
Are you familiar with the prisoner's dilemma game?
|
||||||
|
|
||||||
|
-> Yes.
|
||||||
|
-> No.
|
||||||
|
Read this: https://en.wikipedia.org/wiki/Prisoner%27s_dilemma
|
||||||
|
|
||||||
|
You will be randomly matched to another prospective ESPR participant in a prisoner's dilemma with the following real payoffs:
|
||||||
|
- Cooperate/Cooperate: $10 / $10 (if both players cooperate, both receive $10.
|
||||||
|
- Cooperate/Defect: $0/$15 (if one player defects, he receives $15, and the other gets nothing)
|
||||||
|
- Defect/Cooperate: $15/$0
|
||||||
|
- Defect/Defect. $5/$5 (if both players defect, both get $5)
|
||||||
|
Do you choose to defect or to cooperate?
|
||||||
|
|
||||||
|
What is your email?
|
||||||
|
Your email will be needed to send you the payoff, and for the followup survey.
|
||||||
|
|
||||||
|
|
||||||
|
(an unconditional gift of $5 was twice as effective as a conditional offer of $50 in getting people to fill out surveys
|
||||||
|
Oh, come on.
|
||||||
|
)
|
||||||
|
|
||||||
|
## Demographics
|
||||||
|
- Reasoning for this question: We want to distinguish between the effects of ESPR and the effects of growing up. Though we don't expect it to, we would also like to know if gender makes any difference in the impact of our program.
|
||||||
|
|
||||||
|
What is your date of birth? (Month and Year)
|
||||||
|
What is your gender?
|
||||||
|
- Male.
|
||||||
|
- Female.
|
||||||
|
- Other.
|
||||||
|
- Don't want to answer.
|
||||||
|
|
||||||
|
Growing up, would you characterize your family as working class, lower middle class, middle class, upper middle class, or well off?
|
||||||
|
The reasoning for this inexact question is:
|
||||||
|
- We don't feel comfortable asking detailed income information.
|
||||||
|
- But we still want to get a modicum of information on the topic.
|
||||||
|
|
||||||
|
[Alternative:
|
||||||
|
We understand that in some cases, the words income and family might not be well defined. If that is the case, use your best judgement to resolve any issues that might come up. That being said, (before/after) taxes, what is your family's combined income?
|
||||||
|
- Problems with the question: Definition of income, definition of family.
|
||||||
|
- It also takes too much time (potentially >10 mins) to answer. The applicant will probably not know the answer and have to ask his parents, who might not want to answer.
|
||||||
|
]
|
||||||
|
|
||||||
|
## Probabilities and Calibration
|
||||||
|
Consider a scale from 0 to 10, where 8,9 and 10 indicate "to great extent"; 0,1, and 2 "to a very small extent"; and 3 through 7 are in between. To what extent are you comfortable using probabilities and probabilistic reasoning?
|
||||||
|
|
||||||
|
Without taking into account this questionnaire or anything related to ESPR, when was the last time you can remember reasoning in terms of probabilities?
|
||||||
|
|
||||||
|
When was the last time when thinking in terms of probabilities changed what you were going to do?
|
||||||
|
|
||||||
|
Consider a scale from 0 to 10, where 8,9 and 10 indicate "to great extent"; 0,1, and 2 "to a very small extent"; and 3 through 7 are in between. To what extent do you feel that probabilities and probabilistic reasoning are useful tools in your repertoire?
|
||||||
|
|
||||||
|
### Calibration
|
||||||
|
This part asks you to answer some questions, and then pull some probabilities out of your ass.
|
||||||
|
|
||||||
|
1. What date is it today?
|
||||||
|
2. Without checking a source, estimate your subjective probability that the answer you just gave is correct
|
||||||
|
|
||||||
|
3. Which is heavier, a virus or a prion?
|
||||||
|
|
||||||
|
4. Without checking a source, estimate your subjective probability that the answer you just gave is correct.
|
||||||
|
|
||||||
|
5. I'm thinking of a number between one and ten, what is it?
|
||||||
|
|
||||||
|
6. Without checking a source, estimate your subjective probability that the answer you just gave is correct.
|
||||||
|
|
||||||
|
7. What year was the fast food chain "Dairy Queen" founded? (Within five years)
|
||||||
|
|
||||||
|
8. Without checking a source, estimate your subjective probability that the answer you just gave is correct.
|
||||||
|
|
||||||
|
9. Alexander Hamilton appears on how many distinct denominations of US Currency?
|
||||||
|
|
||||||
|
10. Without checking a source, estimate your subjective probability that the answer you just gave is correct.
|
||||||
|
|
||||||
|
11. What's the diameter of a standard soccerball, in cm within 2?
|
||||||
|
|
||||||
|
12. Without checking a source, estimate your subjective probability that the answer you just gave is correct.S
|
||||||
|
|
||||||
|
13. What probability do you assign to Donald Trump winning a second presidential election?
|
||||||
|
|
||||||
|
14. What is your subjective probability that there is a god, defined as a supernatural intelligent entity who created the universe?
|
||||||
|
|
||||||
|
15. What probability do you subjectively assign to any of humankind's revealed religions being more or less correct?
|
||||||
|
|
||||||
|
16. At the beginning of this survey, you took part in a prisoner's dilemma. You will be matched with a randomly selected prospective participant. What probability do you assign to that other participant defecting?
|
||||||
|
|
||||||
|
17. Other participants are also trying to answer this survey. What probability do you assign to yourself having a better Brier score than 50% of participants (not including this question)?
|
||||||
|
|
||||||
|
18. What probability do you assign to Donald Trump, the current president of the USA, winning the 2022 presidential elections?
|
||||||
|
|
||||||
|
|
||||||
|
## Life satisfaction.
|
||||||
|
|
||||||
|
Consider a scale from 0 to 10, where 8,9 and 10 indicate great satisfaction; 0,1, and 2 very little satisfaction; and 3 through 7 are in between. How satisfied are you with your life as a whole?
|
||||||
|
|
||||||
|
Consider a scale from 0 to 10, where 8,9 and 10 indicate "to great extent"; 0,1, and 2 "to a very small extent"; and 3 through 7 are in between. To what extent do you feel like your life is stuck?
|
||||||
|
|
||||||
|
In same scale as before, how satisfied are you with the following domains?
|
||||||
|
- romantic relationships
|
||||||
|
- work / school / career
|
||||||
|
- friendships / non-romantic social life
|
||||||
|
|
||||||
|
Subjective Happiness Scale.
|
||||||
|
http://sonjalyubomirsky.com/subjective-happiness-scale-shs/
|
||||||
|
|
||||||
|
1. In general, I consider myself:
|
||||||
|
|
||||||
|
not a very happy person
|
||||||
|
1 2 3 4 5 6 7
|
||||||
|
a very happy person
|
||||||
|
|
||||||
|
2. Compared with most of my peers, I consider myself:
|
||||||
|
|
||||||
|
less happy
|
||||||
|
1 2 3 4 5 6 7 more happy
|
||||||
|
|
||||||
|
3. Some people are generally very happy. They enjoy life regardless of what is going on, getting the most out of everything. To what extent does this characterization describe you?
|
||||||
|
|
||||||
|
not at all
|
||||||
|
1 2 3 4 5 6 7 a great deal
|
||||||
|
|
||||||
|
4. Some people are generally not very happy. Although they are not depressed, they never seem as happy as they might be. To what extent does this characterization describe you?
|
||||||
|
|
||||||
|
not at all
|
||||||
|
1 2 3 4 5 6 7 a great deal
|
||||||
|
|
||||||
|
## Social.
|
||||||
|
|
||||||
|
Consider a scale from 0 to 10, where 8,9 and 10 indicate great satisfaction; 0,1, and 2 very little satisfaction; and 3 through 7 are in between. Excluding romantic relationships, how satisfied are you with your social life?
|
||||||
|
|
||||||
|
In that same scale: how satisfied are you with your romantic life?
|
||||||
|
(These are people 15-18. Probably not winning at romance. Maybe exclude this question).
|
||||||
|
|
||||||
|
Some common ways to generate an estimate of the number of people you socially interacted with in the past week are:
|
||||||
|
- Episodic enumeration: Count the amount of people you can recall, and report that number.
|
||||||
|
- Availability heuristic: As a first order estimate, equate frequency with ease of recalling: i.e., report a higher number if you can remember many examples in a short amount of time.
|
||||||
|
- Automatic or moral estimation: Resort to some innate or normative sense of frequency, for example depending on whether you think of yourself as a very social person.
|
||||||
|
|
||||||
|
Studies show that the most accurate strategy is episodic enummeration. Do you promise to use this method throughout the survey? -> Yes
|
||||||
|
|
||||||
|
In the past week, how many people can you recall socially interacting with?
|
||||||
|
How many people in which you'd be willing to confide about something personal can you come up with?
|
||||||
|
How many people can you name who would let you crash at their place?
|
||||||
|
|
||||||
|
## Emotions
|
||||||
|
When you feel emotions, do they mostly help or hinder you in pursuing your goals?
|
||||||
|
|
||||||
|
- General self-efficacy scale (Chen, 2001)
|
||||||
|
|
||||||
|
For the following questions, do you agree or disagree?
|
||||||
|
1. I will be able to achieve most of the goals that I have set for myself.
|
||||||
|
2. When facing difficult tasks, I am certain that I will accomplish them.
|
||||||
|
3. In general, I think that I can obtain outcomes that are important to me.
|
||||||
|
4. I believe I can succeed at most any endeavor to which I set my mind.
|
||||||
|
5. I will be able to successfully overcome many challenges.
|
||||||
|
6. I am confident that I can perform effectively on many different tasks.
|
||||||
|
7. Compared to other people, I can do most tasks very well.
|
||||||
|
8. Even when things are tough, I can perform quite well.
|
||||||
|
|
||||||
|
- Subjective happiness Scale (Lyubomirsky, 1997)
|
||||||
|
|
||||||
|
1. In general I consider myself
|
||||||
|
not a very happy person : 1 2 3 4 5 6 7 a very happy person
|
||||||
|
2. Compared to most of my peers, I consider myself
|
||||||
|
less happy: 1 2 3 4 5 6 7 more happy
|
||||||
|
3. Some people are generally very happy. They enjoy life regardless of what is going on, getting the most out of everything. To what extent does this characterization describe you?
|
||||||
|
not at all: 1 2 3 4 5 6 7 a great deal
|
||||||
|
4. Some people are generally not very happy. Although they are not depressed, they never seem as happy as they might be. To what extent does this characterization describe you?
|
||||||
|
not at all : 1 2 3 4 5 6 7 a great deal.
|
||||||
|
|
||||||
|
Emotional Maturity Scale (Schutte, 1998). 33 items.
|
||||||
|
|
||||||
|
## Techniques
|
||||||
|
Can you think of any changes that you’ve made in the past month to your daily routines or habits in order to make things go better? These can be tiny changes (e.g., adjusted the curtains on my bedroom window so that less light comes in while I’m sleeping) or large ones. Spend about 60 seconds recalling as many examples of these kinds of changes as you can and listing them here. (If you want to skip this question, leave it blank. If you spend the 60 seconds and no specific examples come to mind, write "none.")
|
||||||
|
- is 60s enough time?
|
||||||
|
|
||||||
|
How many changes did you write under the above question?
|
||||||
|
|
||||||
|
Even capable people make stupid mistakes, f.ex. forgetting a computer charger at home before an international flight. Take a moment to think about the last one you made. What was it?
|
||||||
|
|
||||||
|
Did you take any measures to avoid making that mistake or class of mistakes in the future?
|
||||||
|
|
||||||
|
(If so), which measures did you take?
|
||||||
|
|
||||||
|
This last week, how many hours did you do sports, or other physically streneous activities?
|
||||||
|
|
||||||
|
Write your answer to the following questions in the format "day/month/year" to the best of your abilities. Note that this can mean that the day you give is approximate.
|
||||||
|
|
||||||
|
Take 60 seconds to recall the last time you did something you thought had a very low chance of succeeding. What was it?
|
||||||
|
- Option for "I don't
|
||||||
|
|
||||||
|
When was it? (Give your best estimate in the form day/month/year.)
|
||||||
|
- Free form answers in the pre-test, from which we can maybe get a couple of categories.
|
||||||
|
- Option of: I don't rember.
|
||||||
|
|
||||||
|
Take 60 seconds to recall the last time you tried out something new; something which you hadn't done before. What was it?
|
||||||
|
|
||||||
|
When was it? (Give your best estimate in the form day/month/year.)
|
||||||
|
- Free form answers in the pre-test, from which we can maybe get a couple of categories.
|
||||||
|
- Option of: I don't rember.
|
||||||
|
|
||||||
|
When was the last time you *read or heard about* another plausible-seeming technique or approach for being more rational / more productive / happier / having better social relationships / having more accurate beliefs / etc.?
|
||||||
|
|
||||||
|
When was the last time you *tried out* another plausible-seeming technique or approach for being more rational / more productive / happier / having better social relationships / having more accurate beliefs / etc.?
|
||||||
|
|
||||||
|
When was the last time you found out about another plausible-seeming technique or approach which *successfully helps you at* being more rational / more productive / happier / having better social relationships / having more accurate beliefs / etc.?
|
||||||
|
|
||||||
|
How many hours did you spend productive work yesterday (or on your most recent workday)?
|
||||||
|
(maybe ask Dan for the exact questions?)
|
||||||
|
|
||||||
|
In a scale from 0% efficiency, where you are not getting anything done, to 100% efficiency, where you are working as productively as you're capable on, what was the efficiency of the time you spent working yesterday (or on your most recent workday)?
|
||||||
|
|
||||||
|
For how many of those hours did you feel physically motivated to do the task at hand, i.e., the thing that you were doing was the thing that you felt like doing at that moment?
|
||||||
|
|
||||||
|
What was the last proyect you undertook? Projects can be things like writting a program, seducing a romantic interest, writting a book/blog, researching something in depth, etc. If you have many going on at the same time, pick one. Do not change it afterwards.
|
||||||
|
|
||||||
|
Do you feel that this project is broadly representative of the general way you go about undertaking projects?
|
||||||
|
- No, I'm usually much less efective/capable/etc.
|
||||||
|
- No, I'm usually somewhat less efective/capable/etc.
|
||||||
|
- Yes, this is roughly typical for me.
|
||||||
|
- No, I'm usually somewhat more efective/capable/etc.
|
||||||
|
- No, I'm usually much more efective/capable/etc.
|
||||||
|
|
||||||
|
In general, when you undertake a project, do you plan out what specific tasks you will need to do to accomplish it?
|
||||||
|
- 1-6 scale from “Almost never” to “Almost always”.
|
||||||
|
|
||||||
|
For the project you mentioned above, did you plan out what specific tasks you will need to do to accomplish it?
|
||||||
|
- Yes
|
||||||
|
- No
|
||||||
|
|
||||||
|
In general, when you undertake a project, do you try to think in advance about what obstacles I might face, and how I can get past them
|
||||||
|
- 1-6 scale from “Almost never” to “Almost always”.
|
||||||
|
|
||||||
|
For the project you mentioned above, did you seek out information about other people who have attempted similar projects to learn about what they did
|
||||||
|
- Yes
|
||||||
|
- No
|
||||||
|
|
||||||
|
In general, when you undertake a project, do you end up getting it done?
|
||||||
|
- 1-6 scale from “Almost never” to “Almost always”.
|
||||||
|
|
||||||
|
For the project you mentioned above, did you end up getting it done?
|
||||||
|
- Yes.
|
||||||
|
- No.
|
||||||
|
- Too soon to tell, but I suspect I will.
|
||||||
|
- Too soon to tell, but I suspect I won't.
|
||||||
|
- Too soon to tell, and I couldn't say whether I will or won't.
|
||||||
|
|
||||||
|
## Effective Altruism
|
||||||
|
Had you heard the term "Effective Altruism" before?
|
||||||
|
- Yes.
|
||||||
|
- No.
|
||||||
|
(Don't give a "maybe" option.)
|
||||||
|
|
||||||
|
(If no: skip everything)
|
||||||
|
|
||||||
|
(If yes:)
|
||||||
|
Without checking a source, how would you define the concept?
|
||||||
|
|
||||||
|
In a scale from 0 to 10, where 8,9 and 10 indicate a very positive opinion; 0,1, and 2 a very negative opinion; and 3 through 7 are in between: What's your overall opinion of Effective Altruism?
|
||||||
|
|
||||||
|
Have you previously heard of any of the following organizations? (select all that apply)
|
||||||
|
- GiveWell
|
||||||
|
- Center for Effective Altruism
|
||||||
|
- 80,000h
|
||||||
|
- EvidenceAction
|
||||||
|
- Against Malaria Foundation
|
||||||
|
- add previous GW top charities
|
||||||
|
|
||||||
|
(if at least one:)
|
||||||
|
Have you made any donations to any of those organizations?
|
||||||
|
- Yes
|
||||||
|
- No
|
||||||
|
- Not personally, but I'm nonetheless causally responsable for a donation being made.
|
||||||
|
|
||||||
|
(If yes, or c):)
|
||||||
|
What amount?
|
||||||
|
|
||||||
|
(if at least 6 in opinion of EA:)
|
||||||
|
In the future, do you expect to donate to organizations which fall under the umbrella of Effective Altruism, such as the ones mentioned previously?
|
||||||
|
- Yes.
|
||||||
|
- No.
|
||||||
|
|
||||||
|
(If yes: Approximately, how much do you expect your total life donations to be?)
|
||||||
|
|
||||||
|
From 0% to 100%, how likely do you judge it that you will work for an EA organization?
|
||||||
|
|
||||||
|
## Existential risk.
|
||||||
|
Have you heard the term "existential risk" before?
|
||||||
|
|
||||||
|
(If no: skip everything).
|
||||||
|
|
||||||
|
(If yes) Without searching the internet, looking at Wikipedia, etc., how would you describe the concept?
|
||||||
|
|
||||||
|
Consider a scale from 0 to 10, where 8,9 and 10 are the highest importance; 0,1, and 2 are low importance; and 3 through 7 are in between. What number would you give to the importance of existential risk?
|
||||||
|
|
||||||
|
In that same 10 point intensity scale, how interested are you in it?
|
||||||
|
|
||||||
|
(If higher than 5) Have you read any papers, articles or books related to the topic?
|
||||||
|
|
||||||
|
(If yes) Can you mention some of them?
|
||||||
|
|
||||||
|
(If higher than 5) In percentage points, how likely do you judge it that your future career will in some way be related to existential risk?
|
||||||
|
|
||||||
|
( Does not apply to CFAR:
|
||||||
|
## Other instrumental goal:
|
||||||
|
- Are you aiming to go to university?
|
||||||
|
- Rank by admission. Do espr people go to more prestigious universities?
|
||||||
|
)
|
||||||
135
ESPR-Evaluation/Write-up.md
Normal file
|
|
@ -0,0 +1,135 @@
|
||||||
|
# ESPR-Evaluation Writeup
|
||||||
|
|
||||||
|
{
|
||||||
|
Epistemic status: Cognitive dissonance. Deindexed. Please delay making a decision based on whatever you have read.
|
||||||
|
Do not distribute until I'm significantly more sure about conclusions.
|
||||||
|
Why does CFAR measure it's impact the way it does?
|
||||||
|
Note: The question whose answer I consider here is not "Should I donate to CFAR?".
|
||||||
|
}
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
I have spent the last 2-4 months thinking about how to evaluate the impact of the European Summer Camp on Rationality (ESPR) [1], a selective program affiliated with CFAR (Center for Applied Rationality) which takes brilliant highschoolers and teach thems a variety of rationality techniques. Here are the highlights of what I have found, as well as some remarks on what CFAR could do if it was interested in measuring impact with a randomized controlled trial (an RCT).
|
||||||
|
|
||||||
|
After considering the logical model and the current literature, I make a note on the perverse incentives which OpenPhilantrophy might be giving CFAR, and present the result of some power calculations regarding the feasibility of an RCT for ESPR. I then go through some important details of how an RCT would have to be implemented, consider some ways I could make the world a worse place through this project, and conclude with some notes for the future.
|
||||||
|
|
||||||
|
## Current evidence
|
||||||
|
|
||||||
|
### Logical model
|
||||||
|
On ESPR itself, there isn't much evidence, besides it's logical model, i.e., the proposed pathway to change. In the words of a student which came back this year as a Junior Counselor:
|
||||||
|
|
||||||
|
>... ESPR (teaches) smart people not to make stupid mistakes. Examples: betting, prediction markets decrease overconfidence. Units of exchange class decreases likelihood of spending time, money, other currency in counterproductive ways. The whole asking for examples thing prevents people from hiding behind abstract terms and to pretend to understand something when they don't. Some of this is learned in classes. A lot of good techniques from just interacting with people at espr.
|
||||||
|
>
|
||||||
|
>I've had conversations with otherwise really smart people and thought “you wouldn't be stuck with those beliefs if you'd gone though two weeks of espr”
|
||||||
|
>
|
||||||
|
>ESPR also increases self-awareness. A lot of espr classes / techniques / culture involves noticing things that happen in your head. This is good for avoiding stupid mistakes and also for getting better at accomplishing things.
|
||||||
|
>
|
||||||
|
>It is nice to be surrounded by very smart. ambitious people. This might be less relevant for people who do competitions like IMO or go to very selective universities. Personally, it is a fucking awesome and rare experience every time I meet someone really smart with a bearable personality in the real world. Being around lots of those people at espr was awesome. Espr might have made a lot of participants consider options they wouldn't seriously have before talking to the instructors like founding a startup, working on ai alignment, everything that galit talked about etc
|
||||||
|
>
|
||||||
|
>espr also increased positive impact participants will have on the world in the future by introducing them to effective altruism ideas. I think last year’s batch would have been affected more by this because I remember there being more on x-risk and prioritizing causes and stuff [2].
|
||||||
|
|
||||||
|
|
||||||
|
### The Studies CFAR has conducted.
|
||||||
|
|
||||||
|
CFAR and ESPR have very similar logical models, so the current hard evidence on ESPR, i.e, a literature review, would simply be the evidence CFAR has on itself. I've mainly studied [CFAR's 2015 Longitudinal Study](http://www.rationality.org/studies/2015-longitudinal-study) together with the more recent [Case Studies](http://rationality.org/studies/2016-case-studies) and the [2017 CFAR Impact report](http://www.rationality.org/resources/updates/2017/cfar-2017-impact-report). I am not aware of any more studies, besides a low powered unpublished and unfindable 2012 RCT.
|
||||||
|
|
||||||
|
I find myself confused, in the sense that I don't find those studies very satisfactory, and I wouldn't go about collecting evidence in the same way. On the other hand, I respect these people, and I may be under the effects of tunnel vision after having been reading about RCTs for a couple of months. Alternatively, it could be that their Data Analyst is normally a regular member of staff / ops person [3], and that justifying their impact is not a priority for this relatively young organization. On this last point,
|
||||||
|
|
||||||
|
With regards to the first study, it notes that a control group would be a difficult thing to implement, because it would be necessary to find people who would like to come to the program and forbidding them to do so. The study tries to compensate for the lack of a control by being statistically clever. It seems to be rigorous enough for a study which is not an RCT, although
|
||||||
|
|
||||||
|
But I feel like that is only partially sufficient. The magnitude of the effect found could be wildly overestimated; MIT's Abdul Latif Jameel Poverty Action Lab provides the following slides [4]:
|
||||||
|
|
||||||
|

|
||||||
|

|
||||||
|
|
||||||
|
I find them scary; depending on the method used to test your effect, you can get an effect size that is 4-5 times as great as the effect you find with an RCT, or about as great, in the other direction. The effects the CFAR study finds, f.ex. the one most prominently displayed in CFAR's webpage, an increased life satisfaction of 0.17 standard deviations (i.e., going from 50 to 56.75%) are small enough for me to worry about such inconveniences.
|
||||||
|
|
||||||
|
Recently, CFAR has moved away from that more rigorous kind of study to Case Studies and Student Profiles. This annoys me, because asking participants for counterfactual estimations is such a swamp of complexity and complications that the error bars are bound to be incredibly wide, and thus most of the impact probably comes from the uncertainty. Additionally, it is just very easy to get very positive reviews of mostly anything; searching for "nonviolent communication testimonials" brings up [this webpage](https://www.rachellelamb.com/testimonials/). In other words, I would expect to find similar texts at mostly any level of impact.
|
||||||
|
|
||||||
|
Finally, one their three Organization Case Studies (Arbital) is now a failed project, but this doesn't change my mind much, because learning that a sparky person who attended CFAR founded a project to improve some aspect of the world didn't give me much information to begin with.
|
||||||
|
|
||||||
|
### A note on perverse incentives
|
||||||
|
To the extent that OpenPhilantropy prefers Case Studies and other weak forms of evidence *now*, rather than stronger evidence two to five years later, OpenPhilantropy might be giving ESPR perverse incentives. Note that with 20-30 students per year, even after we start an RCT, there must pass a number of years before we can amass some meaningful statistical power (see the power calculations). On the other hand, taking a process of iterated improvement as an admission of failure would also be pretty shitty.
|
||||||
|
|
||||||
|
The questions designing a RCT poses are hard, but the bigger problem is that there's an incentive to not ask them at all. But that would be agaist CFAR's ethos.
|
||||||
|
|
||||||
|
## An RCT for ESPR
|
||||||
|
|
||||||
|
### Is it desirable? Is it needed? Is it a superior alternative?
|
||||||
|
On the one hand, ESPR's logical model seems to be very robust. On the other hand, William MacAskill's book *Doing Good Better* is ripe with examples of NGOs which seem to have a convincing logical model but which don't turn out to be very effective. In this position, in which the outside view seems to be of great uncertainty, an actual study seems highly desirable, and of the ways to do them, an RCT is the superior epistemical alternative; i.e., if you can do any type of study, you should choose to do an RCT, and if I was calling the shots, I would go for it. Yet I am not, and thus I can't.
|
||||||
|
|
||||||
|
In the end, the answer depends on who CFAR / ESPR has to justify itself to, and what kind of evidence they want, as well as on whether they want to convince outsiders that they are effective. These questions will be answered by CFAR's leadership, not by me. Below, the question I have started to answer is whether it could be done.
|
||||||
|
|
||||||
|
### Some power calculations.
|
||||||
|
(For more detailed numbers, see: [the actual numbers](https://nunosempere.github.io/ESPR-Evaluation/3-Power-calculations.html))
|
||||||
|
|
||||||
|
Even after 4 years, under the most optimistic population projections (i.e., every participant answers our surveys every year, and 60 students who didn't get selected also do), we wouldn't have enough power to detect an effect size of 0.2 standard deviations with significance level = 0.05. We would, under somewhat less optimistic projections (20 students and 20 individuals in the control group answer every year), be able to detect an effect of 0.5 standard deviations within 4 years, in whatever we measure.
|
||||||
|
|
||||||
|
At any point, the length the RCT would have to go on would depend on the minimal detectable effect per unit of money we care about. Some relevant data is that every interation of ESPR costs upwards of $150,000, or $5,000 per student, and there is nothing magical about a 0.05 significance level. The full bayesian treatment will have to wait until I have my computer back.
|
||||||
|
|
||||||
|
At any point, if we only cared about frequentist statistical power, it would be much better if an RCT could be carried out by CFAR on its workshops, because they have more students.
|
||||||
|
|
||||||
|
### Details of the implementation
|
||||||
|
|
||||||
|
#### Talking with the staff about whether an RCT is a good idea.
|
||||||
|
|
||||||
|
Without the support of ESPR's staff, an RCT could not go forward. In particular, an RCT will require that we don't accept promising applicants, i.e., from the 2 most promising applicants, we'd want to have 1 in the control group. This to be a forced decision would probably engender great resentment.
|
||||||
|
|
||||||
|
Similarly, though we would prefer to have smaller groups, of 20, we wouldn't have enough power, even after 4 years if we went that route. Instead, we'd want to accept upwards of 32 students (-2 who, on expectation, won't get their visa on time). Other design studies, like ranking our applicants from 1 to 40, taking the best 20 and randomizing the last 20 (10 for ESPR, 10 for the control group) would appease the staff, but again wouldn't buy us enough power.
|
||||||
|
|
||||||
|
If we want our final alumni pool to be equally as good as in previous years, we would want to increase our reach, our advertising efforts say ~4x, i.e., to find 90 excellent students in total, 60 for the control and 30 for the treatment group (and 30 spares). This would be possible by, f.ex., asking every previous participant to nominate a friend, by announcing the camp to the most prestigious highschools in countries with a rationality community, etc. An SSC post / banner wouldn't hurt. A successful effort in this area seems necessary for the full buy in of the staff, and might require additional funds.
|
||||||
|
|
||||||
|
#### Spillovers.
|
||||||
|
|
||||||
|
If a promising person from the control group tried to apply the next year, we'd have to deny them the chance to come, or else lose the most promising people from the control group, losing validity.
|
||||||
|
|
||||||
|
We also don't want people on the control group to be disheartened because they didn't get in. For this, I suggest dividing our application in two steps: One in which we select both groups, and a coin toss.
|
||||||
|
|
||||||
|
If people have heard about ESPR, they might read writings by Kahneman, Bostrom, Yudkowsky, et al. If they aren't accepted, they might fulfill their need for cognition by continuing reading such materials. Thus, what we will measure will be the difference between applicants interested in rationality and applicants interested in rationality who go to ESPR, not between equally talented people with no previous contact. At any point, it would seem necessary to disallow explicit mentoring of applicants. Here, again, the full buy in of the staff is needed.
|
||||||
|
|
||||||
|
SPARC is another camp which teaches very similar stuff. I have considered doing the RCT both on ESPR and SPARC at the same time, but SPARC's emphasis on math olympiad people makes that a little bit sketchy. However, because they are still very similar interventions, we don't want to have a person in the control group going to SPARC. This might be a sore point.
|
||||||
|
|
||||||
|
#### Stratification.
|
||||||
|
|
||||||
|
Suppose that after randomly allocating the students, we found that the treatment group was richer. This would *suck*, because maybe our effect is just them being, f.ex., healthier. In expectation, the two groups are the same, but maybe in practice they turn out not to be.
|
||||||
|
|
||||||
|
An alternative would be to divide the students into rich and poor, and randomly choose in each bucket. This is refered to as stratification, and buys additional power, though I still have to get into the gritty details. I'm still thinking about along which variables we want to stratify, if at all, and further reflection is needed.
|
||||||
|
|
||||||
|
Note to self: Paired random assignment might be a problem with respect to attrition (f.ex. no visa on time); JPAL recommends strata of at least 4 people.
|
||||||
|
|
||||||
|
#### Incentives.
|
||||||
|
The survey takes 15-30 minutes to complete, and while I've tried to make it engaging and propose pauses, I think that an incentive is needed (i.e., the people in the control group might tell us to fuck off).
|
||||||
|
|
||||||
|
I initially thought about donating X USD to the AMF in their name every time they completed a survey, but I realized that this would motivate the most altruistical individuals the most, thus getting selection effects. Now, I'm leaning towards just giving the survey takers that amount of money.
|
||||||
|
|
||||||
|
As a lower bound, 40 people * 3 years * 2 surveys * 10 USD = 2400 USD, or 800 USD/year, as an upper bound, 60 people * 4 years * 4 surveys * 15 USD = 14400 USD or 3600 USD / year. I don't feel this is that significant in comparison to the total cost of the camp. More expensive, I think, is the time which I and others would work on this for free / the counterfactual projects we might undertake with that time. I am as of yet uncertain of the weight of this factor.
|
||||||
|
|
||||||
|
#### Take off and burn.
|
||||||
|
|
||||||
|
There is a noninsignificant probability that the first year of the RTC we realize we've made a number of grievous mistakes. I.e., it would surprise me if everything went without a hitch the first time. Personally, this only worries me if we don't learn enough to be able to pull it off the next year, which I happen to consider rather unlikely. At any point, it might be useful to categorize the first year as a trial run.
|
||||||
|
|
||||||
|
If that risk is unacceptable, we could partner with someone like IDInsight, MIT's JPAL, etc. The problem is that those organizations specialize in development interventions. It wouldn't hurt to ask, though.
|
||||||
|
|
||||||
|
## Potential negative impact
|
||||||
|
How could this project make the world a worse place?
|
||||||
|
- The study could end up being low powered, generating polemic.
|
||||||
|
- The study could be interrupted midway, generating polemic.
|
||||||
|
- Different attitudes towards RCTs between ESPR volunteers and CFAR higher-ups might generate a schism, or resentment.
|
||||||
|
- Volunteers would be needed who could be doing more impactful projects.
|
||||||
|
- Funding for ESPR could be used for more impactful projects.
|
||||||
|
- I could have no fucking idea what I'm talking about with regards to the current evidence (this is why this document is not linked on my main page), and make CFAR/ESPR lose badly needed funding.
|
||||||
|
- It would be terrible if the results were negative, but CFAR didn't agree with the measurement device used.
|
||||||
|
|
||||||
|
## Next steps.
|
||||||
|
1. Measurements. My (current measuring device)[https://nunosempere.github.io/ESPR-Evaluation/4-Measurements.html] is imperfect, having been devised by myself. For every section, find an expert and have them propose a better way to measure what we care about.
|
||||||
|
2. Contact IDInsights and MIT's JPAL and ask them whether they would be interested in a partnership.
|
||||||
|
3. Have CFAR ponder and question their current impact evaluation strategy. Is justifying their impact to outsiders a priority?
|
||||||
|
|
||||||
|
## Conclusion.
|
||||||
|
CFAR does not currently prioritize producing the kind of evidence which I would find satisfying, but it can have valid reasons to do so, f.ex., saving the world. On the other hand, consider negative publication bias. Furthermore, if a big study were conducted, and CFAR was shown to be ineffective, it wouldn't surprise me. For everyone else, it would have been obvious in retrospect. More research is needed, perhaps an RCT.
|
||||||
|
|
||||||
|
## Footnotes:
|
||||||
|
[1] of which I was an alumni and then JC. https://espr-camp.org/
|
||||||
|
[2] I didn't want to remove criticism.
|
||||||
|
[3] I am very confused about this. I know that his role at EuroSparc (ESPR 1.0) was as an ops person.
|
||||||
|
[4] Obtained from MIT's course *Evaluating Social Programs* (Week 3), accessible at https://courses.edx.org/courses/course-v1:MITx+JPAL101x+2T2018/course/.
|
||||||
|
|
||||||
9
ESPR-Evaluation/readme.md
Normal file
|
|
@ -0,0 +1,9 @@
|
||||||
|
# ESPR Evaluation
|
||||||
|
|
||||||
|
[1. Current Evidence](https://nunosempere.github.io/ESPR-Evaluation/1-Current-Evidence.html)
|
||||||
|
|
||||||
|
[2. Power Calculations](https://nunosempere.github.io/ESPR-Evaluation/3-Power-calculations.html)
|
||||||
|
|
||||||
|
[3. Measurement](https://nunosempere.github.io/ESPR-Evaluation/Questionnaire-stable.html)
|
||||||
|
|
||||||
|
[4. Details of the implementation](https://nunosempere.github.io/ESPR-Evaluation/Questionnaire-stable.html)
|
||||||
BIN
Photo.jpeg
Normal file
{kind=link}
|
After Width: | Height: | Size: 48 KiB |
|
|
@ -1 +1,3 @@
|
||||||
title: Nuño
|
theme: jekyll-theme-cayman
|
||||||
|
title: Nuño Sempere
|
||||||
|
description: Measure is unceasing
|
||||||
|
|
|
||||||
47
_layouts/default.html
Normal file
|
|
@ -0,0 +1,47 @@
|
||||||
|
<!DOCTYPE html>
|
||||||
|
<html lang="{{ site.lang | default: "en-US" }}">
|
||||||
|
<head>
|
||||||
|
|
||||||
|
{% if site.google_analytics %}
|
||||||
|
<script async src="https://www.googletagmanager.com/gtag/js?id={{ site.google_analytics }}"></script>
|
||||||
|
<script>
|
||||||
|
window.dataLayer = window.dataLayer || [];
|
||||||
|
function gtag(){dataLayer.push(arguments);}
|
||||||
|
gtag('js', new Date());
|
||||||
|
gtag('config', '{{ site.google_analytics }}');
|
||||||
|
</script>
|
||||||
|
{% endif %}
|
||||||
|
<meta charset="UTF-8">
|
||||||
|
<script async defer data-domain="nunosempere.github.io" src="https://plausible.io/js/plausible.js"></script>
|
||||||
|
{% seo %}
|
||||||
|
<meta name="viewport" content="width=device-width, initial-scale=1">
|
||||||
|
<meta name="theme-color" content="#157878">
|
||||||
|
<meta name="apple-mobile-web-app-status-bar-style" content="black-translucent">
|
||||||
|
<link rel="stylesheet" href="{{ '/assets/css/style.css?v=' | append: site.github.build_revision | relative_url }}">
|
||||||
|
</head>
|
||||||
|
<body>
|
||||||
|
<header class="page-header" role="banner">
|
||||||
|
<h1 class="project-name">Nuño Sempere</h1>
|
||||||
|
<br>
|
||||||
|
<img class="rounded" src="https://nunosempere.github.io/assets/PhotoCropped.jpeg" alt="Avatar" style="width:300px">
|
||||||
|
<h2 class="project-tagline">{{ page.description | default: site.description | default: site.github.project_tagline }}</h2>
|
||||||
|
{% if site.github.is_project_page %}
|
||||||
|
<a href="{{ site.github.repository_url }}" class="btn">View on GitHub</a>
|
||||||
|
{% endif %}
|
||||||
|
{% if site.show_downloads %}
|
||||||
|
<a href="{{ site.github.zip_url }}" class="btn">Download .zip</a>
|
||||||
|
<a href="{{ site.github.tar_url }}" class="btn">Download .tar.gz</a>
|
||||||
|
{% endif %}
|
||||||
|
</header>
|
||||||
|
|
||||||
|
<main id="content" class="main-content" role="main">
|
||||||
|
{{ content }}
|
||||||
|
|
||||||
|
<footer class="site-footer">
|
||||||
|
{% if site.github.is_project_page %}
|
||||||
|
<span class="site-footer-owner"><a href="{{ site.github.repository_url }}">{{ site.github.repository_name }}</a> is maintained by <a href="{{ site.github.owner_url }}">{{ site.github.owner_name }}</a>.</span>
|
||||||
|
{% endif %}
|
||||||
|
</footer>
|
||||||
|
</main>
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
BIN
assets/Photo.jpeg
Normal file
{kind=link}
|
After Width: | Height: | Size: 284 KiB |
BIN
assets/PhotoCropped.jpeg
Normal file
{kind=link}
|
After Width: | Height: | Size: 253 KiB |
BIN
assets/fonts/Computer Modern Bright.zip
Normal file
225
assets/fonts/ComputerModernBright/OFL-FAQ.txt
Normal file
|
|
@ -0,0 +1,225 @@
|
||||||
|
OFL FAQ - Frequently Asked Questions about the SIL Open Font License (OFL)
|
||||||
|
Version 1.1 - 26 February 2007
|
||||||
|
(See http://scripts.sil.org/OFL for updates)
|
||||||
|
|
||||||
|
|
||||||
|
1 ABOUT USING AND DISTRIBUTING FONTS LICENSED UNDER THE OFL
|
||||||
|
|
||||||
|
1.1 Can I use the fonts in any publication, even embedded in the file?
|
||||||
|
Yes. You may use them like most other fonts, but unlike some fonts you may include an embedded subset of the fonts in your document. Such use does not require you to include this license or other files (listed in OFL condition 2), nor does it require any type of acknowledgement within the publication. Some mention of the font name within the publication information (such as in a colophon) is usually appreciated. If you wish to include the complete font as a separate file, you should distribute the full font package, including all existing acknowledgements, and comply with the OFL conditions. Of course, referencing or embedding an OFL font in any document does not change the license of the document itself. The requirement for fonts to remain under the OFL does not apply to any document created using the fonts and their derivatives. Similarly, creating any kind of graphic using a font under OFL does not make the resulting artwork subject to the OFL.
|
||||||
|
|
||||||
|
1.2 Can I make web pages using these fonts?
|
||||||
|
Yes! Go ahead! Using CSS (Cascading Style Sheets) is recommended.
|
||||||
|
|
||||||
|
1.3 Can I make the fonts available to others from my web site?
|
||||||
|
Yes, as long as you meet the conditions of the license (do not sell by itself, include the necessary files, rename Modified Versions, do not abuse the Author(s)' name(s) and do not sublicense).
|
||||||
|
|
||||||
|
1.4 Can the fonts be included with Free/Libre and Open Source Software collections such as GNU/Linux and BSD distributions?
|
||||||
|
Yes! Fonts licensed under the OFL can be freely aggregated with software under FLOSS (Free/Libre and Open Source Software) licenses. Since fonts are much more useful aggregated to than merged with existing software, possible incompatibility with existing software licenses is not a problem. You can also repackage the fonts and the accompanying components in a .rpm or .deb package and include them in distro CD/DVDs and online repositories.
|
||||||
|
|
||||||
|
1.5 I want to distribute the fonts with my program. Does this mean my program also has to be free and open source software?
|
||||||
|
No. Only the portions based on the font software are required to be released under the OFL. The intent of the license is to allow aggregation or bundling with software under restricted licensing as well.
|
||||||
|
|
||||||
|
1.6 Can I include the fonts on a CD of freeware or commercial fonts?
|
||||||
|
Yes, as long some other font or software is also on the disk, so the OFL font is not sold by itself.
|
||||||
|
|
||||||
|
1.7 Can I sell a software package that includes these fonts?
|
||||||
|
Yes, you can do this with both the Original Version and a Modified Version. Examples of bundling made possible by the OFL would include: word processors, design and publishing applications, training and educational software, edutainment software, etc.
|
||||||
|
|
||||||
|
1.8 Why won't the OFL let me sell the fonts alone?
|
||||||
|
The intent is to keep people from making money by simply redistributing the fonts. The only people who ought to profit directly from the fonts should be the original authors, and those authors have kindly given up potential direct income to distribute their fonts under the OFL. Please honor and respect their contribution!
|
||||||
|
|
||||||
|
1.9 I've come across a font released under the OFL. How can I easily get more information about the Original Version? How can I know where it stands compared to the Original Version or other Modified Versions?
|
||||||
|
Consult the copyright statement(s) in the license for ways to contact the original authors. Consult the FONTLOG for information on how the font differs from the Original Version, and get in touch with the various contributors via the information in the acknowledgment section. Please consider using the Original Versions of the fonts whenever possible.
|
||||||
|
|
||||||
|
1.10 What do you mean in condition 4? Can you provide examples of abusive promotion / endorsement / advertisement vs. normal acknowledgement?
|
||||||
|
The intent is that the goodwill and reputation of the author(s) should not be used in a way that makes it sound like the original author(s) endorse or approve of a specific Modified Version or software bundle. For example, it would not be right to advertise a word processor by naming the author(s) in a listing of software features, or to promote a Modified Version on a web site by saying "designed by ...". However, it would be appropriate to acknowledge the author(s) if your software package has a list of people who deserve thanks. We realize that this can seem to be a gray area, but the standard used to judge an acknowledgement is that if the acknowledgement benefits the author(s) it is allowed, but if it primarily benefits other parties, or could reflect poorly on the author(s), then it is not.
|
||||||
|
|
||||||
|
|
||||||
|
2 ABOUT MODIFYING OFL LICENSED FONTS
|
||||||
|
|
||||||
|
2.1 Can I change the fonts? Are there any limitations to what things I can and cannot change?
|
||||||
|
You are allowed to change anything, as long as such changes do not violate the terms of the license. In other words, you are not allowed to remove the copyright statement(s) from the font, but you could add additional information into it that covers your contribution.
|
||||||
|
|
||||||
|
2.2 I have a font that needs a few extra glyphs - can I take them from an OFL licensed font and copy them into mine?
|
||||||
|
Yes, but if you distribute that font to others it must be under the OFL, and include the information mentioned in condition 2 of the license.
|
||||||
|
|
||||||
|
2.3 Can I charge people for my additional work? In other words, if I add a bunch of special glyphs and/or OpenType/Graphite code, can I sell the enhanced font?
|
||||||
|
Not by itself. Derivative fonts must be released under the OFL and cannot be sold by themselves. It is permitted, however, to include them in a larger software package (such as text editors, office suites or operating systems), even if the larger package is sold. In that case, you are strongly encouraged, but not required, to also make that derived font easily and freely available outside of the larger package.
|
||||||
|
|
||||||
|
2.4 Can I pay someone to enhance the fonts for my use and distribution?
|
||||||
|
Yes. This is a good way to fund the further development of the fonts. Keep in mind, however, that if the font is distributed to others it must be under the OFL. You won't be able to recover your investment by exclusively selling the font, but you will be making a valuable contribution to the community. Please remember how you have benefitted from the contributions of others.
|
||||||
|
|
||||||
|
2.5 I need to make substantial revisions to the font to make it work with my program. It will be a lot of work, and a big investment, and I want to be sure that it can only be distributed with my program. Can I restrict its use?
|
||||||
|
No. If you redistribute a Modified Version of the font it must be under the OFL. You may not restrict it in any way. This is intended to ensure that all released improvements to the fonts become available to everyone. But you will likely get an edge over competitors by being the first to distribute a bundle with the enhancements. Again, please remember how you have benefitted from the contributions of others.
|
||||||
|
|
||||||
|
2.6 Do I have to make any derivative fonts (including source files, build scripts, documentation, etc.) publicly available?
|
||||||
|
No, but please do share your improvements with others. You may find that you receive more than what you gave in return.
|
||||||
|
|
||||||
|
2.7 Why can't I use the Reserved Font Name(s) in my derivative font names? I'd like people to know where the design came from.
|
||||||
|
The best way to acknowledge the source of the design is to thank the original authors and any other contributors in the files that are distributed with your revised font (although no acknowledgement is required). The FONTLOG is a natural place to do this. Reserved Font Name(s) ensure that the only fonts that have the original names are the unmodified Original Versions. This allows designers to maintain artistic integrity while allowing collaboration to happen. It eliminates potential confusion and name conflicts. When choosing a name be creative and avoid names that reuse almost all the same letters in the same order or sound like the original. Keep in mind that the Copyright Holder(s) can allow a specific trusted partner to use Reserved Font Name(s) through a separate written agreement.
|
||||||
|
|
||||||
|
2.8 What do you mean by "primary name as presented to the user"? Are you referring to the font menu name?
|
||||||
|
Yes, the requirement to change the visible name used to differentiate the font from others applies to the font menu name and other mechanisms to specify a font in a document. It would be fine, for example, to keep a text reference to the original fonts in the description field, in your modified source file or in documentation provided alongside your derivative as long as no one could be confused that your modified source is the original. But you cannot use the Reserved Font Names in any way to identify the font to the user (unless the Copyright Holder(s) allow(s) it through a separate agreement; see section 2.7). Users who install derivatives ("Modified Versions") on their systems should not see any of the original names ("Reserved Font Names") in their font menus, for example. Again, this is to ensure that users are not confused and do not mistake a font for another and so expect features only another derivative or the Original Version can actually offer. Ultimately, creating name conflicts will cause many problems for the users as well as for the designer of both the Original and Modified versions, so please think ahead and find a good name for your own derivative. Font substitution systems like fontconfig, or application-level font fallback configuration within OpenOffice.org or Scribus, will also get very confused if the name of the font they are configured to substitute to actually refers to another physical font on the user's hard drive. It will help everyone if Original Versions and Modified Versions can easily be distinguished from one another and from other derivatives. The substitution mechanism itself is outside the scope of the license. Users can always manually change a font reference in a document or set up some kind of substitution at a higher level but at the lower level the fonts themselves have to respect the Reserved Font Name(s) requirement to prevent ambiguity. If a substitution is currently active the user should be aware of it.
|
||||||
|
|
||||||
|
2.9 Am I not allowed to use any part of the Reserved Font Names?
|
||||||
|
You may not use the words of the font names, but you would be allowed to use parts of words, as long as you do not use any word from the Reserved Font Names entirely. We do not recommend using parts of words because of potential confusion, but it is allowed. For example, if "Foobar" was a Reserved Font Name, you would be allowed to use "Foo" or "bar", although we would not recommend it. Such an unfortunate choice would confuse the users of your fonts as well as make it harder for other designers to contribute.
|
||||||
|
|
||||||
|
2.10 So what should I, as an author, identify as Reserved Font Names?
|
||||||
|
Original authors are encouraged to name their fonts using clear, distinct names, and only declare the unique parts of the name as Reserved Font Names. For example, the author of a font called "Foobar Sans" would declare "Foobar" as a Reserved Font Name, but not "Sans", as that is a common typographical term, and may be a useful word to use in a derivative font name. Reserved Font Names should also be single words. A font called "Flowing River" should have Reserved Font Names "Flowing" and "River", not "Flowing River".
|
||||||
|
|
||||||
|
2.11 Do I, as an author, have to identify any Reserved Font Names?
|
||||||
|
No, but we strongly encourage you to do so. This is to avoid confusion between your work and Modified versions. You may, however, give certain trusted parties the right to use any of your Reserved Font Names through separate written agreements. For example, even if "Foobar" is a RFN, you could write up an agreement to give company "XYZ" the right to distribute a modified version with a name that includes "Foobar". This allows for freedom without confusion.
|
||||||
|
|
||||||
|
2.12 Are any names (such as the main font name) reserved by default?
|
||||||
|
No. That is a change to the license as of version 1.1. If you want any names to be Reserved Font Names, they must be specified after the copyright statement(s).
|
||||||
|
|
||||||
|
2.13 What is this FONTLOG thing exactly?
|
||||||
|
It has three purposes: 1) to provide basic information on the font to users and other developers, 2) to document changes that have been made to the font or accompanying files, either by the original authors or others, and 3) to provide a place to acknowledge the authors and other contributors. Please use it! See below for details on how changes should be noted.
|
||||||
|
|
||||||
|
2.14 Am I required to update the FONTLOG?
|
||||||
|
No, but users, designers and other developers might get very frustrated at you if you don't! People need to know how derivative fonts differ from the original, and how to take advantage of the changes, or build on them.
|
||||||
|
|
||||||
|
|
||||||
|
3 ABOUT THE FONTLOG
|
||||||
|
|
||||||
|
The FONTLOG can take a variety of formats, but should include these four sections:
|
||||||
|
|
||||||
|
3.1 FONTLOG for <FontFamilyName>
|
||||||
|
This file provides detailed information on the <FontFamilyName> font software. This information should be distributed along with the <FontFamilyName> fonts and any derivative works.
|
||||||
|
|
||||||
|
3.2 Basic Font Information
|
||||||
|
(Here is where you would describe the purpose and brief specifications for the font project, and where users can find more detailed documentation. It can also include references to how changes can be contributed back to the Original Version. You may also wish to include a short guide to the design, or a reference to such a document.)
|
||||||
|
|
||||||
|
3.3 ChangeLog
|
||||||
|
(This should list both major and minor changes, most recent first. Here are some examples:)
|
||||||
|
|
||||||
|
7 February 2007 (Pat Johnson) <NewFontFamilyName> Version 1.3
|
||||||
|
- Added Greek and Cyrillic glyphs
|
||||||
|
- Released as "<NewFontFamilyName>"
|
||||||
|
|
||||||
|
7 March 2006 (Fred Foobar) <NewFontFamilyName> Version 1.2
|
||||||
|
- Tweaked contextual behaviours
|
||||||
|
- Released as "<NewFontFamilyName>"
|
||||||
|
|
||||||
|
1 Feb 2005 (Jane Doe) <NewFontFamilyName> Version 1.1
|
||||||
|
- Improved build script performance and verbosity
|
||||||
|
- Extended the smart code documentation
|
||||||
|
- Corrected minor typos in the documentation
|
||||||
|
- Fixed position of combining inverted breve below (U+032F)
|
||||||
|
- Added OpenType/Graphite smart code for Armenian
|
||||||
|
- Added Armenian glyphs (U+0531 -> U+0587)
|
||||||
|
- Released as "<NewFontFamilyName>"
|
||||||
|
|
||||||
|
1 Jan 2005 (Joe Smith) <FontFamilyName> Version 1.0
|
||||||
|
- Initial release of font "<FontFamilyName>"
|
||||||
|
|
||||||
|
3.4 Acknowledgements
|
||||||
|
(Here is where contributors can be acknowledged.
|
||||||
|
|
||||||
|
If you make modifications be sure to add your name (N), email (E), web-address (W) and description (D). This list is sorted by last name in alphabetical order.)
|
||||||
|
|
||||||
|
N: Jane Doe
|
||||||
|
E: jane@university.edu
|
||||||
|
W: http://art.university.edu/projects/fonts
|
||||||
|
D: Contributor - Armenian glyphs and code
|
||||||
|
|
||||||
|
N: Fred Foobar
|
||||||
|
E: fred@foobar.org
|
||||||
|
W: http://foobar.org
|
||||||
|
D: Contributor - misc Graphite fixes
|
||||||
|
|
||||||
|
N: Pat Johnson
|
||||||
|
E: pat@fontstudio.org
|
||||||
|
W: http://pat.fontstudio.org
|
||||||
|
D: Designer - Greek & Cyrillic glyphs based on Roman design
|
||||||
|
|
||||||
|
N: Tom Parker
|
||||||
|
E: tom@company.com
|
||||||
|
W: http://www.company.com/tom/projects/fonts
|
||||||
|
D: Engineer - original smart font code
|
||||||
|
|
||||||
|
N: Joe Smith
|
||||||
|
E: joe@fontstudio.org
|
||||||
|
W: http://joe.fontstudio.org
|
||||||
|
D: Designer - original Roman glyphs
|
||||||
|
|
||||||
|
(Original authors can also include information here about their organization.)
|
||||||
|
|
||||||
|
|
||||||
|
4 ABOUT MAKING CONTRIBUTIONS
|
||||||
|
|
||||||
|
4.1 Why should I contribute my changes back to the original authors?
|
||||||
|
It would benefit many people if you contributed back to what you've received. Providing your contributions and improvements to the fonts and other components (data files, source code, build scripts, documentation, etc.) could be a tremendous help and would encourage others to contribute as well and 'give back', which means you will have an opportunity to benefit from other people's contributions as well. Sometimes maintaining your own separate version takes more effort than merging back with the original. Be aware that any contributions, however, must be either your own original creation or work that you own, and you may be asked to affirm that clearly when you contribute.
|
||||||
|
|
||||||
|
4.2 I've made some very nice improvements to the font, will you consider adopting them and putting them into future Original Versions?
|
||||||
|
Most authors would be very happy to receive such contributions. Keep in mind that it is unlikely that they would want to incorporate major changes that would require additional work on their end. Any contributions would likely need to be made for all the fonts in a family and match the overall design and style. Authors are encouraged to include a guide to the design with the fonts. It would also help to have contributions submitted as patches or clearly marked changes (the use of smart source revision control systems like subversion, svk or bzr is a good idea). Examples of useful contributions are bug fixes, additional glyphs, stylistic alternates (and the smart font code to access them) or improved hinting.
|
||||||
|
|
||||||
|
4.3 How can I financially support the development of OFL fonts?
|
||||||
|
It is likely that most authors of OFL fonts would accept financial contributions - contact them for instructions on how to do this. Such contributions would support future development. You can also pay for others to enhance the fonts and contribute the results back to the original authors for inclusion in the Original Version.
|
||||||
|
|
||||||
|
|
||||||
|
5 ABOUT THE LICENSE
|
||||||
|
|
||||||
|
5.1 I see that this is version 1.1 of the license. Will there be later changes?
|
||||||
|
Version 1.1 is the first minor revision of the OFL. We are confident that version 1.1 will meet most needs, but are open to future improvements. Any revisions would be for future font releases, and previously existing licenses would remain in effect. No retroactive changes are possible, although the Copyright Holder(s) can re-release the font under a revised OFL. All versions will be available on our web site: http://scripts.sil.org/OFL.
|
||||||
|
|
||||||
|
5.2 Can I use the SIL Open Font License for my own fonts?
|
||||||
|
Yes! We heartily encourage anyone to use the OFL to distribute their own original fonts. It is a carefully constructed license that allows great freedom along with enough artistic integrity protection for the work of the authors as well as clear rules for other contributors and those who redistribute the fonts. Some additional information about using the OFL is included at the end of this FAQ.
|
||||||
|
|
||||||
|
5.3 Does this license restrict the rights of the Copyright Holder(s)?
|
||||||
|
No. The Copyright Holder(s) still retain(s) all the rights to their creation; they are only releasing a portion of it for use in a specific way. For example, the Copyright Holder(s) may choose to release a 'basic' version of their font under the OFL, but sell a restricted 'enhanced' version. Only the Copyright Holder(s) can do this.
|
||||||
|
|
||||||
|
5.4 Is the OFL a contract or a license?
|
||||||
|
The OFL is a license and not a contract and so does not require you to sign it to have legal validity. By using, modifying and redistributing components under the OFL you indicate that you accept the license.
|
||||||
|
|
||||||
|
5.5 How about translating the license and the FAQ into other languages?
|
||||||
|
SIL certainly recognises the need for people who are not familiar with English to be able to understand the OFL and this FAQ better in their own language. Making the license very clear and readable is a key goal of the OFL.
|
||||||
|
|
||||||
|
If you are an experienced translator, you are very welcome to help by translating the OFL and its FAQ so that designers and users in your language community can understand the license better. But only the original English version of the license has legal value and has been approved by the community. Translations do not count as legal substitutes and should only serve as a way to explain the original license. SIL - as the author and steward of the license for the community at large - does not approve any translation of the OFL as legally valid because even small translation ambiguities could be abused and create problems.
|
||||||
|
|
||||||
|
We give permission to publish unofficial translations into other languages provided that they comply with the following guidelines:
|
||||||
|
|
||||||
|
- put the following disclaimer in both English and the target language stating clearly that the translation is unofficial:
|
||||||
|
|
||||||
|
"This is an unofficial translation of the SIL Open Font License into $language. It was not published by SIL International, and does not legally state the distribution terms for fonts that use the OFL. A release under the OFL is only valid when using the original English text.
|
||||||
|
|
||||||
|
However, we recognize that this unofficial translation will help users and designers not familiar with English to understand the SIL OFL better and make it easier to use and release font families under this collaborative font design model. We encourage designers who consider releasing their creation under the OFL to read the FAQ in their own language if it is available.
|
||||||
|
|
||||||
|
Please go to http://scripts.sil.org/OFL for the official version of the license and the accompanying FAQ."
|
||||||
|
|
||||||
|
- keep your unofficial translation current and update it at our request if needed, for example if there is any ambiguity which could lead to confusion.
|
||||||
|
|
||||||
|
If you start such a unofficial translation effort of the OFL and its accompanying FAQ please let us know, thank you.
|
||||||
|
|
||||||
|
|
||||||
|
6 ABOUT SIL INTERNATIONAL
|
||||||
|
|
||||||
|
6.1 Who is SIL International and what does it do?
|
||||||
|
SIL International is a worldwide faith-based education and development organization (NGO) that studies, documents, and assists in developing the world's lesser-known languages through literacy, linguistics, translation, and other academic disciplines. SIL makes its services available to all without regard to religious belief, political ideology, gender, race, or ethnic background. SIL's members and volunteers share a Christian commitment.
|
||||||
|
|
||||||
|
6.2 What does this have to do with font licensing?
|
||||||
|
The ability to read, write, type and publish in one's own language is one of the most critical needs for millions of people around the world. This requires fonts that are widely available and support lesser-known languages. SIL develops - and encourages others to develop - a complete stack of writing systems implementation components available under open licenses. This open stack includes input methods, smart fonts, smart rendering libraries and smart applications. There has been a need for a common open license that is specifically applicable to fonts and related software (a crucial component of this stack) so SIL developed the SIL Open Font License with the help of the FLOSS community.
|
||||||
|
|
||||||
|
6.3 How can I contact SIL?
|
||||||
|
Our main web site is: http://www.sil.org/
|
||||||
|
Our site about complex scripts is: http://scripts.sil.org/
|
||||||
|
Information about this license (including contact email information) is at: http://scripts.sil.org/OFL
|
||||||
|
|
||||||
|
|
||||||
|
7 ABOUT USING THE OFL FOR YOUR ORIGINAL FONTS
|
||||||
|
|
||||||
|
If you want to release your fonts under the OFL, you only need to do the following:
|
||||||
|
|
||||||
|
7.1 Put your copyright and reserved font names information in the beginning of the main OFL file.
|
||||||
|
7.2 Put your copyright and the OFL references in your various font files (such as in the copyright, license and description fields) and in your other components (build scripts, glyph databases, documentation, rendering samples, etc).
|
||||||
|
7.3 Write an initial FONTLOG for your font and include it in the release package.
|
||||||
|
7.4 Include the OFL in your release package.
|
||||||
|
7.5 We also highly recommend you include the relevant practical documentation on the license by putting the OFL-FAQ in your package.
|
||||||
|
7.6 If you wish, you can use the OFL Graphics on your web page.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
That's all. If you have any more questions please get in touch with us.
|
||||||
|
|
||||||
|
|
||||||
103
assets/fonts/ComputerModernBright/OFL.txt
Normal file
|
|
@ -0,0 +1,103 @@
|
||||||
|
Copyright (C) Authors of original metafont fonts:
|
||||||
|
Donald Ervin Knuth (cm, concrete fonts)
|
||||||
|
1995, 1996, 1997 J"org Knappen, 1990, 1992 Norbert Schwarz (ec fonts)
|
||||||
|
1992-2006 A.Khodulev, O.Lapko, A.Berdnikov, V.Volovich (lh fonts)
|
||||||
|
1997-2005 Claudio Beccari (cb greek fonts)
|
||||||
|
2002 FUKUI Rei (tipa fonts)
|
||||||
|
2003-2005 Han The Thanh (Vietnamese fonts)
|
||||||
|
1996-2005 Walter Schmidt (cmbright fonts)
|
||||||
|
|
||||||
|
Copyright (C) 2003-2009, Andrey V. Panov (panov@canopus.iacp.dvo.ru),
|
||||||
|
with Reserved Font Family Name "Computer Modern Unicode fonts".
|
||||||
|
|
||||||
|
This Font Software is licensed under the SIL Open Font License, Version 1.1.
|
||||||
|
This license is copied below, and is also available with a FAQ at:
|
||||||
|
http://scripts.sil.org/OFL
|
||||||
|
|
||||||
|
|
||||||
|
-----------------------------------------------------------
|
||||||
|
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
|
||||||
|
-----------------------------------------------------------
|
||||||
|
|
||||||
|
PREAMBLE
|
||||||
|
The goals of the Open Font License (OFL) are to stimulate worldwide
|
||||||
|
development of collaborative font projects, to support the font creation
|
||||||
|
efforts of academic and linguistic communities, and to provide a free and
|
||||||
|
open framework in which fonts may be shared and improved in partnership
|
||||||
|
with others.
|
||||||
|
|
||||||
|
The OFL allows the licensed fonts to be used, studied, modified and
|
||||||
|
redistributed freely as long as they are not sold by themselves. The
|
||||||
|
fonts, including any derivative works, can be bundled, embedded,
|
||||||
|
redistributed and/or sold with any software provided that any reserved
|
||||||
|
names are not used by derivative works. The fonts and derivatives,
|
||||||
|
however, cannot be released under any other type of license. The
|
||||||
|
requirement for fonts to remain under this license does not apply
|
||||||
|
to any document created using the fonts or their derivatives.
|
||||||
|
|
||||||
|
DEFINITIONS
|
||||||
|
"Font Software" refers to the set of files released by the Copyright
|
||||||
|
Holder(s) under this license and clearly marked as such. This may
|
||||||
|
include source files, build scripts and documentation.
|
||||||
|
|
||||||
|
"Reserved Font Name" refers to any names specified as such after the
|
||||||
|
copyright statement(s).
|
||||||
|
|
||||||
|
"Original Version" refers to the collection of Font Software components as
|
||||||
|
distributed by the Copyright Holder(s).
|
||||||
|
|
||||||
|
"Modified Version" refers to any derivative made by adding to, deleting,
|
||||||
|
or substituting -- in part or in whole -- any of the components of the
|
||||||
|
Original Version, by changing formats or by porting the Font Software to a
|
||||||
|
new environment.
|
||||||
|
|
||||||
|
"Author" refers to any designer, engineer, programmer, technical
|
||||||
|
writer or other person who contributed to the Font Software.
|
||||||
|
|
||||||
|
PERMISSION & CONDITIONS
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining
|
||||||
|
a copy of the Font Software, to use, study, copy, merge, embed, modify,
|
||||||
|
redistribute, and sell modified and unmodified copies of the Font
|
||||||
|
Software, subject to the following conditions:
|
||||||
|
|
||||||
|
1) Neither the Font Software nor any of its individual components,
|
||||||
|
in Original or Modified Versions, may be sold by itself.
|
||||||
|
|
||||||
|
2) Original or Modified Versions of the Font Software may be bundled,
|
||||||
|
redistributed and/or sold with any software, provided that each copy
|
||||||
|
contains the above copyright notice and this license. These can be
|
||||||
|
included either as stand-alone text files, human-readable headers or
|
||||||
|
in the appropriate machine-readable metadata fields within text or
|
||||||
|
binary files as long as those fields can be easily viewed by the user.
|
||||||
|
|
||||||
|
3) No Modified Version of the Font Software may use the Reserved Font
|
||||||
|
Name(s) unless explicit written permission is granted by the corresponding
|
||||||
|
Copyright Holder. This restriction only applies to the primary font name as
|
||||||
|
presented to the users.
|
||||||
|
|
||||||
|
4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font
|
||||||
|
Software shall not be used to promote, endorse or advertise any
|
||||||
|
Modified Version, except to acknowledge the contribution(s) of the
|
||||||
|
Copyright Holder(s) and the Author(s) or with their explicit written
|
||||||
|
permission.
|
||||||
|
|
||||||
|
5) The Font Software, modified or unmodified, in part or in whole,
|
||||||
|
must be distributed entirely under this license, and must not be
|
||||||
|
distributed under any other license. The requirement for fonts to
|
||||||
|
remain under this license does not apply to any document created
|
||||||
|
using the Font Software.
|
||||||
|
|
||||||
|
TERMINATION
|
||||||
|
This license becomes null and void if any of the above conditions are
|
||||||
|
not met.
|
||||||
|
|
||||||
|
DISCLAIMER
|
||||||
|
THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||||
|
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF
|
||||||
|
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT
|
||||||
|
OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE
|
||||||
|
COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
|
||||||
|
INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL
|
||||||
|
DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||||
|
FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM
|
||||||
|
OTHER DEALINGS IN THE FONT SOFTWARE.
|
||||||
5
assets/fonts/ComputerModernBright/README.txt
Normal file
|
|
@ -0,0 +1,5 @@
|
||||||
|
This package was compiled by Christian Perfect (http://checkmyworking.com) from the Computer Modern Unicode fonts created by Andrey V. Panov (http://cm-unicode.sourceforge.net/)
|
||||||
|
|
||||||
|
They're released under the SIL Open Font License. See OFL.txt and OFL-FAQ.txt for the terms.
|
||||||
|
|
||||||
|
A demo page for these fonts was at http://www.checkmyworking.com/cm-web-fonts/ when I released them. I can only apologise, citizen of the future, if that address doesn't exist any more.
|
||||||
45
assets/fonts/ComputerModernBright/cmun-bright.css
Normal file
|
|
@ -0,0 +1,45 @@
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbmr.eot');
|
||||||
|
src: url('cmunbmr.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbmr.woff') format('woff'),
|
||||||
|
url('cmunbmr.ttf') format('truetype'),
|
||||||
|
url('cmunbmr.svg#cmunbmr') format('svg');
|
||||||
|
font-weight: normal;
|
||||||
|
font-style: normal;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbbx.eot');
|
||||||
|
src: url('cmunbbx.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbbx.woff') format('woff'),
|
||||||
|
url('cmunbbx.ttf') format('truetype'),
|
||||||
|
url('cmunbbx.svg#cmunbbx') format('svg');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: normal;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbmo.eot');
|
||||||
|
src: url('cmunbmo.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbmo.woff') format('woff'),
|
||||||
|
url('cmunbmo.ttf') format('truetype'),
|
||||||
|
url('cmunbmo.svg#cmunbmo') format('svg');
|
||||||
|
font-weight: normal;
|
||||||
|
font-style: italic;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbxo.eot');
|
||||||
|
src: url('cmunbxo.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbxo.woff') format('woff'),
|
||||||
|
url('cmunbxo.ttf') format('truetype'),
|
||||||
|
url('cmunbxo.svg#cmunbxo') format('svg');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: italic;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
BIN
assets/fonts/ComputerModernBright/cmunbbx.eot
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbbx.ttf
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbbx.woff
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbmo.eot
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbmo.ttf
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbmo.woff
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbmr.eot
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbmr.ttf
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbmr.woff
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbxo.eot
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbxo.ttf
Normal file
BIN
assets/fonts/ComputerModernBright/cmunbxo.woff
Normal file
45
assets/fonts/cmun-bright.css
Normal file
|
|
@ -0,0 +1,45 @@
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbmr.eot');
|
||||||
|
src: url('cmunbmr.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbmr.woff') format('woff'),
|
||||||
|
url('cmunbmr.ttf') format('truetype'),
|
||||||
|
url('cmunbmr.svg#cmunbmr') format('svg');
|
||||||
|
font-weight: normal;
|
||||||
|
font-style: normal;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbbx.eot');
|
||||||
|
src: url('cmunbbx.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbbx.woff') format('woff'),
|
||||||
|
url('cmunbbx.ttf') format('truetype'),
|
||||||
|
url('cmunbbx.svg#cmunbbx') format('svg');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: normal;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbmo.eot');
|
||||||
|
src: url('cmunbmo.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbmo.woff') format('woff'),
|
||||||
|
url('cmunbmo.ttf') format('truetype'),
|
||||||
|
url('cmunbmo.svg#cmunbmo') format('svg');
|
||||||
|
font-weight: normal;
|
||||||
|
font-style: italic;
|
||||||
|
}
|
||||||
|
|
||||||
|
@font-face {
|
||||||
|
font-family: 'Computer Modern Bright';
|
||||||
|
src: url('cmunbxo.eot');
|
||||||
|
src: url('cmunbxo.eot?#iefix') format('embedded-opentype'),
|
||||||
|
url('cmunbxo.woff') format('woff'),
|
||||||
|
url('cmunbxo.ttf') format('truetype'),
|
||||||
|
url('cmunbxo.svg#cmunbxo') format('svg');
|
||||||
|
font-weight: bold;
|
||||||
|
font-style: italic;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
BIN
ea/14.740x_Syllabus.pdf
Normal file
BIN
ea/AI-Europe.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 135 KiB |
BIN
ea/AnimalSufferingGalaxyBrain.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.9 MiB |
BIN
ea/CARL.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 986 KiB |
1488
ea/CCOO-Inditex.md
Normal file
BIN
ea/Comparison.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 130 KiB |
BIN
ea/Comparison.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 139 KiB |
BIN
ea/DistributionExamples1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.7 KiB |
BIN
ea/DistributionExamples2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.9 KiB |
BIN
ea/DistributionExamples3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.9 KiB |
213
ea/EA-MH-SSC-2019-Survey.md
Normal file
|
|
@ -0,0 +1,213 @@
|
||||||
|
# Mental Health in the EA Community using SSC's 2019 Survey
|
||||||
|
|
||||||
|
If you run some regressions, you get a significant correlation between EA affiliation and mental conditions; respondents who identified as EA differed from non-EAs by ~2-4% (see below). Note that the SSC Survey is subject to fewer biases than the EA Mental Health survey, and also note that it's still difficult to extract causal conclusions. See also: [that EA Mental Health Survey](https://forum.effectivealtruism.org/posts/FheKNFgPqEsN8Nxuv/ea-mental-health-survey-results-and-analysis). Data available [here](https://slatestarcodex.com/2019/01/13/ssc-survey-results-2019/)
|
||||||
|
|
||||||
|
## Plots:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Diagnosed + Intuited
|
||||||
|
|
||||||
|
```
|
||||||
|
x y %
|
||||||
|
1 EA Yes 959 100.00000
|
||||||
|
2 Has been diagnosed with a mental condition, or thinks they have one 580 60.47967
|
||||||
|
3 Has not been diagnosed with a mental condition, and does not think they any 347 36.18352
|
||||||
|
4 NA / Didn't answer 125 13.03441
|
||||||
|
```
|
||||||
|
```
|
||||||
|
x y %
|
||||||
|
1 EA Sorta 2223 100.000000
|
||||||
|
2 Has been diagnosed with a mental condition, or thinks they have one 1354 60.908682
|
||||||
|
3 Has not been diagnosed with a mental condition, and does not think they any 795 35.762483
|
||||||
|
4 NA / Didn't answer 167 7.512371
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
x y %
|
||||||
|
1 EA No 4158 100.000000
|
||||||
|
2 Has been diagnosed with a mental condition, or thinks they have one 2416 58.104858
|
||||||
|
3 Has not been diagnosed with a mental condition, and does not think they any 1587 38.167388
|
||||||
|
4 NA / Didn't answer 248 5.964406
|
||||||
|
```
|
||||||
|
|
||||||
|
## Diagnosed
|
||||||
|
```
|
||||||
|
x y %
|
||||||
|
1 EA Yes 959 100.00000
|
||||||
|
2 Has been diagnosed with a mental condition 314 32.74244
|
||||||
|
3 Has not been diagnosed with a mental condition 613 63.92075
|
||||||
|
4 NA / Didn't answer 125 13.03441
|
||||||
|
```
|
||||||
|
```
|
||||||
|
x y %
|
||||||
|
1 EA Sorta 2223 100.000000
|
||||||
|
2 Has been diagnosed with a mental condition 718 32.298695
|
||||||
|
3 Has not been diagnosed with a mental condition 1431 64.372470
|
||||||
|
4 NA / Didn't answer 167 7.512371
|
||||||
|
```
|
||||||
|
```
|
||||||
|
x y %
|
||||||
|
1 EA No 4158 100.000000
|
||||||
|
2 Has been diagnosed with a mental condition 1183 28.451178
|
||||||
|
3 Has not been diagnosed with a mental condition 2820 67.821068
|
||||||
|
4 NA / Didn't answer 248 5.964406
|
||||||
|
```
|
||||||
|
|
||||||
|
## Regressions
|
||||||
|
### Linear
|
||||||
|
```
|
||||||
|
> # D$mentally_ill = Number of diagnosed mental ilnesses
|
||||||
|
> # D$mentally_ill2= Number of mental ilnesses, diagnosed + intuited
|
||||||
|
```
|
||||||
|
```
|
||||||
|
> summary(lm(D$mentally_ill ~ D$`EA ID`))
|
||||||
|
|
||||||
|
Call:
|
||||||
|
lm(formula = D$mentally_ill ~ D$`EA ID`)
|
||||||
|
|
||||||
|
Residuals:
|
||||||
|
Min 1Q Median 3Q Max
|
||||||
|
-0.5717 -0.5514 -0.4689 0.4486 10.4283
|
||||||
|
|
||||||
|
Coefficients:
|
||||||
|
Estimate Std. Error t value Pr(>|t|)
|
||||||
|
(Intercept) 0.46890 0.01424 32.935 < 2e-16 ***
|
||||||
|
D$`EA ID`Sorta 0.08252 0.02409 3.426 0.000617 ***
|
||||||
|
D$`EA ID`Yes 0.10284 0.03283 3.132 0.001742 **
|
||||||
|
---
|
||||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
|
||||||
|
|
||||||
|
Residual standard error: 0.9008 on 7076 degrees of freedom
|
||||||
|
(354 observations deleted due to missingness)
|
||||||
|
Multiple R-squared: 0.002421, Adjusted R-squared: 0.002139
|
||||||
|
F-statistic: 8.587 on 2 and 7076 DF, p-value: 0.0001884
|
||||||
|
```
|
||||||
|
```
|
||||||
|
> summary(lm(D$mentally_ill2 ~ D$`EA ID`))
|
||||||
|
|
||||||
|
Call:
|
||||||
|
lm(formula = D$mentally_ill2 ~ D$`EA ID`)
|
||||||
|
|
||||||
|
Residuals:
|
||||||
|
Min 1Q Median 3Q Max
|
||||||
|
-1.3711 -1.2638 -0.2638 0.7362 9.6289
|
||||||
|
|
||||||
|
Coefficients:
|
||||||
|
Estimate Std. Error t value Pr(>|t|)
|
||||||
|
(Intercept) 1.26380 0.02243 56.343 <2e-16 ***
|
||||||
|
D$`EA ID`Sorta 0.09637 0.03795 2.539 0.0111 *
|
||||||
|
D$`EA ID`Yes 0.10729 0.05173 2.074 0.0381 *
|
||||||
|
---
|
||||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
|
||||||
|
|
||||||
|
Residual standard error: 1.419 on 7076 degrees of freedom
|
||||||
|
(354 observations deleted due to missingness)
|
||||||
|
Multiple R-squared: 0.001216, Adjusted R-squared: 0.0009338
|
||||||
|
F-statistic: 4.308 on 2 and 7076 DF, p-value: 0.0135
|
||||||
|
```
|
||||||
|
```
|
||||||
|
> summary(lm(D$mentally_ill>0 ~ D$`EA ID`))
|
||||||
|
|
||||||
|
Call:
|
||||||
|
lm(formula = D$mentally_ill > 0 ~ D$`EA ID`)
|
||||||
|
|
||||||
|
Residuals:
|
||||||
|
Min 1Q Median 3Q Max
|
||||||
|
-0.3387 -0.3341 -0.2955 0.6659 0.7045
|
||||||
|
|
||||||
|
Coefficients:
|
||||||
|
Estimate Std. Error t value Pr(>|t|)
|
||||||
|
(Intercept) 0.295528 0.007323 40.354 < 2e-16 ***
|
||||||
|
D$`EA ID`Sorta 0.038581 0.012391 3.114 0.00186 **
|
||||||
|
D$`EA ID`Yes 0.043199 0.016889 2.558 0.01055 *
|
||||||
|
---
|
||||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
|
||||||
|
|
||||||
|
Residual standard error: 0.4633 on 7076 degrees of freedom
|
||||||
|
(354 observations deleted due to missingness)
|
||||||
|
Multiple R-squared: 0.001835, Adjusted R-squared: 0.001553
|
||||||
|
F-statistic: 6.505 on 2 and 7076 DF, p-value: 0.001505
|
||||||
|
```
|
||||||
|
```
|
||||||
|
> summary(lm(D$mentally_ill2>0 ~ D$`EA ID`))
|
||||||
|
|
||||||
|
Call:
|
||||||
|
lm(formula = D$mentally_ill2 > 0 ~ D$`EA ID`)
|
||||||
|
|
||||||
|
Residuals:
|
||||||
|
Min 1Q Median 3Q Max
|
||||||
|
-0.6301 -0.6036 0.3699 0.3965 0.3965
|
||||||
|
|
||||||
|
Coefficients:
|
||||||
|
Estimate Std. Error t value Pr(>|t|)
|
||||||
|
(Intercept) 0.603547 0.007692 78.466 <2e-16 ***
|
||||||
|
D$`EA ID`Sorta 0.026513 0.013014 2.037 0.0417 *
|
||||||
|
D$`EA ID`Yes 0.022127 0.017738 1.247 0.2123
|
||||||
|
---
|
||||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
|
||||||
|
|
||||||
|
Residual standard error: 0.4867 on 7076 degrees of freedom
|
||||||
|
(354 observations deleted due to missingness)
|
||||||
|
Multiple R-squared: 0.0006657, Adjusted R-squared: 0.0003832
|
||||||
|
F-statistic: 2.357 on 2 and 7076 DF, p-value: 0.09481
|
||||||
|
```
|
||||||
|
|
||||||
|
## Logistic
|
||||||
|
|
||||||
|
```
|
||||||
|
> summary(glm(D$mentally_ill>0 ~ D$`EA ID`, family=binomial(link='logit')))
|
||||||
|
|
||||||
|
Call:
|
||||||
|
glm(formula = D$mentally_ill > 0 ~ D$`EA ID`, family = binomial(link = "logit"))
|
||||||
|
|
||||||
|
Deviance Residuals:
|
||||||
|
Min 1Q Median 3Q Max
|
||||||
|
-0.9095 -0.9018 -0.8370 1.4807 1.5614
|
||||||
|
|
||||||
|
Coefficients:
|
||||||
|
Estimate Std. Error z value Pr(>|z|)
|
||||||
|
(Intercept) -0.86868 0.03464 -25.078 < 2e-16 ***
|
||||||
|
D$`EA ID`Sorta 0.17902 0.05737 3.120 0.00181 **
|
||||||
|
D$`EA ID`Yes 0.19971 0.07756 2.575 0.01003 *
|
||||||
|
---
|
||||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
|
||||||
|
|
||||||
|
(Dispersion parameter for binomial family taken to be 1)
|
||||||
|
|
||||||
|
Null deviance: 8797.8 on 7078 degrees of freedom
|
||||||
|
Residual deviance: 8784.8 on 7076 degrees of freedom
|
||||||
|
(354 observations deleted due to missingness)
|
||||||
|
AIC: 8790.8
|
||||||
|
|
||||||
|
Number of Fisher Scoring iterations: 4
|
||||||
|
```
|
||||||
|
```
|
||||||
|
> summary(glm(D$mentally_ill2>0 ~ D$`EA ID`, family=binomial(link='logit')))
|
||||||
|
|
||||||
|
Call:
|
||||||
|
glm(formula = D$mentally_ill2 > 0 ~ D$`EA ID`, family = binomial(link = "logit"))
|
||||||
|
|
||||||
|
Deviance Residuals:
|
||||||
|
Min 1Q Median 3Q Max
|
||||||
|
-1.4103 -1.3603 0.9612 1.0049 1.0049
|
||||||
|
|
||||||
|
Coefficients:
|
||||||
|
Estimate Std. Error z value Pr(>|z|)
|
||||||
|
(Intercept) 0.42027 0.03231 13.007 <2e-16 ***
|
||||||
|
D$`EA ID`Sorta 0.11221 0.05514 2.035 0.0419 *
|
||||||
|
D$`EA ID`Yes 0.09344 0.07517 1.243 0.2139
|
||||||
|
---
|
||||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
|
||||||
|
|
||||||
|
(Dispersion parameter for binomial family taken to be 1)
|
||||||
|
|
||||||
|
Null deviance: 9439.1 on 7078 degrees of freedom
|
||||||
|
Residual deviance: 9434.4 on 7076 degrees of freedom
|
||||||
|
(354 observations deleted due to missingness)
|
||||||
|
AIC: 9440.4
|
||||||
|
|
||||||
|
Number of Fisher Scoring iterations: 4
|
||||||
|
```
|
||||||
25
ea/ForeacstingClassNotes.md
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
## Brief history of human judgmental forecasting
|
||||||
|
|
||||||
|
- 1947–1991: Cold war failures of the US intelligence community
|
||||||
|
- Legendary figure: [Sherman Kent](https://www.wikiwand.com/en/Sherman_Kent), who came up with [words of estimative probability](https://www.wikiwand.com/en/Words_of_estimative_probability) to solve ambiguity in [National Intelligence Estimates](https://www.econlib.org/archives/2017/08/tristans_tetloc.html)
|
||||||
|
- Meanwhile:
|
||||||
|
- *An Analyst’s Reflections on Forecasting: The Limits of Prediction*, Bobby W. (anonymous)
|
||||||
|
- *Psychology of Intelligence Analysis](), by Richards J. Heuer
|
||||||
|
- 1988-2010: [Prediction Markets](https://www.wikiwand.com/en/Prediction_market) gain wider recognition, but they mostly fail to gain a foothold. An early small scandal in which an early project appears to contain [markets on terrorist attacks](https://www.wikiwand.com/en/Policy_Analysis_Market) sours the idea, at least initially. [Iowa Electronic Markets](https://www.wikiwand.com/en/Iowa_Electronic_Markets) is allowed to exist by US regulators because of low overall betting sizes and its academic purpose.
|
||||||
|
- 2010-2015: The [Aggregative Contingent Estimation (ACE) Program](https://www.wikiwand.com/en/Aggregative_Contingent_Estimation_(ACE)_Program) is run by IARPA, as a belated response from the US intelligence community to not having been able to predict the 2001 9/11 attacks. [ The Good Judgment Project ](https://www.wikiwand.com/en/The_Good_Judgment_Project) wins the competition, and in 2015, Phil Tetlock publishes [Superforecasting](https://www.wikiwand.com/en/Superforecasting:_The_Art_and_Science_of_Prediction). The Good Judgment Project fails to cross the [valley of death](https://acquisitiontalk.com/2019/12/explaining-the-valley-of-death-in-defense-technology/)
|
||||||
|
- 2015-2021: Crypto prediction markets such as [Augur](https://www.wikiwand.com/en/Augur_(software)), [Polymarket](https://polymarket.com/) and others allow users to trade without the difficult to get approval of US regulators. [PredictIt](https://www.wikiwand.com/en/PredictIt), founded in 2014, and [Kalshi](https://kalshi.com/), founded in 2020, negotiate with regulators to get said approval. Meanwhile, platforms like [Metaculus](https://www.wikiwand.com/en/Metaculus), founded in 2015 have users compete for internet points, thought they also have occasional monetary rewards for winners of tournaments.
|
||||||
|
|
||||||
|
## Human biases and their standard mitigations
|
||||||
|
- Vague verbiage → Quantitative forecasts, words of estimative probability
|
||||||
|
- General overconfidence → Calibration training
|
||||||
|
- Hindsight bias → Keeping track of predictions
|
||||||
|
- Scope insensitivity → Consider different quantities for your prediction. Anchor on the base-rate.
|
||||||
|
- Anchoring bias → If you have to anchor on something, anchor on the base-rate
|
||||||
|
- Confirmation Bias → Move a little bit with each piece of infomration
|
||||||
|
|
||||||
|
Other forecasting habits:
|
||||||
|
- Betting
|
||||||
|
- Teaming using the delphi method
|
||||||
|
- Emotional detachment
|
||||||
|
- Dialectical bootstrapping: Make a forecast, write down reasoning, forget about it, come back again, then average the two
|
||||||
|
- Pre & post-mortems
|
||||||
BIN
ea/Forecasting/AI-Timelines.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
ea/Forecasting/AccuracyVsConfidence.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
26
ea/Forecasting/ListOfForecastingProjects.md
Normal file
|
|
@ -0,0 +1,26 @@
|
||||||
|
# List of forecasting projects:
|
||||||
|
|
||||||
|
- Have forecasters read Toby Ord's book, and generate their own probabilities of x-risks
|
||||||
|
- Forecast variable inputs to Trammell's model
|
||||||
|
- Forecast whether some big companies will keep to their chicken broiler / animal suffering commitments
|
||||||
|
- Forecast the value of altruistic projects; I (Nuño) have a small demo on this
|
||||||
|
- Throw some optimization power at the Metaculus Ragnarok questions
|
||||||
|
- Look into the relationship between price or time spent and forecast accuracy
|
||||||
|
- Look into rewarding forecasters according to their Shapley values
|
||||||
|
- Predict which EA Fund applications will be funded
|
||||||
|
- Add interesting and nontrivial markets to Augur
|
||||||
|
- Rapid Response EA Forecasting Hotline
|
||||||
|
- Forecast incubator ideas' likelihood of success
|
||||||
|
- Create a calibration hall of fame/shame for researchers' past forecasts
|
||||||
|
- Case studies / lessons learned on forecasting
|
||||||
|
- Pay and support forecasters to make forecasts on existing platforms
|
||||||
|
- Get a visible forecasting win for EA/QURI/EpiFor
|
||||||
|
- Participate in an OSINT project
|
||||||
|
- Suggest questions to Good Judgement Open with an altruistic bent
|
||||||
|
- Talk with CSET; they seem a little bit confused/lost
|
||||||
|
- Recruit people for CSET
|
||||||
|
- Forecasting for EA policy advocates
|
||||||
|
- Estimate the value of the forecasted variables/questions on Metaculus and GJP
|
||||||
|
- On-demand forecasting to research teams
|
||||||
|
- Write down lessons learnt from EpidemicForecasting
|
||||||
|
- Foretold consulting/training
|
||||||
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
ea/Forecasting/USACountiesPlots/Kings_County_deaths_daily.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
ea/Forecasting/USACountiesPlots/Maricopa_County_deaths_daily.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
ea/Forecasting/USACountiesPlots/New_York_County_deaths_daily.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
21
ea/Forecasting/USACountiesPlots/README.md
Normal file
|
|
@ -0,0 +1,21 @@
|
||||||
|
# County Plots
|
||||||
|
## Maricopa County
|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|
## Yuma County
|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|
## Kings County
|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|
## New York County
|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
|

|
||||||
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
{kind=link}
|
After Width: | Height: | Size: 28 KiB |
BIN
ea/Forecasting/USACountiesPlots/Yuma_County_deaths_daily.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
BIN
ea/Forecasting/USACountiesPlots/Yuma_County_deaths_daily_log.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
BIN
ea/Forecasting/calib.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
BIN
ea/Forecasting/calibration.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
BIN
ea/Forecasting/electoral_college_predictit.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 79 KiB |
BIN
ea/Forecasting/strongCountermeasuresBalochistan.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
120
ea/ForecastingNewsletter/April2020.md
Normal file
|
|
@ -0,0 +1,120 @@
|
||||||
|
A forecasting digest with a focus on experimental forecasting.
|
||||||
|
- You can sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020).
|
||||||
|
- You can also see this post on LessWrong [here](https://www.lesswrong.com/posts/e4C7hTmbmPfLjJzXT/forecasting-newsletter-april-2020-1)
|
||||||
|
- And the post is archived [here](https://nunosempere.github.io/ea/ForecastingNewsletter/)
|
||||||
|
|
||||||
|
The newsletter itself is experimental, but there will be at least five more iterations. Feel free to use this post as a forecasting open thread.
|
||||||
|
|
||||||
|
Why is this relevant to EAs?
|
||||||
|
- Some items are immediately relevant (e.g., forecasts of famine).
|
||||||
|
- Others are projects whose success I'm cheering for, and which I think have the potential to do great amounts of good (e.g., Replication Markets).
|
||||||
|
- The remaining are relevant to the extent that cross-polination of ideas is valuable.
|
||||||
|
- Forecasting may become/is becoming a powerful tool for world-optimization, and EAs may want to avail themselves of this tool.
|
||||||
|
|
||||||
|
Conflict of interest: Marked as (c.o.i) throughout the text.
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Prediction Markets & Forecasting platforms.
|
||||||
|
- Augur.
|
||||||
|
- PredictIt & Election Betting Odds.
|
||||||
|
- Replication Markets.
|
||||||
|
- Coronavirus Information Markets.
|
||||||
|
- Foretold. (c.o.i).
|
||||||
|
- Metaculus.
|
||||||
|
- Good Judgement and friends.
|
||||||
|
- In the News.
|
||||||
|
- Long Content.
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting platforms.
|
||||||
|
|
||||||
|
Forecasters may now choose to forecast any of the four horsemen of the Apocalypse: Death, Famine, Pestilence and War.
|
||||||
|
|
||||||
|
### Augur: [augur.net](https://www.augur.net/)
|
||||||
|
|
||||||
|
Augur is a decentralized prediction market. It will be undergoing its [first major update](https://www.augur.net/blog/augur-v2/).
|
||||||
|
|
||||||
|
### Predict It & Election Betting Odds: [predictIt.org](https://www.predictit.org/) & [electionBettingOdds.com](http://electionbettingodds.com/)
|
||||||
|
|
||||||
|
PredictIt is a prediction platform restricted to US citizens or those who bother using a VPN. [Anecdotically](https://www.lesswrong.com/posts/qzRzQgxiZa3tPJJg8/free-money-at-predictit), it often has free energy, that is, places where one can earn money by having better probabilities, and where this is not too hard. However, due to fees & the hassle of setting it up, these inefficiencies don't get corrected.
|
||||||
|
In PredictIt, the [world politics](https://www.predictit.org/markets/5/World) section...
|
||||||
|
- gives a 17% to [a Scottish independence referendum](https://www.predictit.org/markets/detail/6236/Will-Scottish-Parliament-call-for-an-independence-referendum-in-2020) (though read the fine print).
|
||||||
|
- gives 20% to [Netanyahu leaving before the end of the year](https://www.predictit.org/markets/detail/6238/Will-Benjamin-Netanyahu-be-prime-minister-of-Israel-on-Dec-31,-2020)
|
||||||
|
- gives 64% to [Maduro remaining President of Venezuela before the end of the year](https://www.predictit.org/markets/detail/6237/Will-Nicol%C3%A1s-Maduro-be-president-of-Venezuela-on-Dec-31,-2020).
|
||||||
|
|
||||||
|
The question on [which Asian/Pacific leaders will leave office next?](https://www.predictit.org/markets/detail/6655/Which-of-these-8-Asian-Pacific-leaders-will-leave-office-next) also looks like it has a lot of free energy, as it overestimates low probability events.
|
||||||
|
|
||||||
|
[Election Betting Odds](https://electionbettingodds.com/) aggregates PredictIt with other such services for the US presidential elections.
|
||||||
|
|
||||||
|
### Replication Markets: [replicationmarkets.com](https://www.replicationmarkets.com)
|
||||||
|
Replication Markets is a project where volunteer forecasters try to predict whether a given study's results will be replicated with high power. Rewards are monetary, but only given out to the top N forecasters, and markets suffer from sometimes being dull. They have added [two market-maker bots](https://www.replicationmarkets.com/index.php/2020/04/16/meet-the-bots/) and commenced and conclude their 6th round. They also added a sleek new widget to visualize the price of shares better.
|
||||||
|
|
||||||
|
### Coronavirus Information Markets: [coronainformationmarkets.com](https://coronainformationmarkets.com/)
|
||||||
|
For those who want to put their money where their mouth is, there is now a prediction market for coronavirus related information. The number of questions is small, and the current trading volume started at $8000, but may increase. Another similar platform is [waves.exchange/prediction](https://waves.exchange/prediction), which seems to be just a wallet to which a prediction market has been grafted on.
|
||||||
|
|
||||||
|
Unfortunately, I couldn't make a transaction in these markets with ~30 mins; the time needed to be included in an ethereum block is longer and I may have been too stingy with my gas fee.
|
||||||
|
|
||||||
|
### Foretold: [foretold.io](https://www.foretold.io/) (c.o.i)
|
||||||
|
|
||||||
|
Foretold is an forecasting platform which has experimentation and exploration of forecasting methods in mind. They bring us:
|
||||||
|
|
||||||
|
- A new [distribution builder](https://www.highlyspeculativeestimates.com/dist-builder) to visualize and create probability distributions.
|
||||||
|
- Forecasting infrastructure for epidemicforecasting.org.
|
||||||
|
|
||||||
|
### Metaculus: [metaculus.com](https://www.metaculus.com/)
|
||||||
|
|
||||||
|
Metaculus is a forecasting platform with an active community and lots of interesting questions. They bring us a series of tournaments and question series:
|
||||||
|
- [The Ragnarök question series on terrible events](https://www.metaculus.com/questions/?search=cat:series--ragnarok)
|
||||||
|
- [Pandemic and lockdown series](https://pandemic.metaculus.com/lockdown/)
|
||||||
|
- [The Lightning Round Tournament: Comparing Metaculus Forecasters to Infectious Disease Experts](https://www.metaculus.com/questions/4166/the-lightning-round-tournament-comparing-metaculus-forecasters-to-infectious-disease-experts/). "Each week you will have exactly 30 hours to lock in your prediction on a short series of important questions, which will simultaneously be posed to different groups of forecasters. This provides a unique opportunity to directly compare the Metaculus community prediction with other forecasting methods." Furthermore, Metaculus swag will be given out to the top forecasters.
|
||||||
|
- [Overview of Coronavirus Disease 2019 (COVID-19) forecasts](https://pandemic.metaculus.com/COVID-19/).
|
||||||
|
- [The Salk Tournament for coronavirus (SARS-CoV-2) Vaccine R&D](https://pandemic.metaculus.com/questions/4093/the-salk-tournament-for-coronavirus-sars-cov-2-vaccine-rd/).
|
||||||
|
- [Lockdown series: when will life return to normal-ish?](https://pandemic.metaculus.com/lockdown/)
|
||||||
|
|
||||||
|
### /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
|
||||||
|
|
||||||
|
Good Judgement Inc. is the organization which grew out of Tetlock's research on forecasting, and out of the Good Judgement Project, which won the [IARPA ACE forecasting competition](https://en.wikipedia.org/wiki/Aggregative_Contingent_Estimation_(ACE)_Program), and resulted in the research covered in the *Superforecasting* book.
|
||||||
|
|
||||||
|
The Open Philantropy Project has funded [this covid dashboard](https://goodjudgment.io/covid/dashboard/) by their (Good Judgement Inc.'s) Superforecasting Analytics Service, with predictions solely from superforecasters; see more on [this blogpost](https://www.openphilanthropy.org/blog/forecasting-covid-19-pandemic).
|
||||||
|
|
||||||
|
Good Judgement Inc. also organizes the Good Judgement Open (gjopen.com)[https://www.gjopen.com/], a forecasting platform open to all, with a focus on serious geopolitical questions. They structure their questions in challenges, to which they have recently added one on [the Coronavirus Outbreak](https://www.gjopen.com/challenges/43-coronavirus-outbreak); some of these questions are similar in spirit to the short-fuse Metaculus Tournament.
|
||||||
|
|
||||||
|
Of the questions which have been added recently to the Good Judgment Open, the crowd [doesn't buy](https://www.gjopen.com/questions/1580-before-1-january-2021-will-tesla-release-an-autopilot-feature-designed-to-navigate-traffic-lights) that Tesla will release an autopilot feature to navigate traffic lights, despite announcements to the contrary. Further, the aggregate...
|
||||||
|
- is extremely confident that, [before 1 January 2021](https://www.gjopen.com/questions/1595-before-1-january-2021-will-the-russian-constitution-be-amended-to-allow-vladimir-putin-to-remain-president-after-his-current-term), the Russian constitution will be amended to allow Vladimir Putin to remain president after his current term.
|
||||||
|
- gives a lagging estimate of 50% on [Benjamin Netanyahu ceasing to be the prime minister of Israel before 1 January 2021](https://www.gjopen.com/questions/1498-will-benjamin-netanyahu-cease-to-be-the-prime-minister-of-israel-before-1-january-2021).
|
||||||
|
- and 10% for [Nicolás Maduro](https://www.gjopen.com/questions/1423-will-nicolas-maduro-cease-to-be-president-of-venezuela-before-1-june-2020) leaving before the 1st of June.
|
||||||
|
- [forecasts famine](https://www.gjopen.com/questions/1559-will-the-un-declare-that-a-famine-exists-in-any-part-of-ethiopia-kenya-somalia-tanzania-or-uganda-in-2020) (70%).
|
||||||
|
- Of particular interest is that GJOpen didn't see the upsurge in tests (and thus positives) in the US until until the day before they happened, for [this question](https://www.gjopen.com/questions/1599-how-many-total-cases-of-covid-19-in-the-u-s-will-the-covid-tracking-project-report-as-of-sunday-26-april-2020). Forecasters, including superforecasters, went with a linear extrapolation from the previous n (usually 7) days. However, even though the number of cases looks locally linear, it's also globally exponential, as [this 3Blue1Brown video](https://www.youtube.com/watch?v=Kas0tIxDvrg) shows. On the other hand, an enterprising forecaster tried to fit a Gompertz distribution, but then fared pretty badly.
|
||||||
|
|
||||||
|
## In the News
|
||||||
|
- [Forecasts in the time of coronavirus](https://ftalphaville.ft.com/2020/04/08/1586350137000/Forecasts-in-the-time-of-coronavirus/): The Financial times runs into difficulties trying to estimate whether some companies are overvalued, because the stock value/earnings ratio, which is otherwise an useful tool, is going to infinity as earnings go to 0 during the pandemic.
|
||||||
|
- [Predictions are hard, especially about the coronavirus](https://www.vox.com/future-perfect/2020/4/8/21210193/coronavirus-forecasting-models-predictions): Vox has a short and sweet article on the difficulties of prediction forecasting; of note is that epidemiology experts are not great predictors.
|
||||||
|
- [538: Why Forecasting COVID-19 Is Harder Than Forecasting Elections](https://fivethirtyeight.com/features/politics-podcast-why-forecasting-covid-19-is-harder-than-forecasting-elections/)
|
||||||
|
- [COVID-19: Forecasting with Slow and Fast Data](https://www.stlouisfed.org/on-the-economy/2020/april/covid-19-forecasting-slow-fast-data). A short and crisp overview by the Federal Reserve Bank of St Louis on lagging economic measurement instruments, which have historically been quite accurate, and on the faster instruments which are available right now. Highlight: "As of March 31, the WEI [a faster, weekly economic index] indicated that GDP would decline by 3.04% at an annualized rate in the first quarter, a much more sensible forecast than that which is currently indicated by the ENI (a lagging measure which predicts 2.26% *growth* on an annualized basis in the first quarter)".
|
||||||
|
- [Decline in aircraft flights clips weather forecasters' wings](https://www.theguardian.com/news/2020/apr/09/decline-aircraft-flights-clips-weather-forecasters-wings-coronavirus): Coronavirus has led to reduction in number of aircraft sending data used in making forecasts.
|
||||||
|
- [The World in 2020, as forecast by The Economist](https://www.brookings.edu/blog/future-development/2020/04/10/the-world-in-2020-as-forecast-by-the-economist/). The Brookings institution looks back at forecasts for 2020 by *The Economist*.
|
||||||
|
- Forbes brings us this [terrible, terrible opinion piece](https://www.forbes.com/sites/josiecox/2020/04/14/life-work-after-covid-19-coronavirus-forecast-accuracy-brighter-future/#28732f74765b) which mentions Tetlock, goes on about how humans are terrible forecasters, and then predicts that there will be no social changes because of covid with extreme confidence.
|
||||||
|
- [The Challenges of Forecasting the Spread and Mortality of COVID-19](https://www.heritage.org/public-health/report/the-challenges-forecasting-the-spread-and-mortality-covid-19). The Heritage foundation brings us a report with takeaways of particular interest to policymakers. It has great illustrations of how the overall mortality changes with different assumptions. Note that criticisms of and suggestions for the current US administration are worded kindly, as the Heritage Foundation is a conservative organization.
|
||||||
|
- [Why most COVID-19 forecasts were wrong](https://www.afr.com/wealth/personal-finance/why-most-covid-19-forecasts-were-wrong-20200415-p54k40). Financial review article suffers from hindsight bias.
|
||||||
|
- [Banks are forecasting on gut instinct — just like the rest of us](https://www.ft.com/content/4b8108e5-b04c-4304-9f40-825076a4fed7). Financial Times article starts with "We all cling to the belief that somebody out there, somewhere, knows what the heck is going on. Someone — well-connected insider, evil mastermind — must hold the details on the coming market crash, the election in November, or when the messiah will return. In moments of crisis, this delusion tightens its grip," and it only gets better.
|
||||||
|
- ['A fool's game': 4 economists break down what it's like forecasting the worst downturn since the Great Recession](https://www.businessinsider.com/economists-what-its-like-forecasting-recession-experience-unemployment-coronavirus-2020-4). "'My outlook right now is that I don't even have an outlook,' Martha Gimbel, an economist at Schmidt Futures, told Business Insider. 'This is so bad and so unprecedented that any attempt to forecast what's going to happen here is just a fool's game.'"
|
||||||
|
- [IMF predicts -3% global depression](https://blogs.imf.org/2020/04/14/the-great-lockdown-worst-economic-downturn-since-the-great-depression/). "Worst Economic Downturn Since the Great Depression".
|
||||||
|
- [COVID-19 Projections](https://covid19.healthdata.org/united-states-of-america): A really sleek US government coronavirus model. See [here](https://www.lesswrong.com/posts/QuzAwSTND6N4k7yNj/seemingly-popular-covid-19-model-is-obvious-nonsense) for criticism. See also: [Epidemic Forecasting](http://epidemicforecasting.org/) (c.o.i).
|
||||||
|
- [The M5 competition is ongoing](https://www.kaggle.com/c/m5-forecasting-accuracy/data).
|
||||||
|
- [Some MMA forecasting](https://mmajunkie.usatoday.com/2020/04/fantasy-fight-forecasting-ufc-welterweight-title-usman-masvidal-woodley-edwards). The analysis surprised me; it could well have been a comment in a GJOpen challenge.
|
||||||
|
- [Self-reported COVID-19 Symptoms Show Promise for Disease Forecasts](https://www.cmu.edu/news/stories/archives/2020/april/self-reported-covid-19-symptoms-disease-forecasts.html). "Thus far, CMU is receiving about one million responses per week from Facebook users. Last week, almost 600,000 users of the Google Opinion Rewards and AdMob apps were answering another CMU survey each day."
|
||||||
|
- [Lockdown Policy and Disease Eradication](https://www.isical.ac.in/~covid19/Modeling.html). Researchers in India hypothesize on what the optimal lockdown policy may be.
|
||||||
|
- [Using a delay-adjusted case fatality ratio to estimate under-reporting](https://cmmid.github.io/topics/covid19/severity/global_cfr_estimates.html).
|
||||||
|
- [The first modern pandemic](https://www.gatesnotes.com/Health/Pandemic-Innovation). In which Bill Gates names covid-SARS "Pandemic I" and offers an informed overview of what is yet to come.
|
||||||
|
- [36,000 Missing Deaths: Tracking the True Toll of the Coronavirus Crisis](https://www.nytimes.com/interactive/2020/04/21/world/coronavirus-missing-deaths.html).
|
||||||
|
- There is a shadow industry which makes what look to be really detailed reports on topics of niche interest: Here is, for example, a [$3,500 report on market trends for the Bonsai](https://technovally.com/business-methodology-by-2020-2029-bonsai-market/)
|
||||||
|
- [An active hurricane season will strain emergency response amid pandemic, forecasters warn](https://www.cbsnews.com/news/hurricane-season-2020-active-strain-emergency-response-coronavirus-pandemic/). "Schlegelmilch stresses that humanity must get better at prioritizing long-term strategic planning."
|
||||||
|
|
||||||
|
## Long Content
|
||||||
|
- [Atari, early](https://aiimpacts.org/atari-early/). "Deepmind announced that their Agent57 beats the ‘human baseline’ at all 57 Atari games usually used as a benchmark."
|
||||||
|
- [A failure, but not of prediction](https://slatestarcodex.com/2020/04/14/a-failure-but-not-of-prediction/); a SlateStarCodex Essay.
|
||||||
|
- [Philip E. Tetlock on Forecasting and Foraging as a Fox](https://medium.com/conversations-with-tyler/philip-tetlock-tyler-cowen-forecasting-sociology-30401464b6d9); an interview with Tyler Cowen. Some highly valuable excerpts on counterfactual reasoning. Mentions [this program](https://www.iarpa.gov/index.php/research-programs/focus/focus-baa) and [this study](https://journals.sagepub.com/doi/10.1177/0022022105284495), on the forefront of knowledge.
|
||||||
|
- [Assessing Kurzweil's 1999 predictions for 2019](https://www.lesswrong.com/posts/GhDfTAtRMxcTqAFmc/assessing-kurzweil-s-1999-predictions-for-2019). Kurzweil made on the order of 100 predictions for 2019 in his 1999 book *The Age of Spiritual Machines*. How did they fare? We'll find out, next month.
|
||||||
|
- [Zvi on Evaluating Predictions in Hindsight](https://www.lesswrong.com/posts/BthNiWJDagLuf2LN2/evaluating-predictions-in-hindsight). A fun read. Of course, the dissing of Scott Alexander's prediction is fun to read, but I really want to see how a list of Zvi's predictions fares.
|
||||||
|
- An oldie related to the upcoming US elections: [Which Economic Indicators Best Predict Presidential Elections?](https://fivethirtyeight.blogs.nytimes.com/2011/11/18/which-economic-indicators-best-predict-presidential-elections/), from 2011's Nate Silver.
|
||||||
|
- [A rad comment exchange at GJOpen](https://www.gjopen.com/comments/comments/1018771) in which cool superforecaster @Anneinak shares some pointers.
|
||||||
|
- [As the efficient markets hypothesis turns 50, it is time to bin it](https://www.ft.com/content/dbf88254-22af-11ea-b8a1-584213ee7b2b) for a Financial Times article, from Jan 1st and thus untainted by coronavirus discussion. Related: [This LW comment by Wei Dai](https://www.lesswrong.com/posts/jAixPHwn5bmSLXiMZ/open-and-welcome-thread-february-2020?commentId=a9YCk3ZtpQZCDqeqR#wAHCXmnywzfhoQT9c) and [this tweet](https://twitter.com/ESYudkowsky/status/1233174331133284353) from Eliezer Yudkowsky. See also a very rambly article by an Australian neswpaper: [Pandemic highlights problems with efficient-market hypothesis](https://independentaustralia.net/politics/politics-display/pandemic-highlights-problems-with-efficient-market-hypothesis,13776).
|
||||||
115
ea/ForecastingNewsletter/August2020.md
Normal file
|
|
@ -0,0 +1,115 @@
|
||||||
|
## Highlights
|
||||||
|
538 releases [model](https://projects.fivethirtyeight.com/2020-election-forecast/) of the US elections; Trump predicted to win ~30% of the time.
|
||||||
|
|
||||||
|
[Study](https://link.springer.com/article/10.1007%2Fs10654-020-00669-6) offers instructive comparison of New York covid models, finds that for the IHME model, reported death counts fell inside the 95% prediction intervals only 53% of the time.
|
||||||
|
|
||||||
|
Biggest decentralized trial [to date](https://blog.kleros.io/kleros-community-update-july-2020/#case-302-the-largest-decentralized-trial-of-all-time), with 511 jurors asked to adjudicate a case coming from the Omen prediction market: "Will there be a day with at least 1000 reported corona deaths in the US in the first 14 days of July?."
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Highlights
|
||||||
|
- Prediction Markets & Forecasting Platforms
|
||||||
|
- In The News
|
||||||
|
- Hard To Categorize
|
||||||
|
- Long Content
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting Platforms
|
||||||
|
|
||||||
|
On [PredictIt](htps://predictit.org/), presidential election prices are close to [even odds](https://www.predictit.org/markets/detail/3698), with Biden at 55, and Trump at 48.
|
||||||
|
|
||||||
|
Good Judgement Inc. continues providing their [dashboard](https://goodjudgment.io/covid-recovery/), and the difference between the probability assigned by superforecasters to a Biden win (~75%), and those offered by [betfair](https://www.betfair.com/sport/politics) (~55%) was enough to make it worth for me to place a small bet. At some point, Good Judgement Inc. and Cultivate Labs started a new platform on the domain [covidimpacts.com](https://www.covidimpacts.com), but forecasts there seem weaker than on Good Judgement Open.
|
||||||
|
|
||||||
|
[Replication Markets](https://www.replicationmarkets.com/) started their COVID-19 round, and created a page with COVID-19 [resources for forecasters](https://www.replicationmarkets.com/index.php/frequently-asked-questions/resources-for-forecasters/).
|
||||||
|
|
||||||
|
Nothing much to say about [Metaculus](https://www.metaculus.com/questions/) this month, but I appreciated their previously existing list of [prediction resources](https://www.metaculus.com/help/prediction-resources/).
|
||||||
|
|
||||||
|
[Foretell](https://www.cset-foretell.com) has a [blog](https://www.cset-foretell.com/blog), and hosted a forecasting forum which discussed
|
||||||
|
- metrizicing the grand. That is, decomposing and operationalizing big picture questions into smaller ones, which can then be forecasted.
|
||||||
|
- operationalizing these big picture questions might also help identify disagreements, which might then either be about the indicators, proxies or subquestions chosen, or about the probabilities given to the subquestions.
|
||||||
|
- sometimes we can't measure what we care about, or we don't care about what we can measure.
|
||||||
|
- one might be interested in questions about the future 3 to 7 years from now, but questions which ask about events 3 to 15 months in the future (which forecasting tournaments can predict better) can still provide useful signposts.
|
||||||
|
|
||||||
|
Meanwhile, ethereum-based prediction markets such as Omen or Augur are experiencing difficulties because of the rise of decentralized finance (DeFi) and speculation and excitement about it. That speculation and excitement has increased the gas price (fees), such that making a casual prediction is for now too costly.
|
||||||
|
|
||||||
|
## In The News
|
||||||
|
|
||||||
|
[Forecasting the future of philanthropy](https://www.fastcompany.com/90532945/forecasting-the-future-of-philanthropy). The [American Lebanese Syrian Associated Charities](https://en.wikipedia.org/wiki/American_Lebanese_Syrian_Associated_Charities), the largest healthcare related charity in the United States, whose mission is to fund the [St. Jude Children's Research Hospital](https://en.wikipedia.org/wiki/St._Jude_Children%27s_Research_Hospital). To do this, they employ aggressive fundraising tactics, which have undergone modifications throughout the current pandemic.
|
||||||
|
|
||||||
|
[Case 302: the Largest Decentralized Trial of All Time](https://blog.kleros.io/kleros-community-update-july-2020/#case-302-the-largest-decentralized-trial-of-all-time). Kleros is a decentralized dispute resolution platform. "In July, Kleros had its largest trial ever where 511 jurors were drawn in the General Court to adjudicate a case coming from the Omen prediction market: Will there be a day with at least 1000 reported Corona death in the US in the first 14 days of July?." [Link to the case](https://court.kleros.io/cases/302)
|
||||||
|
|
||||||
|
[ExxonMobil Slashing Permian Rig Count, Forecasting Global Oil Glut Extending ‘Well into 2021’](https://www.naturalgasintel.com/exxonmobil-slashing-permian-rig-count-forecasting-global-oil-glut-extending-well-into-2021/). My own interpretation is that the gargantuan multinational's decision is an honest signal of an expected extended economic downturn.
|
||||||
|
|
||||||
|
> Supply is expected to exceed demand for months, “and we anticipate it will be well into 2021 before the overhang is cleared and we returned to pre-pandemic levels,” Senior Vice President Neil Chapman said Friday during a conference call.
|
||||||
|
|
||||||
|
> “Simply put, the demand destruction in the second quarter was unprecedented in the history of modern oil markets. To put it in context, absolute demand fell to levels we haven’t seen in nearly 20 years. We’ve never seen a decline with this magnitude and pace before, even relative to the historic periods of demand volatility following the global financial crisis and as far back as the 1970s oil and energy crisis.”
|
||||||
|
|
||||||
|
> Even so, ExxonMobil’s Permian rig count is to be sharply lower than it was a year ago. The company had more than 50 rigs running across its Texas-New Mexico stronghold as of last fall. At the end of June it was down to 30, “and we expect to cut that number by at least half again by the end of this year,” Chapman said.
|
||||||
|
|
||||||
|
[Google Cloud AI and Harvard Global Health Institute Collaborate on new COVID-19 forecasting model](https://cloud.google.com/blog/products/ai-machine-learning/google-cloud-is-releasing-the-covid-19-public-forecasts).
|
||||||
|
|
||||||
|
[Betting markets](https://smarkets.com/event/40554343/politics/uk/brexit/trade-deals) put [UK-EU trade deal in 2020 at 66%](https://sports.yahoo.com/betting-odds-put-ukeu-trade-deal-in-2020-at-66-095009521.html) (now 44%).
|
||||||
|
|
||||||
|
[Experimental flood forecasting system didn’t help](https://www.hindustantimes.com/mumbai-news/flood-forecasting-system-didn-t-help/story-mJanM39kxJPOvFma6TeqUM.html) in Mumbai. The system was to provide a three day advance warning, but didn't.
|
||||||
|
|
||||||
|
FiveThirtyEight covers various facets of the USA elections: [Biden Is Polling Better Than Clinton At Her Peak](https://fivethirtyeight.com/features/biden-is-polling-better-than-clinton-at-her-peak/), and releases [their model](https://fivethirtyeight.com/features/how-fivethirtyeights-2020-presidential-forecast-works-and-whats-different-because-of-covid-19/), along with some [comments about it](https://fivethirtyeight.com/features/our-election-forecast-didnt-say-what-i-thought-it-would/)
|
||||||
|
|
||||||
|
In other news, this newsletter reached 200 subscribers last week.
|
||||||
|
|
||||||
|
## Hard to Categorize
|
||||||
|
|
||||||
|
[Groundhog day](https://en.wikipedia.org/wiki/Groundhog_Day) is a tradition in which American crowds pretend to believe that a small rat has oracular powers.
|
||||||
|
|
||||||
|
[Tips](https://politicalpredictionmarkets.com/blog/) for forecasting on PredictIt. These include betting against Trump voters who arrive at PredictIt from Breitbart.
|
||||||
|
|
||||||
|
Linch Zhang asks [What are some low-information priors that you find practically useful for thinking about the world?](https://forum.effectivealtruism.org/posts/SBbwzovWbghLJixPn/what-are-some-low-information-priors-that-you-find)
|
||||||
|
|
||||||
|
[AstraZeneca looking for a Forecasting Director](https://careers.astrazeneca.com/job/wilmington/forecasting-director-us-renal/7684/16951921) (US-based).
|
||||||
|
|
||||||
|
[Genetic Engineering Attribution Challenge](https://www.drivendata.org/competitions/63/genetic-engineering-attribution/).
|
||||||
|
|
||||||
|
NSF-funded tournament looking to compare human forecasters with a random forest ML model from Johns Hopkins in terms of forecasting the success probability of cancer drug trials. More info [here](https://www.fandm.edu/magazine/magazine-issues/spring-summer-2020/spring-summer-2020-articles/2020/06/10/is-there-a-better-way-to-predict-the-future), and one can sign-up [here](https://www.pytho.io/human-forest). I've heard rewards are generous, but they don't seem to be specified on the webpage. Kudos to Joshua Monrad.
|
||||||
|
|
||||||
|
Results of an [expert forecasting session](https://twitter.com/juan_cambeiro/status/1291153289879392257) on covid, presented by expert forecaster Juan Cambeiro.
|
||||||
|
|
||||||
|
A playlist of [podcasts related to forecasting](https://open.spotify.com/playlist/4LKES4QcFNozmwImjHWrBX?si=twuBPF-fSxejbpMwUToatg). Kudos to Michał Dubrawski.
|
||||||
|
|
||||||
|
## Long Content
|
||||||
|
|
||||||
|
[A case study in model failure? COVID-19 daily deaths and ICU bed utilization predictions in New York state](https://link.springer.com/article/10.1007%2Fs10654-020-00669-6) and commentary: [Individual model forecasts can be misleading, but together they are useful](https://link.springer.com/article/10.1007/s10654-020-00667-8).
|
||||||
|
|
||||||
|
> In this issue, Chin et al. compare the accuracy of four high profile models that, early during the outbreak in the US, aimed to make quantitative predictions about deaths and Intensive Care Unit (ICU) bed utilization in New York. They find that all four models, though different in approach, failed not only to accurately predict the number of deaths and ICU utilization but also to describe uncertainty appropriately, particularly during the critical early phase of the epidemic. While overcoming these methodological challenges is key, Chin et al. also call for systemic advances including improving data quality, evaluating forecasts in real-time before policy use, and developing multi-model approaches.
|
||||||
|
|
||||||
|
> But what the model comparison by Chin et al. highlights is an important principle that many in the research community have understood for some time: that no single model should be used by policy makers to respond to a rapidly changing, highly uncertain epidemic, regardless of the institution or modeling group from which it comes. Due to the multiple uncertainties described above, even models using the same underlying data often have results that diverge because they have made different but reasonable assumptions about highly uncertain epidemiological parameters, and/or they use different methods
|
||||||
|
|
||||||
|
> .. the rapid deployment of this approach requires pre-existing infrastructure and evaluation systems now and for improved response to future epidemics. Many models that are built to forecast on a scale useful for local decision making are complex, and can take considerable time to build and calibrate
|
||||||
|
|
||||||
|
> a group with a history of successful influenza forecasting in the US (Los Alamos National Lab (4)) was able to produce early COVID-19 forecasts and had the best coverage of uncertainty in the Chin et al. analysis (80-100% of observations fell within the 95% prediction interval for most forecasts). In contrast, the new Institute for Health Metrics and Evaluation statistical approach had low reliability; after the latest analyzed revision only 53% of reported death counts fell with the 95% prediction intervals.
|
||||||
|
|
||||||
|
> The original IHME model underestimates uncertainty and 45.7% of the predictions (over 1- to 14-step-ahead predictions) made over the period March 24 to March 31 are outside the 95% PIs. In the revised model, for forecasts from of April 3 to May 3 the uncertainty bounds are enlarged, and most predictions (74.0%) are within the 95% PIs, which is not surprising given the PIs are in the order of 300 to 2000 daily deaths. Yet, even with this major revision, the claimed nominal coverage of 95% well exceeds the actual coverage. On May 4, the IHME model undergoes another major revision, and the uncertainty is again dramatically reduced with the result that 47.4% of the actual daily deaths fall outside the 95% PIs—well beyond the claimed 5% nominal value.
|
||||||
|
|
||||||
|
> the LANL model was the only model that was found to approach the 95% nominal coverage, but unfortunately this model was unavailable at the time Governor Cuomo needed to make major policy decisions in late March 2020.
|
||||||
|
|
||||||
|
> Models that are consistently poorly performing should carry less weight in shaping policy considerations. Models may be revised in the process, trying to improve performance. However, improvement of performance against retrospective data offers no guarantee for continued improvement in future predictions. Failed and recast models should not be given much weight in decision making until they have achieved a prospective track record that can instill some trust for their accuracy. Even then, real time evaluation should continue, since a model that performed well for a given period of time may fail to keep up under new circumstances.
|
||||||
|
|
||||||
|
[Do Prediction Markets Produce Well‐Calibrated Probability Forecasts?](https://academic.oup.com/ej/article-abstract/123/568/491/5079498).
|
||||||
|
|
||||||
|
> Abstract: This article presents new theoretical and empirical evidence on the forecasting ability of prediction markets. We develop a model that predicts that the time until expiration of a prediction market should negatively affect the accuracy of prices as a forecasting tool in the direction of a ‘favourite/longshot bias’. That is, high‐likelihood events are underpriced, and low‐likelihood events are over‐priced. We confirm this result using a large data set of prediction market transaction prices. Prediction markets are reasonably well calibrated when time to expiration is relatively short, but prices are significantly biased for events farther in the future. When time value of money is considered, the miscalibration can be exploited to earn excess returns only when the trader has a relatively low discount rate.
|
||||||
|
|
||||||
|
> We confirm this prediction using a data set of actual prediction markets prices from1,787 market representing a total of more than 500,000 transactions
|
||||||
|
|
||||||
|
Paul Christiano on [learning the Prior](https://ai-alignment.com/learning-the-prior-48f61b445c04) and on [better priors as a safety problem](https://ai-alignment.com/better-priors-as-a-safety-problem-24aa1c300710).
|
||||||
|
|
||||||
|
A presentation of [radical probabilism](https://www.lesswrong.com/posts/xJyY5QkQvNJpZLJRo/radical-probabilism-1); a theory of probability which relaxes some assumptions in classical Bayesian reasoning.
|
||||||
|
|
||||||
|
[Forecasting Thread: AI timelines](https://www.lesswrong.com/posts/hQysqfSEzciRazx8k/forecasting-thread-ai-timelines), which asks for (quantitative) forecasts until human-machine parity. Some of the answers seem insane or suspicious, in that they have very narrow tails, sharp spikes, and don't really update on the fact that other people disagree with them.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [there](https://archive.org/) and input the dead link.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
> *We hope that people will pressure each other into operationalizing their [big picture outlooks]. If we have no way of proving you wrong, we have no way of proving you right. We need falsifiable forecasts.*
|
||||||
|
|
||||||
|
> Source: Foretell Forecasting Forum. Inexact quote.
|
||||||
|
|
||||||
|
***
|
||||||
26
ea/ForecastingNewsletter/Header.md
Normal file
|
|
@ -0,0 +1,26 @@
|
||||||
|
## Footer:
|
||||||
|
Conflicts of interest: Marked as (c.o.i) throughout the text.
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [here](https://archive.org/)
|
||||||
|
|
||||||
|
## Email Newsletter
|
||||||
|
A forecasting digest with a focus on experimental forecasting. The newsletter itself is experimental, but there will be at least four more iterations. Click [here]() to view and discuss this on the EA forum; feedback is very welcome.
|
||||||
|
|
||||||
|
## Effective Altruism forum:
|
||||||
|
|
||||||
|
A forecasting digest with a focus on experimental forecasting. The newsletter itself is experimental, but there will be at least four more iterations; feedback is welcome. Feel free to use this post as a forecasting open thread.
|
||||||
|
|
||||||
|
- You can sign up [here](https://mailchi.mp/18fccca46f83/forecastingnewsletter).
|
||||||
|
- You can also see this post on LessWrong [here]()
|
||||||
|
- And the post is archived [here](https://nunosempere.github.io/ea/ForecastingNewsletter/)
|
||||||
|
|
||||||
|
Why is this relevant to Effective Altruism?
|
||||||
|
- Some items are immediately relevant (e.g., forecasts of famine).
|
||||||
|
- Others are projects whose success I'm cheering for, and which I think have the potential to do great amounts of good (e.g., Replication Markets).
|
||||||
|
- The remaining are relevant to the extent that cross-pollination of ideas is valuable.
|
||||||
|
- Forecasting may become a powerful tool for world-optimization, and EAs may want to avail themselves of this tool.
|
||||||
|
|
||||||
|
## LessWrong:
|
||||||
|
A forecasting digest with a focus on experimental forecasting. The newsletter itself is experimental, but there will be at least four more iterations. Feel free to use this post as a forecasting open thread.
|
||||||
|
- You can sign up [here](https://mailchi.mp/18fccca46f83/forecastingnewsletter).
|
||||||
|
- You can also see this post on the EA Forum [here]()
|
||||||
|
- And the post is archived [here](https://nunosempere.github.io/ea/ForecastingNewsletter/)
|
||||||
283
ea/ForecastingNewsletter/July2020.md
Normal file
|
|
@ -0,0 +1,283 @@
|
||||||
|
# Forecasting Newsletter. July 2020.
|
||||||
|
|
||||||
|
## Highlights
|
||||||
|
- Social Science Prediction Platform [launches](https://socialscienceprediction.org/).
|
||||||
|
- Ioannidis and Taleb [discuss](https://forecasters.org/blog/2020/06/14/covid-19-ioannidis-vs-taleb/) optimal response to COVID-19.
|
||||||
|
- Report tries to [foresee](https://reliefweb.int/report/world/forecasting-dividends-conflict-prevention-2020-2030) the (potentially quite high) dividends of conflict prevention from 2020 to 2030.
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Highlights.
|
||||||
|
- Prediction Markets & Forecasting Platforms.
|
||||||
|
- New undertakings.
|
||||||
|
- Negative Examples.
|
||||||
|
- News & Hard to Categorize Content.
|
||||||
|
- Long Content.
|
||||||
|
|
||||||
|
Sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020) or browse past newsletters [here](https://nunosempere.github.io/ea/ForecastingNewsletter/).
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting Platforms.
|
||||||
|
Ordered in subjective order of importance:
|
||||||
|
|
||||||
|
- Metaculus continues hosting great discussion.
|
||||||
|
- In particular, it has recently hosted some high-quality [AI questions](https://www.metaculus.com/questions/?search=cat:computing--ai).
|
||||||
|
- User @alexrjl, a moderator on the platform, [offers on the EA forum](https://forum.effectivealtruism.org/posts/5udsgcnK5Cii2vA9L/what-questions-would-you-like-to-see-forecasts-on-from-the) to operationalize questions and post them on Metaculus, for free. This hasn't been picked up by the EA Forum algorithms, but the offer seems to me to be quite valuable. Some examples of things you might want to see operationalized and forecasted: the funding your organization will receive in 2020, whether any particularly key bills will become law, whether GiveWell will change their top charities, etc.
|
||||||
|
|
||||||
|
- [Foretell](https://www.cset-foretell.com/) is a prediction market by the University of Georgetown's Center for Security and Emerging Technology, focused on questions relevant to technology-security policy, and on bringing those forecasts to policy-makers.
|
||||||
|
- Some EAs, such as myself or a mysterious user named *foretold*, feature on the top spots of their (admittedly quite young) leaderboard.
|
||||||
|
- I also have the opportunity to create a team on the site: if you have a proven track record and would be interested in joining such a team, get in touch at nuno.semperelh@gmail.com, before the 10th of August.
|
||||||
|
|
||||||
|
- [Replication Markets](https://predict.replicationmarkets.com/)
|
||||||
|
- published their [first paper](https://royalsocietypublishing.org/doi/10.1098/rsos.200566)
|
||||||
|
- had some difficulties with cheaters:
|
||||||
|
> "The Team at Replication Markets is delaying announcing the Round 8 Survey winners because of an investigation into coordinated forecasting among a group of participants. As a result, eleven accounts have been suspended and their data has been excluded from the study. Scores are being recalculated and prize announcements will go out soon."
|
||||||
|
- Because of how Replication Markets are structured, I'm betting the cheating was by manipulating the Keynesian beauty contest in a [Predict-O-Matic](https://www.lesswrong.com/posts/SwcyMEgLyd4C3Dern/the-parable-of-predict-o-matic) fashion. That is, cheaters could have coordinated to output something surprising during the Keynesian Beauty Contest round, and then make that surprising thing come to happen during the market trading round. Charles Twardy, principal investigator at Replication Markets, gives a more positive take on the Keynesian beauty contest aspects of Replication Markets [here](https://www.lesswrong.com/posts/M45QmAKGJWxuuiSbQ/forecasting-newsletter-may-2020?commentId=ckyk8AiiWuaqoy3dN).
|
||||||
|
|
||||||
|
- still have Round 10 open until the 3rd of August.
|
||||||
|
|
||||||
|
- At the Good Judgement family, Good Judgement Analytics continues to provide its [COVID-19 dashboard](https://goodjudgment.com/covidrecovery/).
|
||||||
|
> Modeling is a very good way to explain how a virus will move through an unconstrained herd. But when you begin to put in constraints” — mask mandates, stay-at-home orders, social distancing — “and then the herd has agency whether they’re going to comply, at that point, human forecasters who are very smart and have read through the models, that’s where they really begin to add value. – Marc Koehler, Vice President of Good Judgement, Inc., in a [recent interview](https://builtin.com/data-science/superforecasters-good-judgement)
|
||||||
|
|
||||||
|
|
||||||
|
- [Highly Speculative Estimates](https://www.highlyspeculativeestimates.com/dist-builder), an interface, library and syntax to produce distributional probabilistic estimates led by Ozzie Gooen, now accepts functions as part of its input, such that more complicated inputs like the following are now possible:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Variable: Number of ice creams an unsupervised child has consumed,
|
||||||
|
# when left alone in an ice cream shop.
|
||||||
|
|
||||||
|
# Current time (hours passed)
|
||||||
|
t=10
|
||||||
|
|
||||||
|
# Scenario with lots of uncertainty
|
||||||
|
w_1 = 0.75 ## Weight for this scenario.
|
||||||
|
min_uncertain(t) = t*2
|
||||||
|
max_uncertain(t) = t*20
|
||||||
|
|
||||||
|
# Optimistic scenario
|
||||||
|
w_2 = 0.25 ## Weight for the optimistic scenario
|
||||||
|
min_optimistic(t) = 1*t
|
||||||
|
max_optimistic(t) = 3*t
|
||||||
|
mean(t) = (min_optimistic(t) + max_optimistic(t)/2)
|
||||||
|
stdev(t) = t*(2)^(1/2)
|
||||||
|
|
||||||
|
# Overall guess
|
||||||
|
## A long-tailed lognormal for the uncertain scenario
|
||||||
|
## and a tight normal for the optimistic scenario
|
||||||
|
|
||||||
|
mm(min_uncertain(t) to max_uncertain(t), normal(mean(t), stdev(t)), [w_1, w_2])
|
||||||
|
|
||||||
|
## Compare with: mm(2 to 20, normal(2, 1.4142), [0.75, 0.25])
|
||||||
|
```
|
||||||
|
|
||||||
|
- [PredictIt](https://www.predictit.org/) & [Election Betting Odds](http://electionbettingodds.com/) each give a 60%-ish to Biden.
|
||||||
|
- See [Limits of Current US Prediction Markets (PredictIt Case Study)](https://www.lesswrong.com/posts/c3iQryHA4tnAvPZEv/limits-of-current-us-prediction-markets-predictit-case-study), on how spread, transaction fees, withdrawal fees, interest rate which one could otherwise be earning, taxes, and betting limits make it so that:
|
||||||
|
> "Current prediction markets are so bad in so many different ways that it simply is not surprising for people to know better than them, and it often is not possible for people to make money from knowing better."
|
||||||
|
|
||||||
|
- [Augur](https://www.augur.net/), a betting platform built on top of Ethereum, launches v2. Here are [two](https://bravenewcoin.com/insights/augur-price-analysis-v2-release-scheuled-for-june-12th) [overviews](https://www.coindesk.com/5-years-after-launch-predictions-market-platform-augur-releases-version-2) of the platform and of v2 modifications
|
||||||
|
|
||||||
|
### New undertakings
|
||||||
|
|
||||||
|
- [Announcing the Launch](http://evavivalt.com/2020/07/announcing-the-launch-of-the-social-science-prediction-platform) of the [Social Science Prediction Platform](https://socialscienceprediction.org/), a platform aimed at collecting and popularizing predictions of research results, in order to improve social science; see [this Science article](https://science.sciencemag.org/content/366/6464/428.full) for the background motivation:
|
||||||
|
> A new result builds on the consensus, or lack thereof, in an area and is often evaluated for how surprising, or not, it is. In turn, the novel result will lead to an updating of views. Yet we do not have a systematic procedure to capture the scientific views prior to a study, nor the updating that takes place afterward. What did people predict the study would find? How would knowing this result affect the prediction of findings of future, related studies?
|
||||||
|
|
||||||
|
> A second benefit of collecting predictions is that they [...] can also potentially help to mitigate publication bias. However, if priors are collected before carrying out a study, the results can be compared to the average expert prediction, rather than to the null hypothesis of no effect. This would allow researchers to confirm that some results were unexpected, potentially making them more interesting and informative, because they indicate rejection of a prior held by the research community; this could contribute to alleviating publication bias against null results.
|
||||||
|
|
||||||
|
> A third benefit of collecting predictions systematically is that it makes it possible to improve the accuracy of predictions. In turn, this may help with experimental design.
|
||||||
|
|
||||||
|
- On the one hand, I could imagine this having an impact, and the enthusiasm of the founders is contagious. On the other hand, as a forecaster I don't feel enticed by the platform: they offer a $25 reward to grad students (which I am not), and don't spell it out for me why I would want to forecast on their platform as opposed to on [all](http://metaculus.com/) [the](https://www.gjopen.com/) [other](https://replicationmarkets.com/) [alternatives](https://www.cset-foretell.com/) [available](https://thepipelineproject.org) [to](https://www.augur.net/) [me](https://www.predictit.org/), even accounting for altruistic impact.
|
||||||
|
|
||||||
|
- [Ought](https://www.lesswrong.com/posts/SmDziGM9hBjW9DKmf/2019-ai-alignment-literature-review-and-charity-comparison#Ought) is a research lab building tools to delegate open-ended reasoning to AI & ML systems.
|
||||||
|
- Since concluding their initial factored cognition experiments in 2019, they’ve been building tools to capture and automate the reasoning process in forecasting: [Ergo](https://github.com/oughtinc/ergo), a library for integrating model-based and judgmental forecasting, and [Elicit](https://elicit.ought.org), a tool built on top of Ergo to help forecasters express and share distributions.
|
||||||
|
- They’ve recently run small-scale tests exploring amplification and delegation of forecasting, such as: [Amplify Rohin’s Prediction on AGI researchers & Safety Concerns](https://www.lesswrong.com/posts/Azqmzp5JoXJihMcr4/competition-amplify-rohin-s-prediction-on-agi-researchers), [Amplified forecasting: What will Buck’s informed prediction of compute used in the largest ML training run before 2030 be?](https://www.metaculus.com/questions/4732/amplified-forecasting-what-will-bucks-informed-prediction-of-compute-used-in-the-largest-ml-training-run-before-2030-be/), and [Delegate a Forecast](https://forum.effectivealtruism.org/posts/GKnXGiobbg5PFikzJ/delegate-a-forecast).
|
||||||
|
- See also [Amplifying generalist research via forecasting](https://forum.effectivealtruism.org/posts/ZTXKHayPexA6uSZqE/part-2-amplifying-generalist-research-via-forecasting), previous work in a similar direction which was also inspired by Paul Christiano's Iterated Distillation and Amplification agenda.
|
||||||
|
- In addition to studying factored cognition in the forecasting context, they are broadly interested in whether the EA community could benefit from better forecasting tools: they can be reached out to team@ought.org if you want to give them feedback or discuss their work.
|
||||||
|
|
||||||
|
- [The Pipeline Project](https://thepipelineproject.org) is a project similar to Replication Markets, by some of the same authors, to find out whether people can predict whether a given study will replicate. They offer authorship in an appendix, as well as a chance to get a token monetary compensation.
|
||||||
|
|
||||||
|
- [USAID's Intelligent Forecasting: A Competition to Model Future Contraceptive Use](https://competitions4dev.org/forecastingprize/). "First, we will award up to 25,000 USD in prizes to innovators who develop an intelligent forecasting model—using the data we provide and methods such as artificial intelligence (AI)—to predict the consumption of contraceptives over three months. If implemented, the model should improve the availability of contraceptives and family planning supplies at health service delivery sites throughout a nationwide healthcare system. Second, we will award a Field Implementation Grant of approximately 100,000 to 200,000 USD to customize and test a high-performing intelligent forecasting model in Côte d’Ivoire."
|
||||||
|
|
||||||
|
- [Omen](omen.eth.link) is another cryptocurrency-based prediction market, which seems to use the same front-end (and probably back-end) as [Corona Information Markets](https://coronainformationmarkets.com/). It's unclear what their advantages with respect to Augur are.
|
||||||
|
|
||||||
|
- [Yngve Høiseth](https://github.com/yhoiseth/python-prediction-scorer) releases a prediction scorer, based on his previous work on Empiricast. In Python, but also available as a [REST](https://stackoverflow.com/questions/671118/what-exactly-is-restful-programming?rq=1) [API](https://predictionscorer.herokuapp.com/docs#/default/brier_score_v1_rules_brier_score__probability__get)
|
||||||
|
|
||||||
|
## Negative Examples.
|
||||||
|
|
||||||
|
- The International Energy Agency had terrible forecasts on solar photo-voltaic energy production, until [recently](https://pv-magazine-usa.com/2020/07/12/has-the-international-energy-agency-finally-improved-at-forecasting-solar-growth/):
|
||||||
|
> 
|
||||||
|
|
||||||
|
> ...It’s a scenario assuming current policies are kept and no new policies are added.
|
||||||
|
|
||||||
|
> ...the discrepancy basically implies that every year loads of unplanned subsidies are added... So it boils down to: it’s not a forecast and any error you find must be attributed to that. And no you cannot see how the model works.
|
||||||
|
|
||||||
|
> The IEA website explains the WEO process: “The detailed projections are generated by the World Energy Model, a large-scale simulation tool, developed at the IEA over a period of more than 20 years that is designed to replicate how energy markets function.”
|
||||||
|
|
||||||
|
## News & Hard to Categorize Content.
|
||||||
|
|
||||||
|
- [Budget credibility of subnational forecasts](http://www.levyinstitute.org/publications/budget-credibility-of-subnational-governments-analyzing-the-fiscal-forecasting-errors-of-28-states-in-india).
|
||||||
|
|
||||||
|
> Budget credibility, or the ability of governments to accurately forecast macro-fiscal variables, is crucial for effective public finance management. Fiscal marksmanship analysis captures the extent of errors in the budgetary forecasting... Partitioning the sources of errors, we identified that the errors were more broadly random than due to systematic bias, except for a few crucial macro-fiscal variables where improving the forecasting techniques can provide better estimates.
|
||||||
|
|
||||||
|
- See also: [How accurate are [US] agencies’ procurement forecasts?](https://federalnewsnetwork.com/contracting/2020/07/how-accurate-are-agencies-procurement-forecasts/) and [Forecasting Inflation in a Data-Rich Environment: The Benefits of Machine Learning Methods](https://www.tandfonline.com/doi/full/10.1080/07350015.2019.1637745) (which finds random forests a hard to beat approach)
|
||||||
|
|
||||||
|
- [Bloomberg on the IMF's track record on forecasting](https://www.bloomberg.com/graphics/2019-imf-forecasts/) ([archive link, without a paywall](http://archive.is/hj0CG)).
|
||||||
|
|
||||||
|
> A Bloomberg analysis of more than 3,200 same-year country forecasts published each spring since 1999 found a wide variation in the direction and magnitude of errors. In 6.1 percent of cases, the IMF was within a 0.1 percentage-point margin of error. The rest of the time, its forecasts underestimated GDP growth in 56 percent of cases and overestimated it in 44 percent. The average forecast miss, regardless of direction, was 2.0 percentage points, but obscures a notable difference between the average 1.3 percentage-point error for advanced economies compared with 2.1 percentage points for more volatile and harder-to-model developing economies. Since the financial crisis, however, the IMF’s forecast accuracy seems to have improved, as growth numbers have generally fallen.
|
||||||
|
|
||||||
|
> Banking and sovereign debt panics hit Greece, Ireland, Portugal and Cyprus to varying degrees, threatening the integrity of the euro area and requiring emergency intervention from multinational authorities. During this period, the IMF wasn’t merely forecasting what would happen to these countries but also setting the terms. It provided billions in bailout loans in exchange for implementation of strict austerity measures and other policies, often bitterly opposed by the countries’ citizens and politicians.
|
||||||
|
|
||||||
|
- I keep seeing evidence that Trump will lose reelection, but I don't know how seriously to take it, because I don't know how filtered it is.
|
||||||
|
- For example, the [The Economist's model](https://projects.economist.com/us-2020-forecast/president) forecasts 91% that Biden will win the upcoming USA elections. Should I update somewhat towards Biden winning after seeing it? What if I suspect that it's the most extreme model, and that it has come to my attention because of that fact? What if I suspect that it's the most extreme model which will predict a democratic win? What if there was another equally reputable model which predicts 91% for Trump, but which I never got to see because of information filter dynamics?
|
||||||
|
|
||||||
|
- The [the Primary Model](http://primarymodel.com/) confirmed my suspicions of filter dynamics. It "does not use presidential approval or the state of the economy as predictors. Instead it relies on the performance of the presidential nominees in primaries", and on how many terms the party has controlled the White House. The model has been developed by an [otherwise unremarkable](https://en.wikipedia.org/wiki/Helmut_Norpoth) professor of political science at New York's Stony Brook University, and has done well in previous election cycles. It assigns 91% to Trump winning reelection.
|
||||||
|
|
||||||
|
- [Forecasting at Uber: An Introduction](https://eng.uber.com/forecasting-introduction/). Uber forecasts demand so that they know amongst other things, when and where to direct their vehicles. Because of the challenges to testing and comparing forecasting frameworks at scale, they developed their own software for this.
|
||||||
|
|
||||||
|
- [Forecasting Sales In These Uncertain Times](https://www.forbes.com/sites/billconerly/2020/07/02/forecasting-sales-in-these-uncertain-times).
|
||||||
|
> [...] a company selling to lower-income consumers might use the monthly employment report for the U.S. to see how people with just a high school education are doing finding jobs. A business selling luxury goods might monitor the stock market.
|
||||||
|
|
||||||
|
- [Unilever Chief Supply Officer on forecasting](https://www.supplychaindive.com/news/unilever-csco-agility-forecasting-coronavirus/581323/): "Agility does trump forecasting. At the end of the day, every dollar we spent on agility has probably got a 10x return on every dollar spent on forecasting or scenario planning."
|
||||||
|
> An emphasis on agility over forecasting meant shortening planning cycles — the company reduced its planning horizon from 13 weeks to four. The weekly planning meeting became a daily meeting. Existing demand baselines and even artificial intelligence programs no longer applied as consumer spending and production capacity strayed farther from historical trends.
|
||||||
|
|
||||||
|
- [An updated introduction to prediction markets](https://daily.jstor.org/how-accurate-are-prediction-markets/), yet one which contains some nuggets I didn't know about.
|
||||||
|
|
||||||
|
> This bias toward favorable outcomes... appears for a wide variety of negative events, including diseases such as cancer, natural disasters such as earthquakes and a host of other events ranging from unwanted pregnancies and radon contamination to the end of a romantic relationship. It also emerges, albeit less strongly, for positive events, such as graduating from college, getting married and having favorable medical outcomes.
|
||||||
|
|
||||||
|
> Nancy Reagan hired an astrologer, Joan Quigley, to screen Ronald Reagan’s schedule of public appearances according to his horoscope, allegedly in an effort to avoid assassination attempts.
|
||||||
|
|
||||||
|
> Google, Yahoo!, Hewlett-Packard, Eli Lilly, Intel, Microsoft, and France Telecom have all used internal prediction markets to ask their employees about the likely success of new drugs, new products, future sales.
|
||||||
|
|
||||||
|
> Although prediction markets can work well, they don’t always. IEM, PredictIt, and the other online markets were wrong about Brexit, and they were wrong about Trump’s win in 2016. As the Harvard Law Review points out, they were also wrong about finding weapons of mass destruction in Iraq in 2003, and the nomination of John Roberts to the U.S. Supreme Court in 2005. There are also plenty of examples of small groups reinforcing each other’s moderate views to reach an extreme position, otherwise known as groupthink, a theory devised by Yale psychologist Irving Janis and used to explain the Bay of Pigs invasion.
|
||||||
|
|
||||||
|
> although thoughtful traders should ultimately drive the price, that doesn’t always happen. The [prediction] markets are also no less prone to being caught in an information bubble than British investors in the South Sea Company in 1720 or speculators during the tulip mania of the Dutch Republic in 1637.
|
||||||
|
|
||||||
|
- [Food Supply Forecasting Company gets $12 million in Series A funding](https://techcrunch.com/2020/07/15/crisp-the-platform-for-demand-forecasting-the-food-supply-chain-gets-12-million-in-funding/)
|
||||||
|
|
||||||
|
## Long Content.
|
||||||
|
|
||||||
|
- [Michael Story](https://twitter.com/MWStory/status/1281904682378629120), "Jotting down things I learned from being a superforecaster."
|
||||||
|
> Small teams of smart, focused and rational generalists can absolutely smash big well-resourced institutions at knowledge production, for the same reasons startups can beat big rich incumbent businesses
|
||||||
|
|
||||||
|
> There's a *lot* more to making predictive accuracy work in practice than winning a forecasting tournament. Competitions are about daily fractional updating, long lead times and exhaustive pre-forecast research on questions especially chosen for competitive suitability
|
||||||
|
|
||||||
|
> Real life forecasting often requires fast turnaround times, fuzzy questions, and difficult-to-define answers with unclear resolution criteria. In a competition, a question with ambiguous resolution is thrown out, but in a crisis it might be the most important work you do
|
||||||
|
|
||||||
|
- Lukas Gloor on [takeaways from Covid forecasting on Metaculus](https://forum.effectivealtruism.org/posts/xwG5MGWsMosBo6u4A/lukas_gloor-s-shortform?commentId=ZNgmZ7qvbQpy394kG)
|
||||||
|
|
||||||
|
- [Ambiguity aversion](https://en.wikipedia.org/wiki/Ambiguity_aversion). "Better the devil you know than the devil you don't."
|
||||||
|
|
||||||
|
> An ambiguity-averse individual would rather choose an alternative where the probability distribution of the outcomes is known over one where the probabilities are unknown. This behavior was first introduced through the [Ellsberg paradox](https://en.wikipedia.org/wiki/Ellsberg_paradox) (people prefer to bet on the outcome of an urn with 50 red and 50 blue balls rather than to bet on one with 100 total balls but for which the number of blue or red balls is unknown).
|
||||||
|
|
||||||
|
- Gregory Lewis: [Use uncertainty instead of imprecision](https://forum.effectivealtruism.org/posts/m65R6pAAvd99BNEZL/use-resilience-instead-of-imprecision-to-communicate).
|
||||||
|
> If your best guess for X is 0.37, but you're very uncertain, you still shouldn't replace it with an imprecise approximation (e.g. "roughly 0.4", "fairly unlikely"), as this removes information. It is better to offer your precise estimate, alongside some estimate of its resilience, either subjectively ("0.37, but if I thought about it for an hour I'd expect to go up or down by a factor of 2"), or objectively ("0.37, but I think the standard error for my guess to be ~0.1").
|
||||||
|
|
||||||
|
- [Expert Forecasting with and without Uncertainty Quantification and Weighting: What Do the Data Say?](https://www.rff.org/publications/journal-articles/expert-forecasting-and-without-uncertainty-quantification-and-weighting-what-do-data-say/): "it’s better to combine expert uncertainties (e.g. 90% confidence intervals) than to combine their point forecasts, and it’s better still to combine expert uncertainties based on their past performance."
|
||||||
|
- See also a [1969 paper](https://www.jstor.org/stable/pdf/3008764.pdf) by future Nobel Prize winner Clive Granger: "Two separate sets of forecasts of airline passenger data have been combined to form a composite set of forecasts. The main conclusion is that the composite set of forecasts can yield lower mean-square error than either of the original forecasts. Past errors of each of the original forecasts are used to determine the weights to attach to these two original forecasts in forming the combined forecasts, and different methods of deriving these weights are examined".
|
||||||
|
|
||||||
|
- [How to build your own weather forecasting model](https://www.yachtingmonthly.com/sailing-skills/how-to-build-your-own-weather-forcecast-73104). Sailors realize that weather forecasting are often corrupted by different considerations (e.g., a reported 50% of rain doesn't happen 50% of the time), and search for better sources. One such source is the original, raw data used to generate weather forecasts: GRIB files (Gridded Information in Binary), which lack interpretation. But these have their own pitfalls, which sailors must learn to take into account. For example, GRIB files only take into account wind speed, not tidal acceleration, which can cause a significant increase in apparent wind.
|
||||||
|
|
||||||
|
> ‘Forecasts are inherently political,’ says Dashew. ‘They are the result of people perhaps getting it wrong at some point so some pressures to interpret them in a different or more conservative way very often. These pressures change all the time so they are often subject to outside factors.’
|
||||||
|
|
||||||
|
> Singleton says he understands how pressures on forecasters can lead to this opinion being formed: ‘In my days at the Met Office when the Shipping Forecast used to work under me, they always said they try to tell it like it is and they do not try to make it sound worse.’
|
||||||
|
|
||||||
|
- [Forecasting the dividends of conflict prevention from 2020 - 2030](https://reliefweb.int/report/world/forecasting-dividends-conflict-prevention-2020-2030). Study quantifies the dynamics of conflict, building a transition matrix between different states (peace, high risk, negative peace, war, and recovery) and validating it using historical dataset; they find (concurring with the previous literature), that countries have a tendency to fall into cycles of conflict. They conclude that changing this transition matrix would have a very high impact. Warning: extensive quoting follows.
|
||||||
|
|
||||||
|
> Notwithstanding the mandate of the United Nations to promote peace and security, many member states are still sceptical about the dividends of conflict prevention. Their diplomats argue that it is hard to justify investments without being able to show its tangible returns to decision-makers and taxpayers. As a result, support for conflict prevention is halting and uneven, and governments and international agencies end up spending enormous sums in stability and peace support operations after-the-fact.
|
||||||
|
|
||||||
|
> This study considers the trajectories of armed conflict in a 'business-as-usual' scenario between 2020-2030. Specifically, it draws on a comprehensive historical dataset to determine the number of countries that might experience rising levels of collective violence, outright armed conflict, and their associated economic costs. It then simulates alternative outcomes if conflict prevention measures were 25%, 50%, and 75% more effective. As with all projections, the quality of the projections relies on the integrity of the underlying data. The study reviews several limitations of the analysis, and underlines the importance of a cautious interpretation of the findings.
|
||||||
|
|
||||||
|
> If current trends persist and no additional conflict prevention action is taken above the current baseline, then it is expected that there will be three more countries at war and nine more countries at high risk of war by 2030 as compared to 2020. This translates into roughly 677,250 conflict-related fatalities (civilian and battle-deaths) between the present and 2030. By contrast, under our most pessimistic scenario, a 25% increase in effectiveness of conflict prevention would result in 10 more countries at peace by 2030, 109,000 fewer fatalities over the next decade and savings of over $3.1 trillion. A 50% improvement would result in 17 additional countries at peace by 2030, 205,000 fewer deaths by 2030, and some $6.6 trillion in savings.
|
||||||
|
|
||||||
|
> Meanwhile, under our most optimistic scenario, a 75% improvement in prevention would result in 23 more countries at peace by 2030, resulting in 291,000 lives saved over the next decade and $9.8 trillion in savings. These scenarios are approximations, yet demonstrate concrete and defensible estimates of both the benefits (saved lives, displacement avoided, declining peacekeeping deployments) and cost-effectiveness of prevention (recovery aid, peacekeeping expenditures). Wars are costly and the avoidance of “conflict traps” could save the economy trillions of dollars by 2030 under the most optimistic scenarios. The bottom line is that comparatively modest investments in prevention can yield lasting effects by avoiding compounding costs of lost life, peacekeeping, and aid used for humanitarian response and rebuilding rather than development. The longer conflict prevention is delayed, the more expensive responses to conflict become.
|
||||||
|
|
||||||
|
> In order to estimate the dividends of conflict prevention we analyze violence dynamics in over 190 countries over the period 1994 to 2017, a time period for which most data was available for most countries. Drawing on 12 risk variables, the model examines the likelihood that a war will occur in a country in the following year and we estimate (through linear, fixed effects regressions) the average cost of war (and other ‘states’, described below) on 8 dependent variables, including loss of life, displacement, peacekeeping deployments and expenditures, oversea aid and economic growth. The estimates confirm that, by far, the most costly state for a country to be in is war, and the probability of a country succumbing to war in the next year is based on its current state and the frequency of other countries with similar states having entered war in the past.
|
||||||
|
|
||||||
|
> At the core of the model (and results) is the reality that countries tend to get stuck in so-called violence and conflict traps. A well-established finding in the conflict studies field is that once a country experiences an armed conflict, it is very likely to relapse into conflict or violence within a few years. Furthermore, countries likely to experience war share some common warning signs, which we refer to as “flags” (up to 12 flags can be raised to signal risk). Not all countries that enter armed conflict raise the same warning flags, but the warning flags are nevertheless a good indication that a country is at high risk. These effects create vicious cycles that result in high risk, war and frequent relapse into conflict. Multiple forms of prevention are necessary to break these cycles. The model captures the vicious cycle of conflict traps, through introducing five states and a transition matrix based on historical data (see Table 1). First, we assume that a country is in one of five 'states' in any given year. These ‘states’ are at "Peace", "High Risk", "Negative Peace", "War" and "Recovery" (each state is described further below). Drawing on historical data, the model assesses the probability of a country transitioning to another state in a given year (a transition matrix).
|
||||||
|
|
||||||
|
> For example, if a state was at High Risk in the last year, it has a 19.3% chance of transitioning to Peace, a 71.4% chance of staying High Risk, a 7.6% chance of entering Negative Peace and a 1.7% chance of entering War the following year.
|
||||||
|
|
||||||
|
> By contrast, high risk states are designated by the raising of up to 12 flags. These include: 1) high scores by Amnesty International's annual human rights reports (source: Political Terror Scale), 2) the US State Department annual reports (source: Political Terror Scale), 3) civilian fatalities as a percentage of population (source: ACLED), 4) political events per year (source: ACLED) 5) events attributed to the proliferation of non-state actors (source: ACLED), 6) battle deaths (source: UCDP), 7) deaths by terrorism (source: GTD), 8) high levels of crime (source: UNODC), 9) high levels of prison population (source: UNODC), 10) economic growth shocks (source: World Bank), 11) doubling of displacement in a year (source: IDMC), and 12) doubling of refugees in a year (source: UNHCR). Countries with two or more flags fall into the "high risk" category. Using these flags, a majority of countries have been at high risk for one or more years from 1994 to 2017, so it is easier to give examples of countries that have not been at high risk.
|
||||||
|
|
||||||
|
> Negative peace states are defined by combined scores from Amnesty International and the US State Department. Countries in negative peace are more than five times as likely to enter high risk in the following year than peace (26.8% vs. 4.1%).
|
||||||
|
|
||||||
|
> A country that is at war is one that falls into a higher threshold of collective violence, relative to the size of the population. Specifically, it is designated as such if one or more of the following conditions are met: above 0.04 battle deaths or .04 civilian fatalities per 100,000 according to UCDP and ACLED, respectively, or coding of genocide by the Political Instability Task Force Worldwide Atrocities Dataset. Countries experiencing five or more years of war between 1994 and 2017 included Afghanistan, Somalia, Sudan, Iraq, Burundi, Central African Republic, Sri Lanka, DR Congo, Uganda, Chad, Colombia, Israel, Lebanon, Liberia, Yemen, Algeria, Angola, Sierra Leone, South Sudan, Eritrea and Libya.
|
||||||
|
|
||||||
|
> Lastly, recovery is a period of stability that follows from war. A country is only determined to be recovering if it is not at war and was recently in a war. Any country that exits in the war state is immediately coded as being in recovery for the following five years, unless it relapses into war. The duration of the recovery period (five years) is informed by the work of Paul Collier et al, but is robust also to sensitivity tests around varying recovery lengths.
|
||||||
|
|
||||||
|
> The model does not allow for countries to be high risk and in recovery in the same year, but there is ample evidence that countries that are leaving a war state are at a substantially higher risk of experiencing war recurrence, contributing to the conflict trap described earlier. Countries are twice as likely to enter high risk or negative peace coming out of recovery as they are to enter peace, and 10.2% of countries in recovery relapse into war every year. When a country has passed the five year threshold without reverting to war, it can move back to states of peace, negative peace or high risk.
|
||||||
|
|
||||||
|
> The transition matrix underlines the very real risk of countries falling into a 'conflict trap'. Specifically, a country that is in a state of war has a very high likelihood of staying in this condition in the next year (72.6%) and just a 27.4% chance of transitioning to recovery. Once in recovery, a country has a 10.2% chance of relapse every year, suggesting only a 58% chance (1-10.2%)^5 that a country will not relapse over five years.
|
||||||
|
|
||||||
|
> As Collier and others have observed, countries are often caught in prolonged and vicious cycles of war and recovery (conflict traps), often unable to escape into a new, more peaceful (or less war-like) state
|
||||||
|
- War is expensive. So is being at high risk of war.
|
||||||
|
|
||||||
|
> Of course, the loss of life, displacement, and accumulated misery associated with war should be reason enough to invest in prevention, but there are also massive economic benefits from successful prevention. Foremost, the countries at war avoid the costly years in conflict, with growth rates 4.8% lower than countries at peace. They also avoid years of recovery and the risk of relapse into conflict. Where prevention works, conflict-driven humanitarian needs are reduced, and the international community avoids peacekeeping deployments and additional aid burdens, which are sizable.
|
||||||
|
|
||||||
|
> Conclusion: The world can be significantly better off by addressing the high risk of destructive violence and war with focused efforts at prevention in countries at high risk and those in negative peace. This group of countries has historically been at risk of higher conflict due to violence against civilians, proliferation of armed groups, abuses of human rights, forced displacement, high homicide, and incidence of t error. None of this is surprising. Policymakers know that war is bad for humans and other living things. What is staggering is the annual costs of war that we will continue to pay in 2030 through inaction today – conceivably trillions of dollars of economic growth, and the associated costs of this for human security and development, are being swept off t he table by the decisions made today to ignore prevention.
|
||||||
|
|
||||||
|
- [COVID-19: Ioannidis vs. Taleb](https://forecasters.org/blog/2020/06/14/covid-19-ioannidis-vs-taleb/)
|
||||||
|
|
||||||
|
> On the one hand, Nassim Taleb has clearly expressed that measures to stop the spread of the pandemic must be taken as soon as possible: instead of looking at data, it is the nature of a pandemic with a possibility of devastating human impact that should drive our decisions.
|
||||||
|
|
||||||
|
> On the other hand, John Ioannidis acknowledges the difficulty in having good data and of producing accurate forecasts, while believing that eventually any information that can be extracted from such data and forecasts should still be useful, e.g. to having targeted lockdowns (in space, time, and considering the varying risk for different segments of the population).
|
||||||
|
|
||||||
|
- [Taleb](https://forecasters.org/blog/2020/06/14/on-single-point-forecasts-for-fat-tailed-variables/): *On single point forecasts for fat tailed variables*. Leitmotiv: Pandemics are fat-tailed.
|
||||||
|
|
||||||
|
> 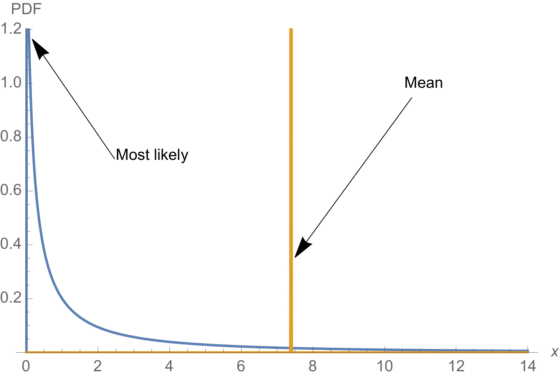
|
||||||
|
> 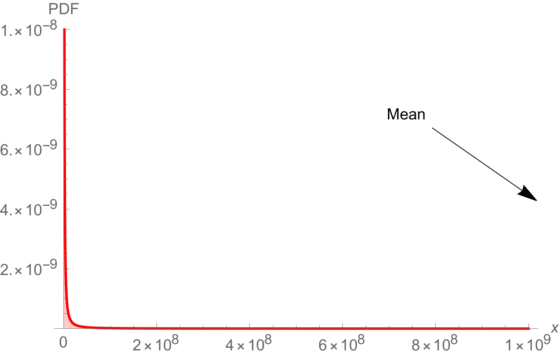
|
||||||
|
|
||||||
|
> We do not need more evidence under fat tailed distributions — it is there in the properties themselves (properties for which we have ample evidence) and these clearly represent risk that must be killed in the egg (when it is still cheap to do so). Secondly, unreliable data — or any source of uncertainty — should make us follow the most paranoid route. [...] more uncertainty in a system makes precautionary decisions very easy to make (if I am uncertain about the skills of the pilot, I get off the plane).
|
||||||
|
|
||||||
|
> Random variables in the power law class with tail exponent α ≤ 1 are, simply, not forecastable. They do not obey the [Law of Large Numbers]. But we can still understand their properties.
|
||||||
|
|
||||||
|
> As a matter of fact, owing to preasymptotic properties, a heuristic is to consider variables with up to α ≤ 5/2 as not forecastable — the mean will be too unstable and requires way too much data for it to be possible to do so in reasonable time. It takes 1014 observations for a “Pareto 80/20” (the most commonly referred to probability distribution, that is with α ≈ 1.13) for the average thus obtained to emulate the significance of a Gaussian with only 30 observations.
|
||||||
|
|
||||||
|
- [Ioannidis](https://forecasters.org/blog/2020/06/14/forecasting-for-covid-19-has-failed/): *Forecasting for COVID-19 has failed*. Leitmotiv: "Investment should be made in the collection, cleaning and curation of data".
|
||||||
|
|
||||||
|
> Predictions for hospital and ICU bed requirements were also entirely misinforming. Public leaders trusted models (sometimes even black boxes without disclosed methodology) inferring massively overwhelmed health care capacity (Table 1) [3]. However, eventually very few hospitals were stressed, for a couple of weeks. Most hospitals maintained largely empty wards, waiting for tsunamis that never came. The general population was locked and placed in horror-alert to save the health system from collapsing. Tragically, many health systems faced major adverse consequences, not by COVID-19 cases overload, but for very different reasons. Patients with heart attacks avoided visiting hospitals for care [4], important treatments (e.g. for cancer) were unjustifiably delayed [5], mental health suffered [6]. With damaged operations, many hospitals started losing personnel, reducing capacity to face future crises (e.g. a second wave). With massive new unemployment, more people may lose health insurance. The prospects of starvation and of lack of control for other infectious diseases (like tuberculosis, malaria, and childhood communicable diseases for which vaccination is hindered by the COVID-19 measures) are dire...
|
||||||
|
|
||||||
|
> The core evidence to support “flatten-the-curve” efforts was based on observational data from the 1918 Spanish flu pandemic on 43 US cities. These data are >100-years old, of questionable quality, unadjusted for confounders, based on ecological reasoning, and pertaining to an entirely different (influenza) pathogen that had ~100-fold higher infection fatality rate than SARS-CoV-2. Even thus, the impact on reduction on total deaths was of borderline significance and very small (10-20% relative risk reduction); conversely many models have assumed 25-fold reduction in deaths (e.g. from 510,000 deaths to 20,000 deaths in the Imperial College model) with adopted measures
|
||||||
|
|
||||||
|
> Despite these obvious failures, epidemic forecasting continued to thrive, perhaps because vastly erroneous predictions typically lacked serious consequences. Actually, erroneous predictions may have been even useful. A wrong, doomsday prediction may incentivize people towards better personal hygiene. Problems starts when public leaders take (wrong) predictions too seriously, considering them crystal balls without understanding their uncertainty and the assumptions made. Slaughtering millions of animals in 2001 aggravated a few animal business stakeholders, most citizens were not directly affected. However, with COVID-19, espoused wrong predictions can devastate billions of people in terms of the economy, health, and societal turmoil at-large.
|
||||||
|
|
||||||
|
> Cirillo and Taleb thoughtfully argue [14] that when it comes to contagious risk, we should take doomsday predictions seriously: major epidemics follow a fat-tail pattern and extreme value theory becomes relevant. Examining 72 major epidemics recorded through history, they demonstrate a fat-tailed mortality impact. However, they analyze only the 72 most noticed outbreaks, a sample with astounding selection bias. The most famous outbreaks in human history are preferentially selected from the extreme tail of the distribution of all outbreaks. Tens of millions of outbreaks with a couple deaths must have happened throughout time. Probably hundreds of thousands might have claimed dozens of fatalities. Thousands of outbreaks might have exceeded 1,000 fatalities. Most eluded the historical record. The four garden variety coronaviruses may be causing such outbreaks every year [15,16]. One of them, OC43 seems to have been introduced in humans as recently as 1890, probably causing a “bad influenza year” with over a million deaths [17]. Based on what we know now, SARS-CoV-2 may be closer to OC43 than SARS-CoV-1. This does not mean it is not serious: its initial human introduction can be highly lethal, unless we protect those at risk.
|
||||||
|
|
||||||
|
- The (British) Royal Economic Society presents a panel on [What is a scenario, projection and a forecast - how good or useful are they particularly now?](https://www.youtube.com/watch?v=2SUBlUINIqI). The start seems promising: "My professional engagement with economic and fiscal forecasting was first as a consumer, and then a producer. I spent a decade happily mocking other people's efforts, as a journalist, since when I've spent two decades helping colleagues to construct forecasts and to try to explain them to the public." The first speaker, which corresponds to the first ten minutes, is worth listening to; the rest varies in quality.
|
||||||
|
> You have to construct the forecast and explain it in a way that's fit for that purpose
|
||||||
|
|
||||||
|
- I liked the following taxonomy of what distinct targets the agency the first speaker works for is aiming to hit with their forecasts:
|
||||||
|
|
||||||
|
1. as an input into the policy-making process,
|
||||||
|
2. as a transparent assessment of public finances
|
||||||
|
3. as a prediction of whether the government will meet whatever fiscal rules it has set itself,
|
||||||
|
4. as a baseline against which to judge the significance of further news,
|
||||||
|
5. as a challenge to other agencies "to keep the bastards honest".
|
||||||
|
|
||||||
|
- The limitations were interesting as well:
|
||||||
|
|
||||||
|
1. they require us to produce a forecast that's conditioned on current government policy even if we and everyone else expect that policy to change that of course makes it hard to benchmark our performance against counterparts who are producing unconditional forecasts.
|
||||||
|
2. The forecasts have to be explainable; a black box model might be more accurate but be less useful.
|
||||||
|
3. they require detailed discussion of the individual forecast lines and clear diagnostics to explain changes from one forecast to the next precisely to reassure people that those changes aren't politically motivated or tainted - the forecast is as much about delivering transparency and accountability as about demonstrating predictive prowess
|
||||||
|
4. the forecast numbers really have to be accompanied by a comprehensible narrative of what is going on in the economy and the public finances and what impact policy will have - Parliament and the public needs to be able to engage with the forecast we couldn't justify our predictions simply with an appeal to a statistical black box and the Chancellor certainly couldn't justify significant policy positions that way.
|
||||||
|
|
||||||
|
> "horses for courses, the way you do the forecast, the way you present it depends on what you're trying to achieve with it"
|
||||||
|
|
||||||
|
> "People use scenario forecasting in a very informal manner. which I think that could be problematic because it's very difficult to basically find out what are the assumptions and whether those assumptions and the models and the laws can be validated"
|
||||||
|
|
||||||
|
> Linear models are state independent, but it's not the same to receive a shock where the economy is in upswing as when the economy is during a recession.
|
||||||
|
|
||||||
|
- Some situations are too complicated to forecast, so one conditions on some variables being known, or following a given path, and then studies the rest, calling the output a "scenario."
|
||||||
|
|
||||||
|
> One week delay in intervention by the government makes a big difference to the height of the [covid-19] curve.
|
||||||
|
|
||||||
|
> I don't think it's easy to follow the old way of doing things. I'm sorry, I have to be honest with you. I spent 4 months just thinking about this problem and you need to integrate a model of the social behavior and how you deal with the risk to health and to economy in these models. But unfortunately, by the time we do that it won't be relevant.
|
||||||
|
|
||||||
|
> It amuses me to look at weather forecasts because economists don't have that kind of technology, those kind of resources.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [here](https://archive.org/)
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
> "horses for courses, the way you do the forecast, the way you present it depends on what you're trying to achieve with it"
|
||||||
|
|
||||||
|
***
|
||||||
156
ea/ForecastingNewsletter/June2020.md
Normal file
|
|
@ -0,0 +1,156 @@
|
||||||
|
# Forecasting Newsletter. June 2020.
|
||||||
|
|
||||||
|
## Highlights
|
||||||
|
1. Facebook launches [Forecast](https://www.forecastapp.net/), a community for crowdsourced predictions.
|
||||||
|
2. Foretell, a forecasting tournament by the Center for Security and Emerging Technology, is now [open](www.cset-foretell.com).
|
||||||
|
3. [A Preliminary Look at Metaculus and Expert Forecasts](https://www.metaculus.com/news/2020/06/02/LRT/): Metaculus forecasters do better.
|
||||||
|
|
||||||
|
Sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020), view this newsletter on the EA Forum [here](), or browse past newsletters [here](https://nunosempere.github.io/ea/ForecastingNewsletter/)
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Highlights.
|
||||||
|
- In the News.
|
||||||
|
- Prediction Markets & Forecasting Platforms.
|
||||||
|
- Negative Examples.
|
||||||
|
- Hard to Categorize.
|
||||||
|
- Long Content.
|
||||||
|
|
||||||
|
## In the News.
|
||||||
|
|
||||||
|
- Facebook releases a forecasting app ([link to the app](https://www.forecastapp.net/), [press release](https://npe.fb.com/2020/06/23/forecast-a-community-for-crowdsourced-predictions-and-collective-insights/), [TechCrunch take](https://techcrunch.com/2020/06/23/facebook-tests-forecast-an-app-for-making-predictions-about-world-events-like-covid-19/), [hot-takes](https://cointelegraph.com/news/crypto-prediction-markets-face-competition-from-facebook-forecasts)). The release comes before Augur v2 launches, and it is easy to speculate that it might end up being combined with Facebook's stablecoin, Libra.
|
||||||
|
|
||||||
|
- The Economist has a new electoral model out ([article](https://www.economist.com/united-states/2020/06/11/meet-our-us-2020-election-forecasting-model), [model](https://projects.economist.com/us-2020-forecast/president)) which gives Trump an 11% chance of winning reelection. Given that Andrew Gelman was involved, I'm hesitant to criticize it, but it seems a tad overconfident. See [here](https://statmodeling.stat.columbia.edu/2020/06/19/forecast-betting-odds/) for Gelman addressing objections similar to my own.
|
||||||
|
|
||||||
|
- [COVID-19 vaccine before US election](https://www.aljazeera.com/ajimpact/wall-street-banking-covid-19-vaccine-election-200619204859320.html). Analysts see White House pushing through vaccine approval to bolster Trump's chances of reelection before voters head to polls. "All the datapoints we've collected make me think we're going to get a vaccine prior to the election," Jared Holz, a health-care strategist with Jefferies, said in a phone interview. The current administration is "incredibly incentivized to approve at least one of these vaccines before Nov. 3."
|
||||||
|
|
||||||
|
- ["Israeli Central Bank Forecasting Gets Real During Pandemic"](https://www.nytimes.com/reuters/2020/06/23/world/middleeast/23reuters-health-coronavirus-israel-cenbank.html). Israeli Central Bank is using data to which it has real-time access, like credit-card spending, instead of lagging indicators.
|
||||||
|
|
||||||
|
- [Google](https://www.forbes.com/sites/jeffmcmahon/2020/05/31/thanks-to-renewables-and-machine-learning-google-now-forecasts-the-wind/) produces wind schedules for wind farms. "The result has been a 20 percent increase in revenue for wind farms". See [here](https://www.pv-magazine-australia.com/2020/06/01/solar-forecasting-evolves/) for essentially the same thing on solar forecasting.
|
||||||
|
|
||||||
|
- Survey of macroeconomic researchers predicts economic recovery will take years, reports [538](https://fivethirtyeight.com/features/dont-expect-a-quick-recovery-our-survey-of-economists-says-it-will-likely-take-years/).
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting platforms.
|
||||||
|
|
||||||
|
Ordered in subjective order of importance:
|
||||||
|
|
||||||
|
- Foretell, a forecasting tournament by the Center for Security and Emerging Technology, is now [open](www.cset-foretell.com). I find the thought heartening that this might end up influencing bona-fide politicians.
|
||||||
|
|
||||||
|
- Metaculus
|
||||||
|
- posted [A Preliminary Look at Metaculus and Expert Forecasts](https://www.metaculus.com/news/2020/06/02/LRT/): Metaculus forecasters do better, and the piece is a nice reference point.
|
||||||
|
- was featured in [Forbes](https://www.forbes.com/sites/erikbirkeneder/2020/06/01/do-crowdsourced-predictions-show-the-wisdom-of-humans/#743b7e106d9d).
|
||||||
|
- announced their [Metaculus Summer Academy](https://www.metaculus.com/questions/4566/announcing-a-metaculus-academy-summer-series-for-new-forecasters/): "an introduction to forecasting for those who are relatively new to the activity and are looking for a fresh intellectual pursuit this summer"
|
||||||
|
|
||||||
|
|
||||||
|
- [Replication Markets](https://predict.replicationmarkets.com/) might add a new round with social and behavioral science claims related to COVID-19, and a preprint market, which would ask participants to forecast items like publication or citation. Replication Markets is also asking for more participants, with the catchline "If they are knowledgeable and opinionated, Replication Markets is the place to be to make your opinions really count."
|
||||||
|
|
||||||
|
- Good Judgement family
|
||||||
|
- [Good Judgement Open](https://www.gjopen.com/): Superforecasters were [able](https://www.gjopen.com/comments/1039968) to detect that Russia and the USA would in fact undertake some (albeit limited) form of negotiation, and do so much earlier than the general public, even while posting their reasons in full view.
|
||||||
|
- Good Judgement Analytics continues to provide its [COVID-19 dashboard](https://goodjudgment.com/covidrecovery/).
|
||||||
|
|
||||||
|
|
||||||
|
- [PredictIt](https://www.predictit.org/) & [Election Betting Odds](http://electionbettingodds.com/). I stumbled upon an old 538 piece on fake polls: [Fake Polls are a Real Problem](https://fivethirtyeight.com/features/fake-polls-are-a-real-problem/). Some polls may have been conducted by PredictIt traders in order to mislead or troll other PredictIt traders; all in all, an amusing example of how prediction markets could encourage worse information.
|
||||||
|
|
||||||
|
- [An online prediction market with reputation points](https://www.lesswrong.com/posts/sLbS93Fe4MTewFme3/an-online-prediction-market-with-reputation-points), implementing an [idea](https://sideways-view.com/2019/10/27/prediction-markets-for-internet-points/) by Paul Christiano. As of yet slow to load.
|
||||||
|
|
||||||
|
- Augur:
|
||||||
|
- [An overview of the platform and of v2 modifications](https://bravenewcoin.com/insights/augur-price-analysis-v2-release-scheuled-for-june-12th).
|
||||||
|
- Augur also happens to have a [blog](https://augur.substack.com/archive) with some interesting tidbits, such as the extremely clickbaity [How One Trader Turned $400 into $400k with Political Futures](https://augur.substack.com/p/how-one-trader-turned-400-into-400k) ("I find high volume markets...like the Democratic Nominee market or the 2020 Presidential Winner market... and what I’m doing is I’m just getting in line at the ‘buy’ price and waiting my turn until my orders get filled. Then when those orders get filled I just sell them for 1c more.")
|
||||||
|
|
||||||
|
|
||||||
|
- [Coronavirus Information Markets](https://coronainformationmarkets.com/) is down to ca. $12000 in trading volume; it seems like they didn't take off.
|
||||||
|
|
||||||
|
## Negative examples.
|
||||||
|
|
||||||
|
- World powers to converge on strategies for presenting COVID-19 information to make forecasters' jobs more interesting:
|
||||||
|
|
||||||
|
- [Brazil stops releasing COVID-19 death toll and wipes data from official site](https://www.theguardian.com/world/2020/jun/07/brazil-stops-releasing-covid-19-death-toll-and-wipes-data-from-official-site).
|
||||||
|
|
||||||
|
- Meanwhile, in Russia, [St Petersburg issues 1,552 more death certificates in May than last year, but Covid-19 toll was 171](https://www.theguardian.com/world/2020/jun/04/st-petersburg-death-tally-casts-doubt-on-russian-coronavirus-figures).
|
||||||
|
|
||||||
|
- In the US, [CDC wants states to count ‘probable’ coronavirus cases and deaths, but most aren’t doing it](https://www.washingtonpost.com/investigations/cdc-wants-states-to-count-probable-coronavirus-cases-and-deaths-but-most-arent-doing-it/2020/06/07/4aac9a58-9d0a-11ea-b60c-3be060a4f8e1_story.html)
|
||||||
|
|
||||||
|
- [India has the fourth-highest number of COVID-19 cases, but the Government denies community transmission](https://www.abc.net.au/news/2020-06-21/india-coronavirus-fourth-highest-covid19-community-transmission/12365738)
|
||||||
|
- One suspects that this denial is political, because India is otherwise [being](https://www.maritime-executive.com/editorials/advanced-cyclone-forecasting-is-saving-thousands-of-lives) [extremely](https://economictimes.indiatimes.com/news/politics-and-nation/world-meteorological-organization-appreciates-indias-highly-accurate-cyclone-forecasting-system/articleshow/76280763.cms) [competent](https://economictimes.indiatimes.com/news/politics-and-nation/mumbai-to-get-hyperlocal-rain-outlooks-flood-forecasting-launched/articleshow/76343558.cms) in weather forecasting.
|
||||||
|
|
||||||
|
- Youyang Gu's model, widely acclaimed as one of the best coronavirus models for the US, produces 95% confidence intervals which [seem too narrow](https://twitter.com/LinchZhang/status/1270443040860106753) when extended to [Pakistan](https://covid19-projections.com/pakistan).
|
||||||
|
|
||||||
|
- Some discussion on [twitter](https://twitter.com/vidur_kapur/status/1269749592867905537): "Only a fool would put a probability on whether the EU and the UK will agree a trade deal", says Financial Times correspondent, and other examples.
|
||||||
|
|
||||||
|
## Hard to categorize.
|
||||||
|
|
||||||
|
- [A Personal COVID-19 Postmortem](https://www.lesswrong.com/posts/B7sHnk8P8EXmpfyCZ/a-personal-interim-covid-19-postmortem), by FHI researcher [David Manheim](https://twitter.com/davidmanheim).
|
||||||
|
> I think it's important to clearly and publicly admit when we were wrong. It's even better to diagnose why, and take steps to prevent doing so again. COVID-19 is far from over, but given my early stance on a number of questions regarding COVID-19, this is my attempt at a public personal review to see where I was wrong.
|
||||||
|
|
||||||
|
- [FantasyScotus](https://fantasyscotus.net/user-predictions/case/altitude-express-inc-v-zarda/) beat [GoodJudgementOpen](https://www.gjopen.com/questions/1300-in-zarda-v-altitude-express-inc-will-the-supreme-court-rule-that-the-civil-rights-act-of-1964-prohibition-against-employment-discrimination-because-of-sex-encompasses-discrimination-based-on-an-individual-s-sexual-orientation) on legal decisions. I'm still waiting to see whether [Hollywood Stock Exchange](https://www.hsx.com/search/?action=submit_nav&keyword=Mulan&Submit.x=0&Submit.y=0) will also beat GJOpen on [film predictions](https://www.gjopen.com/questions/1608-what-will-be-the-total-domestic-box-office-gross-for-disney-s-mulan-as-of-8-september-2020-according-to-box-office-mojo).
|
||||||
|
|
||||||
|
- [How does pandemic forecasting resemble the early days of weather forecasting](https://www.foreignaffairs.com/articles/united-states/2020-06-29/how-forecast-outbreaks-and-pandemics); what lessons can the USA learn from the later about the former? An example would be to create an organization akin to the National Weather Center, but for forecasting.
|
||||||
|
|
||||||
|
- Linch Zhang, a COVID-19 forecaster with an excellent track-record, is doing an [Ask Me Anything](https://forum.effectivealtruism.org/posts/83rHdGWy52AJpqtZw/i-m-linch-zhang-an-amateur-covid-19-forecaster-and), starting on Sunday the 7th; questions are welcome!
|
||||||
|
|
||||||
|
- [The Rules To Being A Sellside Economist](https://blogs.tslombard.com/the-rules-to-being-a-sellside-economist). A fun read.
|
||||||
|
> 5) How to get attention: If you want to get famous for making big non-consensus calls, without the danger of looking like a muppet, you should adopt ‘the 40% rule’. Basically you can forecast whatever you want with a probability of 40%. Greece to quit the euro? Maybe! Trump to fire Powell and hire his daughter as the new Fed chair? Never say never! 40% means the odds will be greater than anyone else is saying, which is why your clients need to listen to your warning, but also that they shouldn’t be too surprised if, you know, the extreme event doesn’t actually happen.
|
||||||
|
|
||||||
|
- [How to improve space weather forecasting](https://eos.org/research-spotlights/how-to-improve-space-weather-forecasting) (see [here](https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2018SW002108#) for the original paper):
|
||||||
|
> For instance, the National Oceanic and Atmospheric Administration’s Deep Space Climate Observatory (DSCOVR) satellite sits at the location in space called L1, where the gravitational pulls of Earth and the Sun cancel out. At this point, which is roughly 1.5 million kilometers from Earth, or barely 1% of the way to the Sun, detectors can provide warnings with only short lead times: about 30 minutes before a storm hits Earth in most cases or as little as 17 minutes in advance of extremely fast solar storms.
|
||||||
|
|
||||||
|
- [Coup cast](https://oefresearch.org/activities/coup-cast): A site that estimates the yearly probability of a coup. The color coding is misleading; click on the countries instead.
|
||||||
|
|
||||||
|
- [Prediction = Compression](https://www.lesswrong.com/posts/hAvGi9YAPZAnnjZNY/prediction-compression-transcript-1). "Whenever you have a prediction algorithm, you can also get a correspondingly good compression algorithm for data you already have, and vice versa."
|
||||||
|
- Other LessWrong posts which caught my attention were [Betting with Mandatory Post-Mortem](https://www.lesswrong.com/posts/AM5JiWfmbAytmBq82/betting-with-mandatory-post-mortem) and [Radical Probabilism](https://www.lesswrong.com/posts/ZM63n353vh2ag7z4p/radical-probabilism-transcript)
|
||||||
|
|
||||||
|
- [Box Office Pro](https://www.boxofficepro.com/the-art-and-science-of-box-office-forecasting/) looks at some factors around box-office forecasting.
|
||||||
|
|
||||||
|
## Long Content.
|
||||||
|
|
||||||
|
- [When the crowds aren't wise](https://hbr.org/2006/09/when-crowds-arent-wise); a sober overview, with judicious use of [Cordocet's jury theorem](https://en.wikipedia.org/wiki/Condorcet's_jury_theorem)
|
||||||
|
> Suppose that each individual in a group is more likely to be wrong than right because relatively few people in the group have access to accurate information. In that case, the likelihood that the group’s majority will decide correctly falls toward zero as the size of the group increases.
|
||||||
|
|
||||||
|
> Some prediction markets fail for just this reason. They have done really badly in predicting President Bush’s appointments to the Supreme Court, for example. Until roughly two hours before the official announcement, the markets were essentially ignorant of the existence of John Roberts, now the chief justice of the United States. At the close of a prominent market just one day before his nomination, “shares” in Judge Roberts were trading at $0.19—representing an estimate that Roberts had a 1.9% chance of being nominated.
|
||||||
|
|
||||||
|
> Why was the crowd so unwise? Because it had little accurate information to go on; these investors, even en masse, knew almost nothing about the internal deliberations in the Bush administration. For similar reasons, prediction markets were quite wrong in forecasting that weapons of mass destruction would be found in Iraq and that special prosecutor Patrick Fitzgerald would indict Deputy Chief of Staff Karl Rove in late 2005.
|
||||||
|
|
||||||
|
- [A review of Tetlock’s ‘Superforecasting’ (2015)](https://dominiccummings.com/2016/11/24/a-review-of-tetlocks-superforecasting-2015/), by Dominic Cummings. Cummings then went on to hire one such superforecaster, which then resigned over a [culture war](https://www.bbc.com/news/uk-politics-51545541) scandal, characterized by adversarial selection of quotes which indeed are outside the British Overton Window. Notably, Dominic Cummings then told reporters to "Read Philip Tetlock's *Superforecasters*, instead of political pundits who don't know what they're talking about."
|
||||||
|
|
||||||
|
- [Assessing the Performance of Real-Time Epidemic Forecasts: A Case Study of *Ebola* in the Western Area Region of Sierra Leone, 2014-15](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6386417/). The one caveat is that their data is much better than coronavirus data, because Ebola symptoms are more evident; otherwise, pretty interesting:
|
||||||
|
> Real-time forecasts based on mathematical models can inform critical decision-making during infectious disease outbreaks. Yet, epidemic forecasts are rarely evaluated during or after the event, and there is little guidance on the best metrics for assessment.
|
||||||
|
|
||||||
|
> ...good probabilistic calibration was achievable at short time horizons of one or two weeks ahead but model predictions were increasingly unreliable at longer forecasting horizons.
|
||||||
|
|
||||||
|
> This suggests that forecasts may have been of good enough quality to inform decision making based on predictions a few weeks ahead of time but not longer, reflecting the high level of uncertainty in the processes driving the trajectory of the epidemic.
|
||||||
|
|
||||||
|
> Comparing different versions of our model to simpler models, we further found that it would have been possible to determine the model that was most reliable at making forecasts from early on in the epidemic. This suggests that there is value in assessing forecasts, and that it should be possible to improve forecasts by checking how good they are during an ongoing epidemic.
|
||||||
|
|
||||||
|
> One forecast that gained particular attention during the epidemic was published in the summer of 2014, projecting that by early 2015 there might be 1.4 million cases. This number was based on unmitigated growth in the absence of further intervention and proved a gross overestimate, yet it was later highlighted as a “call to arms” that served to trigger the international response that helped avoid the worst-case scenario.
|
||||||
|
|
||||||
|
> Methods to assess probabilistic forecasts are now being used in other fields, but are not commonly applied in infectious disease epidemiology
|
||||||
|
|
||||||
|
> The deterministic SEIR model we used as a null model performed poorly on all forecasting scores, and failed to capture the downturn of the epidemic in Western Area.
|
||||||
|
|
||||||
|
> On the other hand, a well-calibrated mechanistic model that accounts for all relevant dynamic factors and external influences could, in principle, have been used to predict the behaviour of the epidemic reliably and precisely. Yet, lack of detailed data on transmission routes and risk factors precluded the parameterisation of such a model and are likely to do so again in future epidemics in resource-poor settings.
|
||||||
|
|
||||||
|
- In the selection of quotes above, we gave an example of a forecast which ended up overestimating the incidence, yet might have "served as a call to arms". It's maybe a real-life example of a forecast changing the true result, leading to a fixed point problem, like the ones hypothesized in the parable of the [Predict-O-Matic](https://www.lesswrong.com/posts/SwcyMEgLyd4C3Dern/the-parable-of-predict-o-matic).
|
||||||
|
- It would be a fixed point problem if \[forecast above the alarm threshold\] → epidemic being contained, but \[forecast below the alarm thresold\] → epidemic not being contained.
|
||||||
|
- Maybe the fix-point solution, i.e., the most self-fulfilling (and thus, accurate) forecast, would have been a forecast on the edge of the alarm threshold, which would have ended up leading to mediocre containment.
|
||||||
|
- The [troll polls](https://fivethirtyeight.com/features/fake-polls-are-a-real-problem/) created by PredictIt traders are perhaps a more clear cut example of Predict-O-Matic problems.
|
||||||
|
|
||||||
|
- [Calibration Scoring Rules for Practical Prediction Training](https://arxiv.org/abs/1808.07501). I found it most interesting when considering how Brier and log rules didn't have all the pedagogic desiderata.
|
||||||
|
|
||||||
|
- I also found the following derivation of the logarithmic scoring rule interesting. Consider: If you assign a probability to n events, then the combined probability of these events is p1 x p2 x p3 x ... pn. Taking logarithms, this is log(p1 x p2 x p3 x ... x pn) = Σ log(pn), i.e., the logarithmic scoring rule.
|
||||||
|
|
||||||
|
- [Binary Scoring Rules that Incentivize Precision](https://arxiv.org/abs/2002.10669). The results (the closed-form of scoring rules which minimize a given forecasting error) are interesting, but the journey to get there is kind of a drag, and ultimately the logarithmic scoring rule ends up being pretty decent according to their measure of error.
|
||||||
|
|
||||||
|
- Opinion: I'm not sure whether their results are going to be useful for things I'm interested in (like human forecasting tournaments, rather than Kaggle data analysis competitions). In practice, what I might do if I wanted to incentivize precision is to ask myself if this is a question where the answer is going to be closer to 50%, or closer to either of 0% or 100%, and then use either the Brier or the logarithmic scoring rules. That is, I don't want to minimize an l-norm of the error over [0,1], I want to minimize an l-norm over the region I think the answer is going to be in, and the paper falls short of addressing that.
|
||||||
|
|
||||||
|
- [How Innovation Works—A Review](https://quillette.com/2020/05/29/how-innovation-works-a-review/). The following quote stood out for me:
|
||||||
|
> Ridley points out that there have always been opponents of innovation. Such people often have an interest in maintaining the status quo but justify their objections with reference to the precautionary principle.
|
||||||
|
|
||||||
|
- [A list of prediction markets](https://docs.google.com/spreadsheets/d/1XB1GHfizNtVYTOAD_uOyBLEyl_EV7hVtDYDXLQwgT7k/edit#gid=0), and their fates, maintained by Jacob Laguerros. Like most startups, most prediction markets fail.
|
||||||
|
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [here](https://archive.org/)
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
> "I beseech you, in the bowels of Christ, think it possible that you may be mistaken."
|
||||||
|
> [Oliver Cromwell](https://en.wikipedia.org/wiki/Cromwell%27s_rule)
|
||||||
|
|
||||||
|
***
|
||||||
27
ea/ForecastingNewsletter/March2020.md
Normal file
|
|
@ -0,0 +1,27 @@
|
||||||
|
What happened in forecasting in March 2020
|
||||||
|
==========================================
|
||||||
|
|
||||||
|
## Prediction platforms.
|
||||||
|
- Foretold has two communities on [Active Coronavirus Infections](https://www.foretold.io/c/1dd5b83a-075c-4c9f-b896-3172ec899f26) and [general questions on COVID](https://www.foretold.io/c/c47c6bc8-2c9b-4a83-9583-d1ed80a40fa2).
|
||||||
|
- Metaculus brings us the [The Li Wenliang prize series for forecasting the COVID-19 outbreak](https://www.metaculus.com/questions/3667/the-li-wenliang-prize-series-for-forecasting-the-covid-19-outbreak/), as well as the [Lockdown series](https://pandemic.metaculus.com/lockdown/) and many other [pandemic questions](https://www.metaculus.com/questions/?search=cat:series--pandemics)
|
||||||
|
- PredictIt: The odds of Trump winning the 2020 elections remain at a pretty constant 50%, oscillating between 45% and 57%.
|
||||||
|
- The Good Judgment Project has a selection of interesting questions, which aren't available unless one is a participant. A sample below (crowd forecast in parenthesis):
|
||||||
|
- Will the UN declare that a famine exists in any part of Ethiopia, Kenya, Somalia, Tanzania, or Uganda in 2020? (60%)
|
||||||
|
- In its January 2021 World Economic Outlook report, by how much will the International Monetary Fund (IMF) estimate the global economy grew in 2020? (Less than 1.5%: 94%, Between 1.5% and 2.0%, inclusive: 4%)
|
||||||
|
- Before 1 July 2020, will SpaceX launch its first crewed mission into orbit? (22%)
|
||||||
|
- Before 1 January 2021, will the Council of the European Union request the consent of the European Parliament to conclude a European Union-United Kingdom trade agreement? (25%)
|
||||||
|
- Will Benjamin Netanyahu cease to be the prime minister of Israel before 1 January 2021? (50%)
|
||||||
|
- Before 1 January 2021, will there be a lethal confrontation between the national military or law enforcement forces of Iran and Saudi Arabia either in Iran or at sea? (20%)
|
||||||
|
- Before 1 January 2021, will a United States Supreme Court seat be vacated? (No: 55%, Yes, and a replacement Justice will be confirmed by the Senate before 1 January 2021: 25%, Yes, but no replacement Justice will be confirmed by the Senate before 1 January 2021: 20%)
|
||||||
|
- Will the United States experience at least one quarter of negative real GDP growth in 2020? (75%)
|
||||||
|
- Who will win the 2020 United States presidential election? (The Republican Party nominee: 50%, The Democratic Party nominee: 50%, Another candidate: 0%)
|
||||||
|
- Before 1 January 2021, will there be a lethal confrontation between the national military forces of Iran and the United States either in Iran or at sea? (20%)
|
||||||
|
- Will Nicolas Maduro cease to be president of Venezuela before 1 June 2020? (10%)
|
||||||
|
- When will the Transportation Security Administration (TSA) next screen two million or more travelers in a single day? (Not before 1 September 2020: 66%, Between 1 August 2020 and 31 August 2020: 17%, Between 1 July 2020 and 31 July 2020: 11%, Between 1 June 2020 and 30 June 2020: 4%, Before 1 June 2020: 2%)
|
||||||
|
|
||||||
|
## Misc.
|
||||||
|
- [The Brookings institution](https://www.brookings.edu/blog/order-from-chaos/2020/04/03/forecasting-energy-futures-amid-the-coronavirus-outbreak/), on Forecasting energy futures amid the coronavirus outbreak
|
||||||
|
- The [European Statistical Service]() is "a partnership between Eurostat and national statistical institutes or other national authorities in each European Union (EU) Member State responsible for developing, producing and disseminating European statistics". In this time of need, the ESS brings us inane information, like "consumer prices increased by 0.1% in March in Switzerland".
|
||||||
|
- Famine: The [famine early warning system](https://fews.net/) gives emergency and crisis warnings for East Africa.
|
||||||
|
- COVID: Everyone and their mother have been trying to predict the future of COVID. One such initiative is [Epidemic forecasting](http://epidemicforecasting.org/), which uses inputs from the above mentioned prediction platforms.
|
||||||
|
- On LessWrong, [Assessing Kurzweil's 1999 predictions for 2019](https://www.lesswrong.com/posts/GhDfTAtRMxcTqAFmc/assessing-kurzweil-s-1999-predictions-for-2019); I expect an accuracy of between [30% and 40%](https://nunosempere.github.io/rat/KurzweilPredictionsForThe2010s.html), based on my own investigatiobns but find the idea of crowdsourcing the assessment rather interesting.
|
||||||
230
ea/ForecastingNewsletter/May2020.md
Normal file
|
|
@ -0,0 +1,230 @@
|
||||||
|
Whatever happened to forecasting? May 2020
|
||||||
|
====================================================
|
||||||
|
|
||||||
|
A forecasting digest with a focus on experimental forecasting. The newsletter itself is experimental, but there will be at least four more iterations; feedback is welcome.
|
||||||
|
|
||||||
|
- You can sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020).
|
||||||
|
- You can also see this post on the EA forum [here](https://forum.effectivealtruism.org/posts/TDssNnJsZmiLkhzC4/forecasting-newsletter-may-2020), or in LessWrong [here](https://www.lesswrong.com/posts/M45QmAKGJWxuuiSbQ/forecasting-newsletter-may-2020)
|
||||||
|
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Prediction Markets & Forecasting platforms.
|
||||||
|
- Augur.
|
||||||
|
- Coronavirus Information Markets.
|
||||||
|
- CSET: Foretell.
|
||||||
|
- Epidemic forecasting (c.o.i).
|
||||||
|
- Foretold. (c.o.i).
|
||||||
|
- /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
|
||||||
|
- Metaculus.
|
||||||
|
- PredictIt & Election Betting Odds.
|
||||||
|
- Replication Markets.
|
||||||
|
- In the News.
|
||||||
|
- Grab bag.
|
||||||
|
- Negative examples.
|
||||||
|
- Long Content.
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting platforms.
|
||||||
|
|
||||||
|
### Augur: [augur.net](https://www.augur.net/)
|
||||||
|
|
||||||
|
Augur is a decentralized prediction market. [Here](https://bravenewcoin.com/insights/augur-price-analysis-token-success-hinges-on-v2-release-in-june) is a fine piece of reporting outlining how it operates and the road ahead.
|
||||||
|
|
||||||
|
### Coronavirus Information Markets: [coronainformationmarkets.com](https://coronainformationmarkets.com/)
|
||||||
|
For those who want to put their money where their mouth is, this is a prediction market for coronavirus related information.
|
||||||
|
|
||||||
|
Making forecasts is tricky, so would-be-bettors might be better off pooling their forecasts together with a technical friend. As of the end of this month, the total trading volume of active markets sits at $26k+ (upwards from $8k last month), and some questions have been resolved already.
|
||||||
|
|
||||||
|
Further, according to their FAQ, participation from the US is illegal: *"Due to the US position on information markets, US citizens and residents, wherever located, and anyone physically present in the USA may not participate in accordance with our Terms."* Nonetheless, one might take the position that the US legal framework on information markets is so dumb as to be illegitimate.
|
||||||
|
|
||||||
|
### CSET: Foretell
|
||||||
|
|
||||||
|
The [Center for Security and Emerging Technology](https://cset.georgetown.edu/) is looking for (unpaid, volunteer) forecasters to predict the future to better inform policy decisions. The idea would be that as emerging technologies pose diverse challenges, forecasters and forecasting methodologies with a good track record might be a valuable source of insight and advice to policymakers.
|
||||||
|
|
||||||
|
One can sign-up on [their webpage](https://www.cset-foretell.com/). CSET was previously funded by the [Open Philanthropy Project](https://www.openphilanthropy.org/giving/grants/georgetown-university-center-security-and-emerging-technology); the grant writeup contains some more information.
|
||||||
|
|
||||||
|
### Epidemic Forecasting: [epidemicforecasting.org](http://epidemicforecasting.org/) (c.o.i)
|
||||||
|
|
||||||
|
As part of their efforts, the Epidemic Forecasting group had a judgemental forecasting team that worked on a variety of projects; it was made up of forecasters who have done well on various platforms, including a few who were official Superforecasters.
|
||||||
|
|
||||||
|
They provided analysis and forecasts to countries and regions that needed it, and advised a vaccine company on where to locate trials with as many as 100,000 participants. I worked a fair bit on this; hopefully more will be written publicly later on about these processes.
|
||||||
|
|
||||||
|
They've also been working on a mitigation calculator, and on a dataset of COVID-19 containment and mitigation measures.
|
||||||
|
|
||||||
|
Now they’re looking for a project manager to take over: see [here](https://www.lesswrong.com/posts/ecyYjptcE34qAT8Mm/job-ad-lead-an-ambitious-covid-19-forecasting-project) for the pitch and for some more information.
|
||||||
|
|
||||||
|
### Foretold: [foretold.io](https://www.foretold.io/) (c.o.i)
|
||||||
|
|
||||||
|
I personally added a distribution drawer to the [Highly Speculative Estimates](https://www.highlyspeculativeestimates.com/drawer) utility, for use within the Epidemic Forecasting forecasting efforts; the tool can be used to draw distributions and send them off to be used in Foretold. Much of the code for this was taken from Evan Ward’s open-sourced [probability.dev](https://probability.dev/) tool.
|
||||||
|
|
||||||
|
### /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
|
||||||
|
|
||||||
|
(The title of this section is a [regular expression](https://en.wikipedia.org/wiki/Regular_expression), so as to accept only one meaning, be maximally unambiguous, yet deal with the complicated corporate structure of Good Judgement.)
|
||||||
|
|
||||||
|
Good Judgement Inc. is the organization which grew out of Tetlock's research on forecasting, and out of the Good Judgement Project, which won the [IARPA ACE forecasting competition](https://en.wikipedia.org/wiki/Aggregative_Contingent_Estimation_(ACE)_Program), and resulted in the research covered in the *Superforecasting* book.
|
||||||
|
|
||||||
|
Good Judgement Inc. also organizes the Good Judgement Open [gjopen.com](https://www.gjopen.com/), a forecasting platform open to all, with a focus on serious geopolitical questions. They structure their questions in challenges. Of the currently active questions, here is a selection of those I found interesting (probabilities below):
|
||||||
|
- [Before 1 January 2021, will the People's Liberation Army (PLA) and/or People’s Armed Police (PAP) be mobilized in Hong Kong?](https://www.gjopen.com/questions/1499-before-1-january-2021-will-the-people-s-liberation-army-pla-and-or-people-s-armed-police-pap-be-mobilized-in-hong-kong)
|
||||||
|
- [Will the winner of the popular vote in the 2020 United States presidential election also win the electoral college?](https://www.gjopen.com/questions/1495-will-the-winner-of-the-popular-vote-in-the-2020-united-states-presidential-election-also-win-the-electoral-college)- This one is interesting, because it has infrequently gone the other way historically, but 2/5 of the last USA elections were split.
|
||||||
|
- [Will Benjamin Netanyahu cease to be the prime minister of Israel before 1 January 2021?](https://www.gjopen.com/questions/1498-will-benjamin-netanyahu-cease-to-be-the-prime-minister-of-israel-before-1-january-2021). Just when I thought he was out, he pulls himself back in.
|
||||||
|
- [Before 28 July 2020, will Saudi Arabia announce the cancellation or suspension of the Hajj pilgrimage, scheduled for 28 July 2020 to 2 August 2020?](https://www.gjopen.com/questions/1621-before-28-july-2020-will-saudi-arabia-announce-the-cancellation-or-suspension-of-the-hajj-pilgrimage-scheduled-for-28-july-2020-to-2-august-2020)
|
||||||
|
- [Will formal negotiations between Russia and the United States on an extension, modification, or replacement for the New START treaty begin before 1 October 2020?](https://www.gjopen.com/questions/1551-will-formal-negotiations-between-russia-and-the-united-states-on-an-extension-modification-or-replacement-for-the-new-start-treaty-begin-before-1-october-2020)s
|
||||||
|
|
||||||
|
Probabilities: 25%, 75%, 40%, 62%, 20%
|
||||||
|
|
||||||
|
On the Good Judgement Inc. side, [here](https://goodjudgment.com/covidrecovery/) is a dashboard presenting forecasts related to covid. The ones I found most worthy are:
|
||||||
|
- [When will the FDA approve a drug or biological product for the treatment of COVID-19?](https://goodjudgment.io/covid-recovery/#1384)
|
||||||
|
- [Will the US economy bounce back by Q2 2021?](https://goodjudgment.io/covid-recovery/#1373)
|
||||||
|
- [What will be the U.S. civilian unemployment rate (U3) for June 2021?](https://goodjudgment.io/covid-recovery/#1374)
|
||||||
|
- [When will enough doses of FDA-approved COVID-19 vaccine(s) to inoculate 25 million people be distributed in the United States?](https://goodjudgment.io/covid-recovery/#1363)
|
||||||
|
|
||||||
|
Otherwise, for a recent interview with Tetlock, see [this podcast](https://medium.com/conversations-with-tyler/philip-tetlock-tyler-cowen-forecasting-sociology-30401464b6d9), by Tyler Cowen.
|
||||||
|
|
||||||
|
### Metaculus: [metaculus.com](https://www.metaculus.com/)
|
||||||
|
|
||||||
|
Metaculus is a forecasting platform with an active community and lots of interesting questions. In their May pandemic newsletter, they emphasized having "all the benefits of a betting market but without the actual betting", which I found pretty funny.
|
||||||
|
|
||||||
|
This month they've organized a flurry of activities, most notably:
|
||||||
|
- [The Salk Tournament](https://pandemic.metaculus.com/questions/4093/the-salk-tournament-for-coronavirus-sars-cov-2-vaccine-rd/) on vaccine development
|
||||||
|
- [The El Paso Series](https://pandemic.metaculus.com/questions/4161/el-paso-series-supporting-covid-19-response-planning-in-a-mid-sized-city/) on collaboratively predicting peaks.
|
||||||
|
- [The Lightning Round Tournament](https://pandemic.metaculus.com/questions/4166/the-lightning-round-tournament-comparing-metaculus-forecasters-to-infectious-disease-experts/), in which metaculus forecasters go head to head against expert epidemiologists.
|
||||||
|
- They also present a [Covid dashboard](https://pandemic.metaculus.com/COVID-19/).
|
||||||
|
|
||||||
|
### Predict It & Election Betting Odds: [predictIt.org](https://www.predictit.org/) & [electionBettingOdds.com](http://electionbettingodds.com/)
|
||||||
|
|
||||||
|
PredictIt is a prediction platform restricted to US citizens, but also accessible with a VPN. This month, they present a map about the electoral college result in the USA. States are colored according to the market prices:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Some of the predictions I found most interesting follow. The market probabilities can be found below; the engaged reader might want to write down their own probabilities and then compare.
|
||||||
|
- [Will Benjamin Netanyahu be prime minister of Israel on Dec. 31, 2020?](https://www.predictit.org/markets/detail/6238/Will-Benjamin-Netanyahu-be-prime-minister-of-Israel-on-Dec-31,-2020)
|
||||||
|
- [Will Trump meet with Kim Jong-Un in 2020?](https://www.predictit.org/markets/detail/6265/Will-Trump-meet-with-Kim-Jong-Un-in-2020)
|
||||||
|
- [Will Nicolás Maduro be president of Venezuela on Dec. 31, 2020?](https://www.predictit.org/markets/detail/6237/Will-Nicol%C3%A1s-Maduro-be-president-of-Venezuela-on-Dec-31,-2020)
|
||||||
|
- [Will Kim Jong-Un be Supreme Leader of North Korea on Dec. 31?](https://www.predictit.org/markets/detail/6674/Will-Kim-Jong-Un-be-Supreme-Leader-of-North-Korea-on-Dec-31)
|
||||||
|
- [Will a federal charge against Barack Obama be confirmed before November 3?](https://www.predictit.org/markets/detail/6702/Will-a-federal-charge-against-Barack-Obama-be-confirmed-before-November-3)
|
||||||
|
|
||||||
|
Some of the most questionable markets are:
|
||||||
|
- [Will Trump switch parties by Election Day 2020?](https://www.predictit.org/markets/detail/3731/Will-Trump-switch-parties-by-Election-Day-2020)
|
||||||
|
- [Will Michelle Obama run for president in 2020?](https://www.predictit.org/markets/detail/4632/Will-Michelle-Obama-run-for-president-in-2020)
|
||||||
|
- [Will Hillary Clinton run for president in 2020?](https://www.predictit.org/markets/detail/4614/Will-Hillary-Clinton-run-for-president-in-2020)
|
||||||
|
|
||||||
|
Market probabilities are: 76%, 9%, 75%, 82%, 8%, 2%, 6%, 11%.
|
||||||
|
|
||||||
|
[Election Betting Odds](https://electionbettingodds.com/) aggregates PredictIt with other such services for the US presidential elections, and also shows an election map. The creators of the webpage used its visibility to promote [ftx.com](https://ftx.com/), another platform in the area, whose webpage links to effective altruism and mentions:
|
||||||
|
|
||||||
|
> FTX was founded with the goal of donating to the world’s most effective charities. FTX, its affiliates, and its employees have donated over $10m to help save lives, prevent suffering, and ensure a brighter future.
|
||||||
|
|
||||||
|
### Replication Markets: [replicationmarkets.com](https://www.replicationmarkets.com)
|
||||||
|
On Replication Markets, volunteer forecasters try to predict whether a given study's results will be replicated with high power. Rewards are monetary, but only given out to the top few forecasters, and markets suffer from sometimes being dull.
|
||||||
|
|
||||||
|
The first week of each round is a survey round, which has some aspects of a Keynesian beauty contest, because it's the results of the second round, not the ground truth, what is being forecasted. This second round then tries to predict what would happen if the studies were in fact subject to a replication, which a select number of studies then undergo.
|
||||||
|
|
||||||
|
There is a part of me which dislikes this setup: here was I, during the first round, forecasting to the best of my ability, when I realize that in some cases, I'm going to improve the aggregate and be punished for this, particularly when I have information which I expect other market participants to not have.
|
||||||
|
|
||||||
|
At first I thought that, cunningly, the results of the first round would be used as priors for the second round, but a [programming mistake](https://www.replicationmarkets.com/index.php/2020/05/12/we-just-gave-all-our-forecasters-130-more-points/) by the organizers revealed that they use a simple algorithm: claims with p < .001 start with a prior of 80%, p < .01 starts at 40%, and p < .05 starts at 30%.
|
||||||
|
|
||||||
|
## In The News.
|
||||||
|
Articles and announcements in more or less traditional news media.
|
||||||
|
|
||||||
|
- [Locust-tracking application for the UN](https://www.research.noaa.gov/article/ArtMID/587/ArticleID/2620/NOAA-teams-with-the-United-Nations-to-create-locust-tracking-application) (see [here](https://www.washingtonpost.com/weather/2020/05/13/east-africa-locust-forecast-tool/) for a take by the Washington Post), using software originally intended to track the movements of air pollution. NOAA also sounds like a valuable organization: "NOAA Research enables better forecasts, earlier warnings for natural disasters, and a greater understanding of the Earth. Our role is to provide unbiased science to better manage the environment, nationally, and globally."
|
||||||
|
- [United Nations: World Economic Situation and Prospects as of mid-2020](https://www.un.org/development/desa/dpad/publication/world-economic-situation-and-prospects-as-of-mid-2020/). A recent report is out, which predicts a 3.2% contraction of the global economy. Between 34 and 160 million people are expected to fall below the extreme poverty line this year. Compare with [Fitch ratings](https://www.fitchratings.com/research/sovereigns/further-economic-forecast-cuts-global-recession-bottoming-out-26-05-2020), which foresee a 4.6% decline in global GDP.
|
||||||
|
- [Fox News](https://www.fox10phoenix.com/news/cdc-says-all-models-forecast-increase-in-covid-19-deaths-in-coming-weeks-exceeding-100k-by-june-1) and [Business Insider](https://www.businessinsider.com/cdc-forecasts-100000-coronavirus-deaths-by-june-1-2020-5?r=KINDLYSTOPTRACKINGUS) report about the CDC forecasting 100k deaths by June the 1st, differently.
|
||||||
|
- Some transient content on 538 about [Biden vs past democratic nominees](https://fivethirtyeight.com/features/how-does-biden-stack-up-to-past-democratic-nominees/), about [Trump vs Biden polls](https://fivethirtyeight.com/features/you-can-pay-attention-to-those-trump-vs-biden-polls-but-be-cautious/) and about [the USA vicepresidential draft](https://fivethirtyeight.com/features/its-time-for-another-2020-vice-presidential-draft/), and an old [review of the impact of VP candidates in USA elections](http://baseballot.blogspot.com/2012/07/politically-veepstakes-isnt-worth.html) which seems to have aged well. 538 also brings us this overview of [models with unrealistic-yet-clearly-stated assumptions](https://projects.fivethirtyeight.com/covid-forecasts/.)
|
||||||
|
- [Why Economic Forecasting Is So Difficult in the Pandemic](https://hbr.org/2020/05/why-economic-forecasting-is-so-difficult-in-the-pandemic). Harvard Review Economists share their difficulties. Problems include "not knowing for sure what is going to happen", the government passing legislation uncharacteristically fast, sampling errors and reduced response rates from surveys, and lack of knowledge about epidemiology.
|
||||||
|
- [IBM releases new AI forecasting tool](https://www.ibm.com/products/planning-analytics): "IBM Planning Analytics is an AI-infused integrated planning solution that automates planning, forecasting and budgeting." See [here](https://www.channelasia.tech/article/679887/ibm-adds-ai-fuelled-forecasting-planning-analytics-platform/) or [here](https://www.cio.com/article/3544611/ibm-adds-ai-fueled-forecasting-to-planning-analytics-platform.html) for a news take.
|
||||||
|
- Yahoo has automated finance forecast reporting. It took me a while (two months) to notice that the low-quality finance articles that were popping up in my google alerts were machine-generated. See [Synovus Financial Corp. Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now](https://finance.yahoo.com/news/synovus-financial-corp-earnings-missed-152645825.html), [Wienerberger AG Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now](https://finance.yahoo.com/news/wienerberger-ag-earnings-missed-analyst-070545629.html), [Park Lawn Corporation Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now](https://news.yahoo.com/park-lawn-corporation-earnings-missed-120314826.html); they have a similar structure, paragraph per paragraph, and seem to have been generated from a template which changes a little bit depending on the data (they seem to have different templates for very positive, positive, neutral and negative change). To be clear, I could program something like this given a good finance api and a spare week/month, and in fact did so a couple of years ago for an automatic poetry generator, *but I didn't notice because I wasn't paying attention*.
|
||||||
|
- [Wimbledon organisers set to net £100 million insurance payout after taking out infectious diseases cover following 2003 SARS outbreak, with tournament now cancelled because of coronavirus](https://www.dailymail.co.uk/sport/tennis/article-8183419/amp/Wimbledon-set-net-huge-100m-insurance-payout-tournament-cancelled.html). Cheers to Wimbledon.
|
||||||
|
- [The Post ranks the top 10 faces in New York sports today](https://nypost.com/2020/05/02/the-post-ranks-the-top-10-faces-in-new-york-sports-today/), accompanied by [Pitfall to forecasting top 10 faces of New York sports right now](https://nypost.com/2020/05/03/pitfall-to-forecasting-top-10-faces-of-new-york-sports-right-now/). Comparison with the historical situation: Check. Considering alternative hypothesis: Check. Communicating uncertainty to the reader in an effective manner: Check. Putting your predictions out to be judged: Check.
|
||||||
|
- [In Forecasting Hurricane Dorian, Models Fell Short](https://www.scpr.org/news/2020/04/30/92263/in-forecasting-hurricane-dorian-models-fell-short/) (and see [here](https://www.nhc.noaa.gov/data/tcr/AL052019_Dorian.pdf) for the National Hurricane Center report). "Hurricane forecasters and the models they depend on failed to anticipate the strength and impact of last year's deadliest storm." On the topic of weather, see also [Nowcasting the weather in Africa](https://phys.org/news/2020-05-storm-chasers-life-saving.html) to reduce fatalities, and [Misunderstanding Of Coronavirus Predictions Is Eerily Similar To Weather Forecasting](https://www.forbes.com/sites/marshallshepherd/2020/05/22/misunderstanding-of-coronavirus-predictions-is-eerily-similar-to-weather-forecasting/#2f1288467f75), Forbes speculates.
|
||||||
|
- [Pan-African Heatwave Health Hazard Forecasting](http://www.walker.ac.uk/research/projects/pan-african-heatwave-health-hazard-forecasting/). "The main aim, is to raise the profile of heatwaves as a hazard on a global scale. Hopefully, the project will add evidence to this sparse research area. It could also provide the basis for a heat early warning system." The project looks to be in its early stages, yet nonetheless interesting.
|
||||||
|
- [Nounós Creamery uses demand-forecasting platform to improve production process](https://www.dairyfoods.com/articles/94319-noun%C3%B3s-creamery-uses-demand-forecasting-platform-to-improve-production-process). The piece is shameless advertising, but it's still an example of predictive models used out in the wild in industry.
|
||||||
|
|
||||||
|
## Grab Bag
|
||||||
|
Podcasts, blogposts, papers, tweets and other recent nontraditional media.
|
||||||
|
|
||||||
|
- Some interesting discussion about forecasting over at Twitter, in [David Manheim](https://twitter.com/davidmanheim)'s and [Philip Tetlock](https://twitter.com/PTetlock)'s accounts, some of which have been incorporated into this newsletter. [This twitter thread](https://twitter.com/lukeprog/status/1262492767869009920) contains some discussion about how Good Judgement Open, Metaculus and expert forecasters fare against each other, but note the caveats by @LinchZhang: "For Survey 10, Metaculus said that question resolution was on 4pm ET Sunday, a lot of predictors (correctly) gauged that the data update on Sunday will be delayed and answered the letter rather than the spirit of the question (Metaculus ended up resolving it ambiguous)." [This thread](https://twitter.com/mlipsitch/status/1257857079756365824) by Marc Lipsitch has become popular, and I personally also enjoyed [these](https://twitter.com/LinchZhang/status/1262127601176334336) [two](https://twitter.com/LinchZhang/status/1261427045977874432) twitter threads by Linchuan Zhang, on forecasting mistakes.
|
||||||
|
- [SlateStarCodex](https://slatestarcodex.com/2020/04/29/predictions-for-2020/) brings us a hundred more predictions for 2020. Some analysis by Zvi Mowshowitz [here](https://www.lesswrong.com/posts/gSdZjyFSky3d34ySh/slatestarcodex-2020-predictions-buy-sell-hold) and by user [Bucky](https://www.lesswrong.com/posts/orSNNCm77LiSEBovx/2020-predictions).
|
||||||
|
- [FLI Podcast: On Superforecasting with Robert de Neufville](https://futureoflife.org/2020/04/30/on-superforecasting-with-robert-de-neufville/). I would have liked to see a more intense drilling on some of the points. It references [The NonProphets Podcast](https://nonprophetspod.wordpress.com/), which looks like it has some more in-depth stuff. Some quotes:
|
||||||
|
> So it’s not clear to me that our forecasts are necessarily affecting policy. Although it’s the kind of thing that gets written up in the news and who knows how much that affects people’s opinions, or they talk about it at Davos and maybe those people go back and they change what they’re doing.
|
||||||
|
|
||||||
|
> I wish it were used better. If I were the advisor to a president, I would say you should create a predictive intelligence unit using superforecasters. Maybe give them access to some classified information, but even using open source information, have them predict probabilities of certain kinds of things and then develop a system for using that in your decision making. But I think we’re a fair ways away from that. I don’t know any interest in that in the current administration.
|
||||||
|
|
||||||
|
> Now one thing I think is interesting is that often people, they’re not interested in my saying, “There’s a 78% chance of something happening.” What they want to know is, how did I get there? What is my arguments? That’s not unreasonable. I really like thinking in terms of probabilities, but I think it often helps people understand what the mechanism is because it tells them something about the world that might help them make a decision. So I think one thing that maybe can be done is not to treat it as a black box probability, but to have some kind of algorithmic transparency about our thinking because that actually helps people, might be more useful in terms of making decisions than just a number.
|
||||||
|
- [Space Weather Challenge and Forecasting Implications of Rossby Waves](https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2018SW002109). Recent advances may help predict solar flares better. I don't know how bad the worst solar flare could be, and how much a two year warning could buy us, but I tend to view developments like this very positively.
|
||||||
|
- [An analogy-based method for strong convection forecasts in China using GFS forecast data](https://www.tandfonline.com/doi/full/10.1080/16742834.2020.1717329). "Times in the past when the forecast parameters are most similar to those forecast at the current time are identified by searching a large historical numerical dataset", and this is used to better predict one particular class of meteorological phenomena. See [here](https://www.eurekalert.org/pub_releases/2020-05/ioap-ata051520.php) for a press release.
|
||||||
|
- The Cato Institute releases [12 New Immigration Ideas for the 21st Century](https://www.cato.org/publications/white-paper/12-new-immigration-ideas-21st-century), including two from Robin Hanson: Choosing Immigrants through Prediction Markets & Transferable Citizenship. The first idea is to have prediction markets forecast the monetary value of taking in immigrants, and decide accordingly, then rewarding forecasters according to their accuracy in predicting e.g. how much said immigrants pay in taxes.
|
||||||
|
- [A General Approach for Predicting the Behavior of the Supreme Court of the United States](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2463244). What seems to be a pretty simple algorithm (a random forest!) seems to do pretty well (70% accuracy). Their feature set is rich but doesn't seem to include ideology. It was written in 2017; today, I'd expect that a random bright highschooler might be able to do much beter.
|
||||||
|
- [From Self-Prediction to Self-Defeat: Behavioral Forecasting, Self-Fulfilling Prophecies, and the Effect of Competitive Expectations](https://pubmed.ncbi.nlm.nih.gov/14561121/). Abstract: Four studies explored behavioral forecasting and the effect of competitive expectations in the context of negotiations. Study 1 examined negotiators' forecasts of how they would behave when faced with a very competitive versus a less competitive opponent and found that negotiators believed they would become more competitive. Studies 2 and 3 examined actual behaviors during negotiation and found that negotiators who expected a very competitive opponent actually became less competitive, as evidenced by setting lower, less aggressive reservation prices, making less demanding counteroffers, and ultimately agreeing to lower negotiated outcomes. Finally, Study 4 provided a direct test of the disconnection between negotiators' forecasts for their behavior and their actual behaviors within the same sample and found systematic errors in behavioral forecasting as well as evidence for the self-fulfilling effects of possessing a competitive expectation.
|
||||||
|
- [Neuroimaging results altered by varying analysis pipelines](https://www.nature.com/articles/d41586-020-01282-z). Relevant paragraph: "the authors ran separate ‘prediction markets’, one for the analysis teams and one for researchers who did not participate in the analysis. In them, researchers attempted to predict the outcomes of the scientific analyses and received monetary payouts on the basis of how well they predicted performance. Participants — even researchers who had direct knowledge of the data set — consistently overestimated the likelihood of significant findings". Those who had more knowledge did slightly better, however.
|
||||||
|
- [Forecasting s-curves is hard](https://constancecrozier.com/2020/04/16/forecasting-s-curves-is-hard/): Some clear visualizations of what it says on the title.
|
||||||
|
- [Forecasting state expenses for budget is always a best guess](https://www.mercurynews.com/2020/05/20/letter-forecasting-state-expenses-for-budget-is-always-a-best-guess/); exactly what it says on the tin. Problem could be solved with a prediction market or forecasting tournament.
|
||||||
|
- [Fashion Trend Forecasting](https://arxiv.org/pdf/2005.03297.pdf) using Instagram and baking preexisting knowledge into NNs.
|
||||||
|
- [The advantages and limitations of forecasting](https://rwer.wordpress.com/2020/05/12/the-advantages-and-limitations-of-forecasting/). A short and sweet blog post, with a couple of forecasting anecdotes and zingers.
|
||||||
|
|
||||||
|
## Negative examples.
|
||||||
|
I have found negative examples to be useful as a mirror with which to reflect on my own mistakes; highlighting them may also be useful for shaping social norms. [Andrew Gelman](https://statmodeling.stat.columbia.edu/) continues to fast-pacedly produce blogposts on this topic. Meanwhile, amongst mortals:
|
||||||
|
|
||||||
|
- [Kelsey Piper of Vox harshly criticizes the IHME model](https://www.vox.com/future-perfect/2020/5/2/21241261/coronavirus-modeling-us-deaths-ihme-pandemic). "Some of the factors that make the IHME model unreliable at predicting the virus may have gotten people to pay attention to it;" or "Other researchers found the true deaths were outside of the 95 percent confidence interval given by the model 70 percent of the time."
|
||||||
|
- The [Washington post](https://www.washingtonpost.com/outlook/2020/05/19/lets-check-donald-trumps-chances-getting-reelected/) offers a highly partisan view of Trump's chances of winning the election. The author, having already made a past prediction, and seeing as how other media outlets offer a conflicting perspective, rejects the information he's learnt, and instead can only come up with more reasons which confirm his initial position. Problem could be solved with a prediction market or forecasting tournament.
|
||||||
|
- [California politics pretends to be about recession forecasts](https://calmatters.org/economy/2020/05/newsom-economic-forecast-criticism-california-model-recession-budget/). See also: [Simulacra levels](https://www.lesswrong.com/posts/fEX7G2N7CtmZQ3eB5/simulacra-and-subjectivity?commentId=FgajiMrSpY9MxTS8b); the article is at least three levels removed from consideration about bare reality. Key quote, about a given forecasting model: "It’s just preposterously negative... How can you say that out loud without giggling?" See also some more prediction ping-pong, this time in New Jersey, [here](https://www.njspotlight.com/2020/05/fiscal-experts-project-nj-revenue-losses-wont-be-as-bad-as-murphys-team-forecast/). Problem could be solved with a prediction market or forecasting tournament.
|
||||||
|
- [What Is the Stock Market Even for Anymore?](https://www.nytimes.com/interactive/2020/05/26/magazine/stock-market-coronavirus-pandemic.html). A New York Times claims to have predicted that the market was going to fall (but can't prove it with, for example, a tweet, or a hash of a tweet), and nonetheless lost significant amounts of his own funds. ("The market dropped another 1,338 points the next day, and though my funds were tanking along with almost everyone else’s, I found some empty satisfaction, at least, in my prognosticating.") The rest of the article is about said reported being personally affronted with the market not falling further ("the stock market’s shocking resilience (at least so far) has looked an awful lot like indifference to the Covid-19 crisis and the economic calamity it has brought about. The optics, as they say, are terrible.")
|
||||||
|
- [Forecasting drug utilization and expenditure: ten years of experience in Stockholm](https://bmchealthservres.biomedcentral.com/articles/10.1186/s12913-020-05170-0). A normally pretty good forecasting model had the bad luck of not foreseeing a Black Swan, and sending a study to a journal just before a pandemic, so that it's being published now. They write: "According to the forecasts, the total pharmaceutical expenditure was estimated to increase between 2 and 8% annually. Our analyses showed that the accuracy of these forecasts varied over the years with a mean absolute error of 1.9 percentage points." They further conclude: "Based on the analyses of all forecasting reports produced since the model was established in Stockholm in the late 2000s, we demonstrated that it is feasible to forecast pharmaceutical expenditure with a reasonable accuracy." Presumably, this has increased further because of covid, sending the mean absolute error through the roof. If the author of this paper bites you, you become a Nassim Taleb.
|
||||||
|
- Some films are so bad it's funny. [This article fills the same niche](https://www.moneyweb.co.za/investing/yes-it-is-possible-to-predict-the-market/) for forecasting. It has it all: Pythagorean laws of vibration, epicycles, an old and legendary master with mystical abilities, 90 year predictions which come true. Further, from the [Wikipedia entry](https://en.wikipedia.org/wiki/William_Delbert_Gann#Controversy): "He told me that his famous father could not support his family by trading but earned his living by writing and selling instructional courses."
|
||||||
|
- [Austin Health Official Recommends Cancelling All 2020 Large Events, Despite Unclear Forecasting](https://texasscorecard.com/local/austin-health-official-recommends-cancelling-all-2020-large-events-despite-unclear-forecasting/). Texan article does not consider the perspective that one might want to cancel large events precisely *because* of the forecasting uncertainty.
|
||||||
|
- [Auditor urges more oversight, better forecasting at the United State's Department of Transport](https://www.wral.com/coronavirus/auditor-urges-more-oversight-better-forecasting-at-dot/19106691/): "Instead of basing its spending plan on project-specific cost estimates, Wood said, the agency uses prior-year spending. That forecasting method doesn't account for cost increases or for years when there are more projects in the works." The budget of the organization is $5.9 billion. Problem could be solved with a prediction market or forecasting tournament.
|
||||||
|
|
||||||
|
## Long content
|
||||||
|
This section contains items which have recently come to my attention, but which I think might still be relevant not just this month, but throughout the years. Content in this section may not have been published in the last month.
|
||||||
|
|
||||||
|
- [How to evaluate 50% predictions](https://www.lesswrong.com/posts/DAc4iuy4D3EiNBt9B/how-to-evaluate-50-predictions). "I commonly hear (sometimes from very smart people) that 50% predictions are meaningless. I think that this is wrong."
|
||||||
|
- [Named Distributions as Artifacts](https://blog.cerebralab.com/Named%20Distributions%20as%20Artifacts). On how the named distributions we use (the normal distribution, etc.), were selected for being easy to use in pre-computer eras, rather than on being a good ur-prior on distributions for phenomena in this universe.
|
||||||
|
- [The fallacy of placing confidence in confidence intervals](https://link.springer.com/article/10.3758/s13423-015-0947-8). On how the folk interpretation of confidence intervals can be misguided, as it conflates: a. the long-run probability, before seeing some data, that a procedure will produce an interval which contains the true value, and b. and the probability that a particular interval contains the true value, after seeing the data. This is in contrast to Bayesian theory, which can use the information in the data to determine what is reasonable to believe, in light of the model assumptions and prior information. I found their example where different confidence procedures produce 50% confidence intervals which are nested inside each other particularly funny. Some quotes:
|
||||||
|
> Using the theory of confidence intervals and the support of two examples, we have shown that CIs do not have the properties that are often claimed on their behalf. Confidence interval theory was developed to solve a very constrained problem: how can one construct a procedure that produces intervals containing the true parameter a fixed proportion of the time? Claims that confidence intervals yield an index of precision, that the values within them are plausible, and that the confidence coefficient can be read as a measure of certainty that the interval contains the true value, are all fallacies and unjustified by confidence interval theory.
|
||||||
|
|
||||||
|
> “I am not at all sure that the ‘confidence’ is not a ‘confidence trick.’ Does it really lead us towards what we need – the chance that in the universe which we are sampling the parameter is within these certain limits? I think it does not. I think we are in the position of knowing that either an improbable event has occurred or the parameter in the population is within the limits. To balance these things we must make an estimate and form a judgment as to the likelihood of the parameter in the universe that is, a prior probability – the very thing that is supposed to be eliminated.”
|
||||||
|
|
||||||
|
> The existence of multiple, contradictory long-run probabilities brings back into focus the confusion between what we know before the experiment with what we know after the experiment. For any of these confidence procedures, we know before the experiment that 50 % of future CIs will contain the true value. After observing the results, conditioning on a known property of the data — such as, in this case, the variance of the bubbles — can radically alter our assessment of the probability.
|
||||||
|
|
||||||
|
> “You keep using that word. I do not think it means what you think it means.” Íñigo Montoya, The Princess Bride (1987)
|
||||||
|
- [Psychology of Intelligence Analysis](https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/books-and-monographs/psychology-of-intelligence-analysis/), courtesy of the American Central Intelligence Agency, seemed interesting, and I read chapters 4, 5 and 14. Sometimes forecasting looks like reinventing intelligence analysis; from that perspective, I've found this reference work useful. Thanks to EA Discord user @Willow for bringing this work to my attention.
|
||||||
|
- Chapter 4: Strategies for Analytical Judgement. Discusses and compares the strengths and weaknesses of four tactics: situational analysis (inside view), applying theory, comparison with historical situations, and immersing oneself on the data. It then brings up several suboptimal tactics for choosing among hypotheses.
|
||||||
|
- Chapter 5: When does one need more information, and in what shapes does new information come from?
|
||||||
|
> Once an experienced analyst has the minimum information necessary to make an informed judgment, obtaining additional information generally does not improve the accuracy of his or her estimates. Additional information does, however, lead the analyst to become more confident in the judgment, to the point of overconfidence.
|
||||||
|
|
||||||
|
> Experienced analysts have an imperfect understanding of what information they actually use in making judgments. They are unaware of the extent to which their judgments are determined by a few dominant factors, rather than by the systematic integration of all available information. Analysts actually use much less of the available information than they think they do.
|
||||||
|
|
||||||
|
> There is strong experimental evidence, however, that such self-insight is usually faulty. The expert perceives his or her own judgmental process, including the number of different kinds of information taken into account, as being considerably more complex than is in fact the case. Experts overestimate the importance of factors that have only a minor impact on their judgment and underestimate the extent to which their decisions are based on a few major variables. In short, people's mental models are simpler than they think, and the analyst is typically unaware not only of which variables should have the greatest influence, but also which variables actually are having the greatest influence.
|
||||||
|
|
||||||
|
- Chapter 14: A Checklist for Analysts. "Traditionally, analysts at all levels devote little attention to improving how they think. To penetrate the heart and soul of the problem of improving analysis, it is necessary to better understand, influence, and guide the mental processes of analysts themselves." The Chapter also contains an Intelligence Analysis reading list.
|
||||||
|
- [The Limits of Prediction: An Analyst’s Reflections on Forecasting](https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/csi-studies/studies/vol-63-no-4/Limits-of-Prediction.html), also courtesy of the American Central Intelligence Agency. On how intelligence analysts should inform their users of what they are and aren't capable of. It has some interesting tidbits and references on predicting discontinuities. It also suggests some guiding questions that the analyst may try to answer for the policymaker.
|
||||||
|
- What is the context and reality of the problem I am facing?
|
||||||
|
- How does including information on new developments affect my problem/issue?
|
||||||
|
- What are the ways this situation could play out?
|
||||||
|
- How do we get from here to there? and/or What should I be looking out for?
|
||||||
|
|
||||||
|
> "We do not claim our assessments are infallible. Instead, we assert that we offer our most deeply and objectively based and carefully considered estimates."
|
||||||
|
- [How to Measure Anything](https://www.lesswrong.com/posts/ybYBCK9D7MZCcdArB/how-to-measure-anything), a review. "Anything can be measured. If a thing can be observed in any way at all, it lends itself to some type of measurement method. No matter how “fuzzy” the measurement is, it’s still a measurement if it tells you more than you knew before. And those very things most likely to be seen as immeasurable are, virtually always, solved by relatively simple measurement methods."
|
||||||
|
- The World Meteorological organization, on their mandate to guarantee that [no one is surprised by a flood](https://public.wmo.int/en/our-mandate/water/no-one-is-surprised-by-a-flood). Browsing the webpage it seems that the organization is either a Key Organization Safeguarding the Vital Interests of the World or Just Another of the Many Bureaucracies Already in Existence, but it's unclear to me how to differentiate between the two. One clue may be their recent [Caribbean workshop on impact-based forecasting and risk scenario planning](https://public.wmo.int/en/media/news/caribbean-workshop-impact-based-forecasting-and-risk-scenario-planning), with the narratively unexpected and therefore salient presence of Gender Bureaus.
|
||||||
|
- [95%-ile isn't that good](https://danluu.com/p95-skill/): "Reaching 95%-ile isn't very impressive because it's not that hard to do."
|
||||||
|
- [The Backwards Arrow of Time of the Coherently Bayesian Statistical Mechanic](https://arxiv.org/abs/cond-mat/0410063): Identifying thermodynamic entropy with the Bayesian uncertainty of an ideal observer leads to problems, because as the observer observes more about the system, they update on this information, which in expectation reduces uncertainty, and thus entropy. But entropy increases with time.
|
||||||
|
- This might be interesting to students in the tradition of E.T. Jaynes: for example, the paper directly conflicts with this LessWrong post: [The Second Law of Thermodynamics, and Engines of Cognition](https://www.lesswrong.com/posts/QkX2bAkwG2EpGvNug/the-second-law-of-thermodynamics-and-engines-of-cognition), part of *Rationality, From AI to Zombies*. The way out might be to postulate that actually, the Bayesian updating process itself would increase entropy, in the form of e.g., the work needed to update bits on a computer. Any applications to Christian lore are left as an exercise for the reader. Otherwise, seeing two bright people being cogently convinced of different perspectives does something funny to my probabilities: it pushes them towards 50%, but also increases the expected time I'd have to spend on the topic to move them away from 50%.
|
||||||
|
- [Behavioral Problems of Adhering to a Decision Policy](https://pdfs.semanticscholar.org/7a79/28d5f133e4a274dcaec4d0a207daecde8068.pdf)
|
||||||
|
> Our judges in this study were eight individuals, carefully selected for their expertise as
|
||||||
|
handicappers. Each judge was presented with a list of 88 variables culled from the past performance charts. He was asked to indicate which five variables out of the 88 he would wish to use when handicapping a race, if all he could have was five variables. He was then asked to indicate which 10, which 20, and which 40 he would use if 10, 20, or 40 were available to him.
|
||||||
|
|
||||||
|
> We see that accuracy was as good with five variables as it was with 10, 20, or 40. The flat curve is an average over eight subjects and is somewhat misleading. Three of the eight actually showed a decrease in accuracy with more information, two improved, and three stayed about the same. All of the handicappers became more confident in their judgments as information increased.
|
||||||
|
|
||||||
|
|
||||||
|
- The study contains other nuggets, such as:
|
||||||
|
- An experiment on trying to predict the outcome of a given equation. When the feedback has a margin of error, this confuses respondents.
|
||||||
|
- "However, the results indicated that subjects often chose one gamble, yet stated a higher selling price for the other gamble"
|
||||||
|
- "We figured that a comparison between two students along the same dimension should be easier, cognitively, than a 13 comparison between different dimensions, and this ease of use should lead to greater reliance on the common dimension. The data strongly confirmed this hypothesis. Dimensions were weighted more heavily when common than when they were unique attributes. Interrogation of the subjects after the experiment indicated that most did not wish to change their policies by giving more weight to common dimensions and they were unaware that they had done so."
|
||||||
|
- "The message in these experiments is that the amalgamation of different types of information and different types of values into an overall judgment is a difficult cognitive process. In our attempts to ease the strain of processing information, we often resort to judgmental strategies that do an injustice to the underlying values and policies that we’re trying to implement."
|
||||||
|
- "A major problem that a decision maker faces in his attempt to be faithful to his policy is the fact that his insight into his own behavior may be inaccurate. He may not be aware of the fact that he is employing a different policy than he thinks he’s using. This problem is illustrated by a study that Dan Fleissner, Scott Bauman, and I did, in which 13 stockbrokers and five graduate students served as subjects. Each subject evaluated the potential capital appreciation of 64 securities. [...] A mathematical model was then constructed to predict each subject's judgments. One output from the model was an index of the relative importance of each of the eight information items in determining each subject’s judgments [...] Examination of Table 4 shows that the broker’s perceived weights did not relate closely to the weights derived from their actual judgments.
|
||||||
|
- I informally replicated this.
|
||||||
|
- As remedies they suggest to create a model by eliciting the expert, either by having the expert make a large number of judgments and distilling a model, or by asking the expert what they think the most important factors are. A third alternative suggested is computer assistance, so that the experiment participants become aware of which factors influence their judgment.
|
||||||
|
- [Immanuel Kant, on Betting](https://www.econlib.org/archives/2014/07/kant_on_betting.html)
|
||||||
|
|
||||||
|
Vale.
|
||||||
|
|
||||||
|
Conflicts of interest: Marked as (c.o.i) throughout the text.
|
||||||
|
Note to the future: All links are automatically added to the Internet Archive. In case of link rot, go [there](https://archive.org/).
|
||||||
224
ea/ForecastingNewsletter/May2020_raw.md
Normal file
|
|
@ -0,0 +1,224 @@
|
||||||
|
Whatever happened to forecasting? May 2020 \[Draft\]
|
||||||
|
====================================================
|
||||||
|
|
||||||
|
A forecasting digest with a focus on experimental forecasting. You can sign up [here](https://mailchi.mp/18fccca46f83/forecastingnewsletter). The newsletter itself is experimental, but there will be at least five more iterations.
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Prediction Markets & Forecasting platforms.
|
||||||
|
- Augur.
|
||||||
|
- PredictIt & Election Betting Odds.
|
||||||
|
- Replication Markets.
|
||||||
|
- Coronavirus Information Markets.
|
||||||
|
- Foretold. (c.o.i).
|
||||||
|
- Metaculus.
|
||||||
|
- Good Judgement Open.
|
||||||
|
- In the News.
|
||||||
|
- Grab bag.
|
||||||
|
- Long Content.
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting platforms.
|
||||||
|
|
||||||
|
### Augur: [augur.net](https://www.augur.net/)
|
||||||
|
|
||||||
|
Augur is a decentralized prediction market. [Here](https://bravenewcoin.com/insights/augur-price-analysis-token-success-hinges-on-v2-release-in-june) is a fine piece of reporting outlining how it operates and the road ahead.
|
||||||
|
|
||||||
|
### Predict It & Election Betting Odds: [predictIt.org](https://www.predictit.org/) & [electionBettingOdds.com](http://electionbettingodds.com/)
|
||||||
|
|
||||||
|
PredictIt is a prediction platform restricted to US citizens or those who bother using a VPN. This month, they have a badass map about the election college result in the USA. States are colored according to the market prices:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Some of the predictions I found most interesting follow. The market probabilities can be found below; the engaged reader might want to annotate their probabilities and then compare.
|
||||||
|
- [Will Benjamin Netanyahu be prime minister of Israel on Dec. 31, 2020?](https://www.predictit.org/markets/detail/6238/Will-Benjamin-Netanyahu-be-prime-minister-of-Israel-on-Dec-31,-2020)
|
||||||
|
- [Will Trump meet with Kim Jong-Un in 2020?](https://www.predictit.org/markets/detail/6265/Will-Trump-meet-with-Kim-Jong-Un-in-2020)
|
||||||
|
- [Will Nicolás Maduro be president of Venezuela on Dec. 31, 2020?](https://www.predictit.org/markets/detail/6237/Will-Nicol%C3%A1s-Maduro-be-president-of-Venezuela-on-Dec-31,-2020)
|
||||||
|
- [Will Kim Jong-Un be Supreme Leader of North Korea on Dec. 31?](https://www.predictit.org/markets/detail/6674/Will-Kim-Jong-Un-be-Supreme-Leader-of-North-Korea-on-Dec-31)
|
||||||
|
- [Will a federal charge against Barack Obama be confirmed before November 3?](https://www.predictit.org/markets/detail/6702/Will-a-federal-charge-against-Barack-Obama-be-confirmed-before-November-3)
|
||||||
|
|
||||||
|
Some of the interesting and wrong ones are:
|
||||||
|
- [Will Trump switch parties by Election Day 2020?](https://www.predictit.org/markets/detail/3731/Will-Trump-switch-parties-by-Election-Day-2020)
|
||||||
|
- [Will Michelle Obama run for president in 2020?](https://www.predictit.org/markets/detail/4632/Will-Michelle-Obama-run-for-president-in-2020)
|
||||||
|
- [Will Hillary Clinton run for president in 2020?](https://www.predictit.org/markets/detail/4614/Will-Hillary-Clinton-run-for-president-in-2020)
|
||||||
|
|
||||||
|
Market odds are: 80%, 15%, 69%, 79%, 8%, 2%, 7%, 11%.
|
||||||
|
|
||||||
|
Further, the following two markets are plain inconsistent:
|
||||||
|
- [Will the 2020 Democratic nominee for president be a woman?](https://www.predictit.org/markets/detail/2902/Will-the-2020-Democratic-nominee-for-president-be-a-woman): 11%
|
||||||
|
- [Who will win the 2020 Democratic presidential nomination?](https://www.predictit.org/markets/detail/3633/Who-will-win-the-2020-Democratic-presidential-nomination). Biden, Cuomo and Sanders sum up to 95%.
|
||||||
|
|
||||||
|
[Election Betting Odds](https://electionbettingodds.com/) aggregates PredictIt with other such services for the US presidential elections. The creators of the webpage used its visibility to promote [ftx.com](https://ftx.com/), another platform in the area. They also have an election map.
|
||||||
|
|
||||||
|
### Replication Markets: [replicationmarkets.com](https://www.replicationmarkets.com)
|
||||||
|
Replication Markets is a project where volunteer forecasters try to predict whether a given study's results will be replicated with high power. Rewards are monetary, but only given out to the top N forecasters, and markets suffer from sometimes being dull.
|
||||||
|
|
||||||
|
The first week of each round is a survey round, which has some aspects of a Keynesian beauty contest, because it's the results of the second round, not the ground truth, what is being forecasted. This second round then tries to predict what would happen if the studies were in fact subject to a replication, which a select number of studies then undergo.
|
||||||
|
|
||||||
|
There is a part of me which dislikes this setup: here was I, during the first round, forecasting to the best of my ability, when I realize that in some cases, I'm going to improve the aggregate and be punished for this, particularly when I have information which I expect other market participants to not have.
|
||||||
|
|
||||||
|
At first I thought that, cunningly, the results of the first round are used as priors for the second round, but a programming mistake by the organizers revealed that they use a simple algorithm: claims with p < .001 start with a prior of 80%, p < .01 starts at 40%, and p < .05 starts at 30%.
|
||||||
|
|
||||||
|
### Coronavirus Information Markets: [coronainformationmarkets.com](https://coronainformationmarkets.com/)
|
||||||
|
For those who want to put their money where their mouth is, a prediction market for coronavirus related information popped out.
|
||||||
|
|
||||||
|
Making forecasts is tricky, so would-be-bettors might be better off pooling their forecasts. As of the middle of this month, the total trading volume sits at a $20k (from 8k last month), and some questions have been resolved already.
|
||||||
|
|
||||||
|
### Foretold: [foretold.io](https://www.foretold.io/) & EpidemicForecasting (c.o.i)
|
||||||
|
|
||||||
|
Foretold has continued their partnership with Epidemic Forecasting, gathering a team of superforecasters to advise governments around the world which wouldn't otherwise have the capacity. They further shipped a report to a vaccine company analyzing the suitability of different locations for human trials, aggregating more than 1000 individual forecasts.
|
||||||
|
|
||||||
|
### Metaculus: [metaculus.com](https://www.metaculus.com/)
|
||||||
|
|
||||||
|
Metaculus is a forecasting platform with an active community and lots of interesting questions. In their May pandemic newsletter, they emphasized having "all the benefits of a betting market but without the actual betting", which I found pretty funny.
|
||||||
|
|
||||||
|
Yet consider that if monetary prediction markets were more convenient to use, and less dragged down by regulatory hurdles in the US, they could have been scaled up much more quickly during the pandemic.
|
||||||
|
|
||||||
|
Instead, the job fell to Metaculus; this month they've organized a flurry of activities, most notably:
|
||||||
|
- [The Salk Tournament](https://pandemic.metaculus.com/questions/4093/the-salk-tournament-for-coronavirus-sars-cov-2-vaccine-rd/) on vaccine development
|
||||||
|
- [The El Paso Series](https://pandemic.metaculus.com/questions/4161/el-paso-series-supporting-covid-19-response-planning-in-a-mid-sized-city/) on collaboratively predicting peaks.
|
||||||
|
- [The Lightning Round Tournament](https://pandemic.metaculus.com/questions/4166/the-lightning-round-tournament-comparing-metaculus-forecasters-to-infectious-disease-experts/), in which metaculus forecasters go head to head against expert epidemiologists.
|
||||||
|
- They also present a [Covid dashboard](https://pandemic.metaculus.com/COVID-19/).
|
||||||
|
|
||||||
|
On the negative side, they haven't fixed the way users input their distribution, restricting it to stacking up to 5 gaussians on top of each other, which limits expressiveness.
|
||||||
|
|
||||||
|
### /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
|
||||||
|
|
||||||
|
The title of this section is a [regular expression](https://en.wikipedia.org/wiki/Regular_expression), so as to be maximally unambiguous.
|
||||||
|
|
||||||
|
Good Judgement Inc. is the organization which grew out of Tetlock's research on forecasting, and out of the Good Judgement Project, which won the [IARPA ACE forecasting competition](https://en.wikipedia.org/wiki/Aggregative_Contingent_Estimation_(ACE)_Program), and resulted in the research covered in the *Superforecasting* book.
|
||||||
|
|
||||||
|
Good Judgement Inc. also organizes the Good Judgement Open [gjopen.com](https://www.gjopen.com/), a forecasting platform open to all, with a focus on serious geopolitical questions. They structure their questions in challenges. Of the currently active questions, here is a selection of those I found interesting (odds below):
|
||||||
|
- [Before 1 January 2021, will the People's Liberation Army (PLA) and/or People’s Armed Police (PAP) be mobilized in Hong Kong?](https://www.gjopen.com/questions/1499-before-1-january-2021-will-the-people-s-liberation-army-pla-and-or-people-s-armed-police-pap-be-mobilized-in-hong-kong)
|
||||||
|
- [Will the winner of the popular vote in the 2020 United States presidential election also win the electoral college?](https://www.gjopen.com/questions/1495-will-the-winner-of-the-popular-vote-in-the-2020-united-states-presidential-election-also-win-the-electoral-college)- This one is interesting, because it has infrequently gone the other way historically, but 2/5 of the last USA elections were split.
|
||||||
|
- [Will Benjamin Netanyahu cease to be the prime minister of Israel before 1 January 2021?](https://www.gjopen.com/questions/1498-will-benjamin-netanyahu-cease-to-be-the-prime-minister-of-israel-before-1-january-2021). Just when I thought he was out, he pulls himself back in.
|
||||||
|
- [Before 28 July 2020, will Saudi Arabia announce the cancellation or suspension of the Hajj pilgrimage, scheduled for 28 July 2020 to 2 August 2020?](https://www.gjopen.com/questions/1621-before-28-july-2020-will-saudi-arabia-announce-the-cancellation-or-suspension-of-the-hajj-pilgrimage-scheduled-for-28-july-2020-to-2-august-2020)
|
||||||
|
- [Will formal negotiations between Russia and the United States on an extension, modification, or replacement for the New START treaty begin before 1 October 2020?](https://www.gjopen.com/questions/1551-will-formal-negotiations-between-russia-and-the-united-states-on-an-extension-modification-or-replacement-for-the-new-start-treaty-begin-before-1-october-2020)s
|
||||||
|
|
||||||
|
Odds: 20%, 75%, 44%, 86%, 19%
|
||||||
|
|
||||||
|
On the Good Judgement Inc. side, [here](https://goodjudgment.com/covidrecovery/) is a dashboard presenting forecasts related to covid. The ones I found most worthy are:
|
||||||
|
- [When will the FDA approve a drug or biological product for the treatment of COVID-19?](https://goodjudgment.io/covid-recovery/#1384)
|
||||||
|
- [Will the US economy bounce back by Q2 2021?](https://goodjudgment.io/covid-recovery/#1373)
|
||||||
|
- [What will be the U.S. civilian unemployment rate (U3) for June 2021?](https://goodjudgment.io/covid-recovery/#1374)
|
||||||
|
- [When will enough doses of FDA-approved COVID-19 vaccine(s) to inoculate 25 million people be distributed in the United States?](https://goodjudgment.io/covid-recovery/#1363)
|
||||||
|
|
||||||
|
Otherwise, for a recent interview with Tetlock, see [this podcast](https://medium.com/conversations-with-tyler/philip-tetlock-tyler-cowen-forecasting-sociology-30401464b6d9), by Tyler Cowen.
|
||||||
|
|
||||||
|
## CSET: Foretell
|
||||||
|
|
||||||
|
The Center for Security and Emerging Technology is looking for (unpaid, volunteer) forecasters to predict the future to better inform policy decisions. The idea would be that as emerging technologies pose diverse challenges, forecasters and forecasting methodologies with a good track record might be a valuable source of insight and advice to policymakers.
|
||||||
|
|
||||||
|
One can sign-up on [their webpage](https://www.cset-foretell.com/), which, although sparse, contains some more information. CSET was previously funded by the [Open Philantropy Project](https://www.openphilanthropy.org/giving/grants/georgetown-university-center-security-and-emerging-technology); the grant writeup contains some more information.
|
||||||
|
|
||||||
|
## In The News.
|
||||||
|
- [In Forecasting Hurricane Dorian, Models Fell Short](https://www.scpr.org/news/2020/04/30/92263/in-forecasting-hurricane-dorian-models-fell-short/) (and see [here](https://www.nhc.noaa.gov/data/tcr/AL052019_Dorian.pdf) for the National Hurricane Center report). "Hurricane forecasters and the models they depend on failed to anticipate the strength and impact of last year's deadliest storm."
|
||||||
|
- [The Post ranks the top 10 faces in New York sports today](https://nypost.com/2020/05/02/the-post-ranks-the-top-10-faces-in-new-york-sports-today/), accompanied by [Pitfall to forecasting top 10 faces of New York sports right now](https://nypost.com/2020/05/03/pitfall-to-forecasting-top-10-faces-of-new-york-sports-right-now/). Comparison with the historical situation: Check. Considering alternative hypothesis: Check. Communicating uncertainty to the reader in an effective manner: Check. Putting your predictions out to be judged: Check.
|
||||||
|
- Kings College produces a new [forecasting tool for central banks](https://www.kcl.ac.uk/news/new-covid-19-relating-forecasting-tool-central-banks-2)
|
||||||
|
- [Nounós Creamery uses demand-forecasting platform to improve production process](https://www.dairyfoods.com/articles/94319-noun%C3%B3s-creamery-uses-demand-forecasting-platform-to-improve-production-process). The piece is shameless advertising, but it's still an example of predictive models used out in the wild in industry.
|
||||||
|
- [Nowcasting and Forecasting of COVID-19](https://www.mrc-bsu.cam.ac.uk/tackling-covid-19/nowcasting-and-forecasting-of-covid-19/), from the University of Cambridge. Sadly solely for England, which has a great bureaucracy which can presumably track most if not all covid deaths.
|
||||||
|
- [BMW Cuts Profit Forecast Again, And Warns About Uncertainty](https://www.forbes.com/sites/neilwinton/2020/05/06/bmw-cuts-profit-forecast-again-and-warns-about-uncertainty/#2ac2be64468c), Forbes reports.
|
||||||
|
- [Central Bankers Adopt Scenario Forecasting for Post-Virus World](https://www.bloomberg.com/news/articles/2020-05-11/central-bankers-adopt-scenario-forecasting-for-post-virus-world). Otherwise, central banks are coming to terms with the depths of their uncertainty. I find it cute that China, seeing as how they're not going to be able to meet their GDP targets, is "considering dropping its traditional numerical GDP target", but see also [White House to skip economic forecast this summer showing depth of the downturn](https://www.politico.com/news/2020/05/28/white-house-to-skip-economic-forecast-287281).
|
||||||
|
- [Locust-tracking application for the UN](https://www.research.noaa.gov/article/ArtMID/587/ArticleID/2620/NOAA-teams-with-the-United-Nations-to-create-locust-tracking-application). (and [here](https://www.washingtonpost.com/weather/2020/05/13/east-africa-locust-forecast-tool/) is a take by the Washington Post), using software originally intended to track the movements of air polution. NOAA also sounds like a really cool organization: "NOAA Research enables better forecasts, earlier warnings for natural disasters, and a greater understanding of the Earth. Our role is to provide unbiased science to better manage the environment, nationally, and globally."
|
||||||
|
- [United Nations: World Economic Situation and Prospects as of mid-2020](https://www.un.org/development/desa/dpad/publication/world-economic-situation-and-prospects-as-of-mid-2020/). A recent report is out, which predicts a 3.2% contraction of the global economy. Between 34 and 160 million people are expected to fall below the extreme poverty line this year. Compare with [Fitch ratings](https://www.fitchratings.com/research/sovereigns/further-economic-forecast-cuts-global-recession-bottoming-out-26-05-2020), which foresee a 4.6% decline in global GDP.
|
||||||
|
- [Fox News](https://www.fox10phoenix.com/news/cdc-says-all-models-forecast-increase-in-covid-19-deaths-in-coming-weeks-exceeding-100k-by-june-1) and [Business Insider](https://www.businessinsider.com/cdc-forecasts-100000-coronavirus-deaths-by-june-1-2020-5?r=KINDLYSTOPTRACKINGUS) report about the CDC forecasting 100k deaths by June the 1st, differently.
|
||||||
|
- Yahoo has automated finance forecast reporting. It took me a while (two months) to notice that the low quality finance articles that were popping up in my google alerts were machine generated. See [Synovus Financial Corp. Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now](https://finance.yahoo.com/news/synovus-financial-corp-earnings-missed-152645825.html), [Wienerberger AG Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now](https://finance.yahoo.com/news/wienerberger-ag-earnings-missed-analyst-070545629.html), [Park Lawn Corporation Earnings Missed Analyst Estimates: Here's What Analysts Are Forecasting Now](https://news.yahoo.com/park-lawn-corporation-earnings-missed-120314826.html); they have a similar structure, paragraph per paragraph, and seem to have been generated from a template which changes a little bit depending on the data (they seem to have different templates for very positive, positive, neutral and negative change). To be clear, I could program something like this given a good finance api and a spare week/month, and in fact did so a couple of years ago for an automatic poetry generator. *But I didn't notice because I wasn't paying attention*.
|
||||||
|
- [Sports betting alternatives which are booming during the Corona shutdown](https://thegamehaus.com/sports/sports-betting-alternatives-which-are-booming-during-the-corona-shutdown/2020/05/15/). Suggested alternatives for bettors include e-sports, casinos, politics and reality-tv.
|
||||||
|
- Some transcient content on 538 about [Biden vs past democratic nomines](https://fivethirtyeight.com/features/how-does-biden-stack-up-to-past-democratic-nominees/), about [Trump vs Biden polls](https://fivethirtyeight.com/features/you-can-pay-attention-to-those-trump-vs-biden-polls-but-be-cautious/) and about [the USA vicepresidential draft](https://fivethirtyeight.com/features/its-time-for-another-2020-vice-presidential-draft/), and an old [review of the impact of VP candidates in USA elections](http://baseballot.blogspot.com/2012/07/politically-veepstakes-isnt-worth.html) which seems to have aged well. 538 also brings us this overview of [models with unrealistic-yet-clearly-stated assumptions](https://projects.fivethirtyeight.com/covid-forecasts/); apparently, deaths (not "confirmed deaths", just "deaths") according to John Hopkins University are flat out *linear* from April 1 to May 1.
|
||||||
|
- [Why Economic Forecasting Is So Difficult in the Pandemic](https://hbr.org/2020/05/why-economic-forecasting-is-so-difficult-in-the-pandemic). Harvard Review Economists share their difficulties. Problems include "not knowing for sure what is going to happen", the government passing legislation uncharacteristically fast, sampling errors and reduced response rates from surveys, and lack of knowledge about epidemiology.
|
||||||
|
- [Nowcasting the weather in Africa](https://phys.org/news/2020-05-storm-chasers-life-saving.html) to reduce fatalities.
|
||||||
|
- [IBM releases new AI forecasting tool](https://www.ibm.com/products/planning-analytics): "IBM Planning Analytics is an AI-infused integrated planning solution that automates planning, forecasting and budgeting." See [here](https://www.channelasia.tech/article/679887/ibm-adds-ai-fuelled-forecasting-planning-analytics-platform/) or [here](https://www.cio.com/article/3544611/ibm-adds-ai-fueled-forecasting-to-planning-analytics-platform.html) for a news take.
|
||||||
|
- [Auditor urges more oversight, better forecasting at the United State's Department of Transport](https://www.wral.com/coronavirus/auditor-urges-more-oversight-better-forecasting-at-dot/19106691/): "Instead of basing its spending plan on project-specific cost estimates, Wood said, the agency uses prior-year spending. That forecasting method doesn't account for cost increases or for years when there are more projects in the works." The budget of the organization is $5.9 billion. Problem could be solved with a prediction market.
|
||||||
|
- [Wimbledon organisers set to net £100 million insurance payout after taking out infectious diseases cover following 2003 SARS outbreak, with tournament now cancelled because of coronavirus](https://www.dailymail.co.uk/sport/tennis/article-8183419/amp/Wimbledon-set-net-huge-100m-insurance-payout-tournament-cancelled.html). Go Wimbledon!
|
||||||
|
- [Misunderstanding Of Coronavirus Predictions Is Eerily Similar To Weather Forecasting](https://www.forbes.com/sites/marshallshepherd/2020/05/22/misunderstanding-of-coronavirus-predictions-is-eerily-similar-to-weather-forecasting/#2f1288467f75), Forbes speculates.
|
||||||
|
|
||||||
|
## Other Media
|
||||||
|
Podcasts, blogposts, papers, tweets and other recent nontraditional media.
|
||||||
|
|
||||||
|
- [SlateStarCodex](https://slatestarcodex.com/2020/04/29/predictions-for-2020/) brings us a hundred more predictions for 2020. Some analysis by Zvi Mowshowitz [here](https://www.lesswrong.com/posts/gSdZjyFSky3d34ySh/slatestarcodex-2020-predictions-buy-sell-hold) and by [Bucky](https://www.lesswrong.com/posts/orSNNCm77LiSEBovx/2020-predictions).
|
||||||
|
- [FLI Podcast: On Superforecasting with Robert de Neufville](https://futureoflife.org/2020/04/30/on-superforecasting-with-robert-de-neufville/). Leaning towards introductory, broad and superficial; I would have liked to see a more intense drilling on some of the points. It still gives pointers to interesting stuff, though, chiefly [The NonProphets Podcast](https://nonprophetspod.wordpress.com/), which looks like it has some more in-depth stuff. Some quotes:
|
||||||
|
> So it’s not clear to me that our forecasts are necessarily affecting policy. Although it’s the kind of thing that gets written up in the news and who knows how much that affects people’s opinions, or they talk about it at Davos and maybe those people go back and they change what they’re doing.
|
||||||
|
|
||||||
|
> I wish it were used better. If I were the advisor to a president, I would say you should create a predictive intelligence unit using superforecasters. Maybe give them access to some classified information, but even using open source information, have them predict probabilities of certain kinds of things and then develop a system for using that in your decision making. But I think we’re a fair ways away from that. I don’t know any interest in that in the current administration.
|
||||||
|
|
||||||
|
> Now one thing I think is interesting is that often people, they’re not interested in my saying, “There’s a 78% chance of something happening.” What they want to know is, how did I get there? What is my arguments? That’s not unreasonable. I really like thinking in terms of probabilities, but I think it often helps people understand what the mechanism is because it tells them something about the world that might help them make a decision. So I think one thing that maybe can be done is not to treat it as a black box probability, but to have some kind of algorithmic transparency about our thinking because that actually helps people, might be more useful in terms of making decisions than just a number.
|
||||||
|
- [Forecasting s-curves is hard](https://constancecrozier.com/2020/04/16/forecasting-s-curves-is-hard/): Some sweet visualizations of what it says on the title.
|
||||||
|
- [Fashion Trend Forecasting](https://arxiv.org/pdf/2005.03297.pdf) using Instagram and baking preexisting knowledge into NNs.
|
||||||
|
- [Space Weather Challenge and Forecasting Implications of Rossby Waves](https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2018SW002109). Recent advances may help predict solar flares better. I don't know how bad the worst solar flare could be, and how much a two year warning could buy us, but I tend to view developments like this very positively.
|
||||||
|
- [The advantages and limitations of forecasting](https://rwer.wordpress.com/2020/05/12/the-advantages-and-limitations-of-forecasting/). A short and sweet blog post, with a couple of forecasting anecdotes and zingers.
|
||||||
|
- The [University of Washington Medicine](https://patch.com/washington/seattle/uw-medicine-forecasting-losses-500-million-summers-end) might be pretending they need more money to try to bait donors. Of course, America being America, they might actually not have enough money. During a pandemic. "UW Medicine has been at the forefront of the national response to COVID-19 in treating critically ill patients".
|
||||||
|
- [An analogy-based method for strong convection forecasts in China using GFS forecast data](https://www.tandfonline.com/doi/full/10.1080/16742834.2020.1717329). "Times in the past when the forecast parameters are most similar to those forecast at the current time are identified by searching a large historical numerical dataset", and this is used to better predict one particular class of meteorological phenomena. See [here](https://www.eurekalert.org/pub_releases/2020-05/ioap-ata051520.php) for a press release.
|
||||||
|
- Some interesting discussion about forecasting over at Twitter, in [David Manheim](https://twitter.com/davidmanheim)'s, [Philip Tetlock](https://twitter.com/PTetlock)'s accounts, some of which have been incorporated into this newsletter. [This twitter thread](https://twitter.com/lukeprog/status/1262492767869009920) contains some discussion about how Good Judgement Open, Metaculus and expert forecasters fare against each other. In particular, note the caveats by @LinchZhang: "For Survey 10, Metaculus said that question resolution was on 4pm ET Sunday, a lot of predictors (correctly) gauged that the data update on Sunday will be delayed and answered the letter rather than the spirit of the question (Metaculus ended up resolving it ambiguous)." [This thread](https://twitter.com/mlipsitch/status/1257857079756365824) by Marc Lipsitch has become popular, and I personally also enjoyed [these](https://twitter.com/LinchZhang/status/1262127601176334336) [two](https://twitter.com/LinchZhang/status/1261427045977874432) twitter threads by Linchuan Zhang, on forecasting mistakes.
|
||||||
|
- The Cato Institute releases [12 New Immigration Ideas for the 21st Century](https://www.cato.org/publications/white-paper/12-new-immigration-ideas-21st-century), including two from Robin Hanson: Choosing Immigrants through Prediction Markets & Transferable Citizenship.
|
||||||
|
- [Forecasting the Weather in 1946](https://www.smh.com.au/environment/weather/from-the-archives-1946-forecasting-the-world-s-weather-20200515-p54tfd.html)
|
||||||
|
- [A General Approach for Predicting the Behavior of the Supreme Court of the United States](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2463244). What seems to be a pretty simple algorithm (a random forest!) seems to do pretty well (70% accuracy). Their feature set is rich doesn't seem to include ideology. It was written in 2017; today, I'd expect that a random bright highschooler could do much beter.
|
||||||
|
- [Forecasting state expenses for budget is always a best guess](https://www.mercurynews.com/2020/05/20/letter-forecasting-state-expenses-for-budget-is-always-a-best-guess/); exactly what it says on the tin. Problem could be solved with a prediction market.
|
||||||
|
- [From Self-Prediction to Self-Defeat: Behavioral Forecasting, Self-Fulfilling Prophecies, and the Effect of Competitive Expectations](https://pubmed.ncbi.nlm.nih.gov/14561121/). Abstract: Four studies explored behavioral forecasting and the effect of competitive expectations in the context of negotiations. Study 1 examined negotiators' forecasts of how they would behave when faced with a very competitive versus a less competitive opponent and found that negotiators believed they would become more competitive. Studies 2 and 3 examined actual behaviors during a negotiation and found that negotiators who expected a very competitive opponent actually became less competitive, as evidenced by setting lower, less aggressive reservation prices, making less demanding counteroffers, and ultimately agreeing to lower negotiated outcomes. Finally, Study 4 provided a direct test of the disconnection between negotiators' forecasts for their behavior and their actual behaviors within the same sample and found systematic errors in behavioral forecasting as well as evidence for the self-fulfilling effects of possessing a competitive expectation.
|
||||||
|
- [Neuroimaging results altered by varying analysis pipelines](https://www.nature.com/articles/d41586-020-01282-z). Relevant paragraph: "the authors ran separate ‘prediction markets’, one for the analysis teams and one for researchers who did not participate in the analysis. In them, researchers attempted to predict the outcomes of the scientific analyses and received monetary payouts on the basis of how well they predicted performance. Participants — even researchers who had direct knowledge of the data set — consistently overestimated the likelihood of significant findings". Those who had more knowledge did slightly better, however.
|
||||||
|
|
||||||
|
## The Rocky Horror Picture Show.
|
||||||
|
If you have too much negativity in your life, you may want to skip this section, yet I have found negative stereotypes to be useful as a mirror with which to reflect on my own mistakes.
|
||||||
|
|
||||||
|
- [Kelsey Piper of Vox harshly criticizes the IHME model](https://www.vox.com/future-perfect/2020/5/2/21241261/coronavirus-modeling-us-deaths-ihme-pandemic). "Some of the factors that make the IHME model unreliable at predicting the virus may have gotten people to pay attention to it;" or "Other researchers found the true deaths were outside of the 95 percent confidence interval given by the model 70 percent of the time."
|
||||||
|
- The [Washington post](https://www.washingtonpost.com/outlook/2020/05/19/lets-check-donald-trumps-chances-getting-reelected/) offers a highly partisan view of Trump's chances of winning the election. The author, having already made a past prediction, and seeing as how other media outlets offer a conflicting perspective, rejects the information he's learnt, and instead can only come up with more reasons which confirm his initial position. Problem could be solved with a prediction market.
|
||||||
|
- [California politics pretends to be about recession forecasts](https://calmatters.org/economy/2020/05/newsom-economic-forecast-criticism-california-model-recession-budget/). Problem could be solved with a prediction market. See also: [Simulacra levels](https://www.lesswrong.com/posts/fEX7G2N7CtmZQ3eB5/simulacra-and-subjectivity?commentId=FgajiMrSpY9MxTS8b); the article is at least three levels removed from consideration about bare reality. Key quote, about a given forecasting model: "It’s just preposterously negative... How can you say that out loud without giggling?" See also some more prediction ping-pong, this time in New Jersey, [here](https://www.njspotlight.com/2020/05/fiscal-experts-project-nj-revenue-losses-wont-be-as-bad-as-murphys-team-forecast/). Problem could be solved with a prediction market.
|
||||||
|
- [What Is the Stock Market Even for Anymore?](https://www.nytimes.com/interactive/2020/05/26/magazine/stock-market-coronavirus-pandemic.html). A New York Times claims to have predicted that the market was going to fall (but can't prove it with, for example, a tweet, or a hash of a tweet), and nonetheless lost significant amounts of his own funds. ("The market dropped another 1,338 points the next day, and though my funds were tanking along with almost everyone else’s, I found some empty satisfaction, at least, in my prognosticating.") The rest of the article is about said reported being personally affronted with the market not falling further ("the stock market’s shocking resilience (at least so far) has looked an awful lot like indifference to the Covid-19 crisis and the economic calamity it has brought about. The optics, as they say, are terrible.")
|
||||||
|
- [Forecasting drug utilization and expenditure: ten years of experience in Stockholm](https://bmchealthservres.biomedcentral.com/articles/10.1186/s12913-020-05170-0). A normally pretty good forecasting model had the bad luck of not foreseeing a Black Swan, and sending a study to a journal just before a pandemic, so that it's being published now. They write: "According to the forecasts, the total pharmaceutical expenditure was estimated to increase between 2 and 8% annually. Our analyses showed that the accuracy of these forecasts varied over the years with a mean absolute error of 1.9 percentage points." They further conclude: "Based on the analyses of all forecasting reports produced since the model was established in Stockholm in the late 2000s, we demonstrated that it is feasible to forecast pharmaceutical expenditure with a reasonable accuracy." Presumably, this has increased further because of covid, sending the mean absolute error through the roof. If the author of this paper bites you, you become a Nassim Taleb.
|
||||||
|
- In this time of need, where global cooperation might prove to be immensely valuable, Italy has lessons to share about how to forecast the coronavirus. The article [Forecasting in the Time Of The Coronavirus](https://www.bancaditalia.it/media/notizie/2020/en_Previsioni_al_tempo_del_coronavirus_Locarno_Zizza.pdf), by the Central Bank of Italy, is only available in Italian. Mysteriously, the press release, however, is in [English](https://www.bancaditalia.it/media/notizia/forecasting-in-the-time-of-coronavirus/).
|
||||||
|
- Some films are so bad it's funny. [This article fills the same niche](https://www.moneyweb.co.za/investing/yes-it-is-possible-to-predict-the-market/) for forecasting. It has it all: Pythagorean laws of vibration, epicycles, an old and legendary master with mystical abilities, 90 year predictions which come true. Further, from the [Wikipedia entry](https://en.wikipedia.org/wiki/William_Delbert_Gann#Controversy): "He told me that his famous father could not support his family by trading but earned his living by writing and selling instructional courses."
|
||||||
|
- [Austin Health Official Recommends Cancelling All 2020 Large Events, Despite Unclear Forecasting](https://texasscorecard.com/local/austin-health-official-recommends-cancelling-all-2020-large-events-despite-unclear-forecasting/). Texan article does not consider the perspective that one might want to cancel large events precisely *because* of the forecasting uncertainty.
|
||||||
|
|
||||||
|
## Long content
|
||||||
|
This section contains items which have recently come to my attention, but which I think might still be relevant not just this month, but throughout the years. I dislike a bias towards recency in my content, and content in this section may or may not have been published in the last month.
|
||||||
|
|
||||||
|
- [Pan-African Heatwave Health Hazard Forecasting](http://www.walker.ac.uk/research/projects/pan-african-heatwave-health-hazard-forecasting/). "The main aim, is to raise the profile of heatwaves as a hazard on a global scale. Hopefully, the project will add evidence to this sparse research area. It could also provide the basis for a heat early warning system." The project looks to be in its early stages, yet nonetheless interesting.
|
||||||
|
- [How to evaluate 50% predictions](https://www.lesswrong.com/posts/DAc4iuy4D3EiNBt9B/how-to-evaluate-50-predictions). "I commonly hear (sometimes from very smart people) that 50% predictions are meaningless. I think that this is wrong."
|
||||||
|
- [Named Distributions as Artifacts](https://blog.cerebralab.com/Named%20Distributions%20as%20Artifacts). On how the named distributions we use (the normal distribution, etc.), were selected for being easy to use in pre-computer eras, rather than on being a good ur-prior on distributions for phenomena in this universe.
|
||||||
|
- [The fallacy of placing confidence in confidence intervals](https://link.springer.com/article/10.3758/s13423-015-0947-8). On how the folk interpretation of confidence intervals can be misguided, as it conflates: a. the long-run probability, before seeing some data, that a procedure will produce an interval which contains the true value, and b. and the probability that a particular interval contains the true value, after seeing the data. This is in contrast to Bayesian theory, which can use the information in the data to determine what is reasonable to believe, in light of the model assumptions and prior information. I found their example where different confidence procedures produce 50% confidence intervals which are nested inside each other particularly funny. Some quotes:
|
||||||
|
> Using the theory of confidence intervals and the support of two examples, we have shown that CIs do not have the properties that are often claimed on their behalf. Confidence interval theory was developed to solve a very constrained problem: how can one construct a procedure that produces intervals containing the true parameter a fixed proportion of the time? Claims that confidence intervals yield an index of precision, that the values within them are plausible, and that the confidence coefficient can be read as a measure of certainty that the interval contains the true value, are all fallacies and unjustified by confidence interval theory.
|
||||||
|
|
||||||
|
> “I am not at all sure that the ‘confidence’ is not a ‘confidence trick.’ Does it really lead us towards what we need – the chance that in the universe which we are sampling the parameter is within these certain limits? I think it does not. I think we are in the position of knowing that either an improbable event has occurred or the parameter in the population is within the limits. To balance these things we must make an estimate and form a judgment as to the likelihood of the parameter in the universe that is, a prior probability – the very thing that is supposed to be eliminated.”
|
||||||
|
|
||||||
|
> The existence of multiple, contradictory long-run probabilities brings back into focus the confusion between what we know before the experiment with what we know after the experiment. For any of these confidence procedures, we know before the experiment that 50 % of future CIs will contain the true value. After observing the results, conditioning on a known property of the data — such as, in this case, the variance of the bubbles — can radically alter our assessment of the probability.
|
||||||
|
|
||||||
|
> “You keep using that word. I do not think it means what you think it means.” Íñigo Montoya, The Princess Bride (1987)
|
||||||
|
- [Psychology of Intelligence Analysis](https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/books-and-monographs/psychology-of-intelligence-analysis/), courtesy of the American Central Intelligence Agency, seemed interesting, and I read chapters 4, 5 and 14. Sometimes forecasting looks like reinventing intelligence analysis; from that perspective, I've found this reference work useful. Thanks to EA Discord user @Willow for bringing this work to my attention.
|
||||||
|
- Chapter 4: Strategies for Analytical Judgement. Discusses and compares the strengths and weaknesses of four tactics: situational analysis (inside view), applying theory, comparison with historical situations, and immersing oneself on the data. It then brings up several suboptimal tactics for choosing among hypothesis.
|
||||||
|
- Chapter 5: When does one need more information, and in what shapes does new information come from?
|
||||||
|
> Once an experienced analyst has the minimum information necessary to make an informed judgment, obtaining additional information generally does not improve the accuracy of his or her estimates. Additional information does, however, lead the analyst to become more confident in the judgment, to the point of overconfidence.
|
||||||
|
|
||||||
|
> Experienced analysts have an imperfect understanding of what information they actually use in making judgments. They are unaware of the extent to which their judgments are determined by a few dominant factors, rather than by the systematic integration of all available information. Analysts actually use much less of the available information than they think they do.
|
||||||
|
|
||||||
|
> There is strong experimental evidence, however, that such self-insight is usually faulty. The expert perceives his or her own judgmental process, including the number of different kinds of information taken into account, as being considerably more complex than is in fact the case. Experts overestimate the importance of factors that have only a minor impact on their judgment and underestimate the extent to which their decisions are based on a few major variables. In short, people's mental models are simpler than they think, and the analyst is typically unaware not only of which variables should have the greatest influence, but also which variables actually are having the greatest influence.
|
||||||
|
|
||||||
|
- Chapter 14: A Checklist for Analysts. "Traditionally, analysts at all levels devote little attention to improving how they think. To penetrate the heart and soul of the problem of improving analysis, it is necessary to better understand, influence, and guide the mental processes of analysts themselves." The Chapter also contains an Intelligence Analysis reading list.
|
||||||
|
- [The Limits of Prediction: An Analyst’s Reflections on Forecasting](https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/csi-studies/studies/vol-63-no-4/Limits-of-Prediction.html), also courtesy of the American Central Intelligence Agency. On how intelligence analysts should inform their users of what they are and aren't capable of. It has some interesting tidbits and references on predicting discontinuities. It also suggests some guiding questions that the analyst may try to answer for the policymaker.
|
||||||
|
- What is the context and reality of the problem I am facing?
|
||||||
|
- How does including information on new developments affect my problem/issue?
|
||||||
|
- What are the ways this situation could play out?
|
||||||
|
- How do we get from here to there? and/or What should I be looking out for?
|
||||||
|
|
||||||
|
> "We do not claim our assessments are infallible. Instead, we assert that we offer our most deeply and objectively based and carefully considered estimates."
|
||||||
|
- [How to Measure Anything](https://www.lesswrong.com/posts/ybYBCK9D7MZCcdArB/how-to-measure-anything), a review. "Anything can be measured. If a thing can be observed in any way at all, it lends itself to some type of measurement method. No matter how “fuzzy” the measurement is, it’s still a measurement if it tells you more than you knew before. And those very things most likely to be seen as immeasurable are, virtually always, solved by relatively simple measurement methods."
|
||||||
|
- The World Meteorological organization, on their mandate to guarantee that [no one is surprised by a flood](https://public.wmo.int/en/our-mandate/water/no-one-is-surprised-by-a-flood). Browsing the webpage it seems that the organization is either a Key Organization Safeguarding the Vital Interests of the World or Just Another of the Many Bureaucracies Already in Existence, but it's unclear to me how to differentiate between the two. One clue may be their recent [Caribbean workshop on impact-based forecasting and risk scenario planning](https://public.wmo.int/en/media/news/caribbean-workshop-impact-based-forecasting-and-risk-scenario-planning), with the narratively unexpected and therefore salient presence of Gender Bureaus.
|
||||||
|
- [95%-ile isn't that good](https://danluu.com/p95-skill/): "Reaching 95%-ile isn't very impressive because it's not that hard to do."
|
||||||
|
- [The Backwards Arrow of Time of the Coherently Bayesian Statistical Mechanic](https://arxiv.org/abs/cond-mat/0410063): Identifying thermodinamic entropy with the Bayesian uncertainty of an ideal observer leads to problems, because as the observer observes more about the system, they update on this information, which in expectation reduces uncertainty, and thus entropy. But entropy increases with time.
|
||||||
|
- This might be interesting to students in the tradition of E.T. Jaynes: for example, the paper directly conflicts with this LessWrong post: [The Second Law of Thermodynamics, and Engines of Cognition](https://www.lesswrong.com/posts/QkX2bAkwG2EpGvNug/the-second-law-of-thermodynamics-and-engines-of-cognition), part of *Rationality, From AI to Zombies*. The way out might be to postulate that actually, the Bayesian updating process itself would increase entropy, in the form of e.g., the work needed to update bits on a computer. Any applications to Christian lore are left as an excercise for the reader. Otherwise, seeing two bright people being cogently convinced of different perspectives does something funny to my probabilities: it pushes them towards 50%, but also increases the expected time I'd have to spend on the topic to move them away from 50%.
|
||||||
|
- [Behavioral Problems of Adhering to a Decision Policy](https://pdfs.semanticscholar.org/7a79/28d5f133e4a274dcaec4d0a207daecde8068.pdf)
|
||||||
|
> Our judges in this study were eight individuals, carefully selected for their expertise as
|
||||||
|
handicappers. Each judge was presented with a list of 88 variables culled from the past performance charts. He was asked to indicate which five variables out of the 88 he would wish to use when handicapping a race, if all he could have was five variables. He was then asked to indicate which 10, which 20, and which 40 he would use if 10, 20, or 40 were available to him.
|
||||||
|
|
||||||
|
> We see that accuracy was as good with five variables as it was with 10, 20, or 40. The flat curve is an average over eight subjects and is somewhat misleading. Three of the eight actually showed a decrease in accuracy with more information, two improved, and three stayed about the same. All of the handicappers became more confident in their judgments as information increased.
|
||||||
|

|
||||||
|
|
||||||
|
- The study contains other nuggets, such as:
|
||||||
|
- An experiment on trying to predict the outcome of a given equation. When the feedback has a margin of error, this confuses respondents.
|
||||||
|
- "However, the results indicated that subjects often chose one gamble, yet stated a higher selling price for the other gamble"
|
||||||
|
- "We figured that a comparison between two students along the same dimension should be easier, cognitively, than a 13 comparison between different dimensions, and this ease of use should lead to greater reliance on the common dimension. The data strongly confirmed this hypothesis. Dimensions were weighted more heavily when common than when they were unique attributes. Interrogation of the subjects after the experiment indicated that most did not wish to change their policies by giving more weight to common dimensions and they were unaware that they had done so."
|
||||||
|
- "The message in these experiments is that the amalgamation of different types of information and different types of values into an overall judgment is a difficult cognitive process. In our attempts to ease the strain of processing information, we often resort to judgmental strategies that do an injustice to the underlying values and policies that we’re trying implement."
|
||||||
|
- "A major problem that a decision maker faces in his attempt to be faithful to his policy is the fact that his insight into his own behavior may be inaccurate. He may not be aware of the fact that he is employing a different policy than he thinks he’s using. This problem is illustrated by a study that Dan Fleissner, Scott Bauman, and I did, in which 13 stockbrokers and five graduate students served as subjects. Each subject evaluated the potential capital appreciation of 64 securities. [...] A mathematical model was then constructed to predict each subject's judgments. One output from the model was an index of the relative importance of each of the eight information items in determining each subject’s judgments [...] Examination of Table 4 shows that the broker’s perceived weights did not relate closely to the weights derived from their actual judgments.
|
||||||
|
- As remedies they suggest to create a model by elliciting the expert, either by having the expert make a large number of judgements and distillating a model, or by asking the expert what they think the most important factors are. A third alternative suggested is computer assistance, so that the experiment participants become aware of which factors influence their judgment.
|
||||||
|
- [Immanuel Kant, on Betting](https://www.econlib.org/archives/2014/07/kant_on_betting.html)
|
||||||
|
|
||||||
|
Vale.
|
||||||
|
|
||||||
|
Conflicts of interest: Marked as (c.o.i) throughout the text.
|
||||||
|
Note to the future: All links are automatically added to the Internet Archive. In case of link rot, go [there](https://archive.org/)
|
||||||
184
ea/ForecastingNewsletter/November2020.md
Normal file
|
|
@ -0,0 +1,184 @@
|
||||||
|
## Highlights
|
||||||
|
- DeepMind claims a major [breakthrough]((https://deepmind.com/blog/article/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology)) protein folding.
|
||||||
|
- OPEC forecasts [slower growth](https://www.cnbc.com/2020/11/11/oil-opec-cuts-2020-demand-forecast-again-on-rising-covid-cases.html)
|
||||||
|
- Gnosis announces [futarchy experiment](https://blog.gnosis.pm/announcing-gnosisdao-a7102fcf9224)
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Highlights
|
||||||
|
- In The News
|
||||||
|
- Prediction Markets & Forecasting Platforms
|
||||||
|
- United States Presidential Elections Post-mortems
|
||||||
|
- Hard To Categorize
|
||||||
|
- Long Content
|
||||||
|
|
||||||
|
Sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020) browse past newsletters [here](https://forum.effectivealtruism.org/s/HXtZvHqsKwtAYP6Y7), or view and upvote this newsletter on the Effective Altruism forum [here](https://forum.effectivealtruism.org/posts/DFNckNtbCwgiZCKEr/forecasting-newsletter-november-2020).
|
||||||
|
.
|
||||||
|
|
||||||
|
## In the News
|
||||||
|
|
||||||
|
DeepMind claims a major breakthrough in protein folding ([press release](https://deepmind.com/blog/article/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology), [secondary source](https://www.sciencemag.org/news/2020/11/game-has-changed-ai-triumphs-solving-protein-structures))
|
||||||
|
> DeepMind has developed a piece of AI software called AlphaFold that can accurately predict the structure that proteins will fold into in a matter of days.
|
||||||
|
|
||||||
|
> This computational work represents a stunning advance on the protein-folding problem, a 50-year-old grand challenge in biology. It has occurred decades before many people in the field would have predicted. It will be exciting to see the many ways in which it will fundamentally change biological research.
|
||||||
|
|
||||||
|
> Figuring out what shapes proteins fold into is known as the "protein folding problem", and has stood as a grand challenge in biology for the past 50 years. In a major scientific advance, the latest version of our AI system AlphaFold has been recognised as a solution to this grand challenge by the organisers of the biennial Critical Assessment of protein Structure Prediction (CASP). This breakthrough demonstrates the impact AI can have on scientific discovery and its potential to dramatically accelerate progress in some of the most fundamental fields that explain and shape our world.
|
||||||
|
|
||||||
|
> In the results from the 14th CASP assessment, released today, our latest AlphaFold system achieves a median score of 92.4 GDT overall across all targets. This means that our predictions have an average error (RMSD) of approximately 1.6 Angstroms, which is comparable to the width of an atom (or 0.1 of a nanometer). Even for the very hardest protein targets, those in the most challenging free-modelling category, AlphaFold achieves a median score of 87.0 GDT.
|
||||||
|
|
||||||
|
> Crucially, CASP chooses protein structures that have only very recently been experimentally determined (some were still awaiting determination at the time of the assessment) to be targets for teams to test their structure prediction methods against; they are not published in advance. Participants must blindly predict the structure of the proteins.
|
||||||
|
|
||||||
|
The Organization of the Petroleum Exporting Countries (OPEC) forecasts slower growth and slower growth in oil demand ([primary source](https://woo.opec.org/chapter.php?chapterNr=99), [secondary source](https://www.cnbc.com/2020/11/11/oil-opec-cuts-2020-demand-forecast-again-on-rising-covid-cases.html).) In particular, it forecasts long-term growth for OECD countries — which I take to mean that growth because of covid recovery is not counted — to be below 1%. On the one hand, their methodology is opaque, but on the other hand, I expect them to actually be trying to forecast growth and oil demand, because it directly impacts the amount of barrels it is optimal for them to produce.
|
||||||
|
|
||||||
|
Google and Harvard's Global Health Institute update their US covid model, and publish it on NeurIPS 2020 ([press release](https://cloud.google.com/blog/products/ai-machine-learning/google-and-harvard-improve-covid-19-forecasts?hl=en_US)), aiming to be robust, interpretable, extendable, and to have longer time horizons. They're also using it to advertise various Google products. It has been extended to [Japan](https://datastudio.google.com/u/0/reporting/8224d512-a76e-4d38-91c1-935ba119eb8f/page/GfZpB).
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting Platforms
|
||||||
|
|
||||||
|
Gnosis announces the GnosisDAO ([announcement](https://blog.gnosis.pm/announcing-gnosisdao-a7102fcf9224), [secondary source](https://www.coindesk.com/gnosis-dao-futarchy-prediction-markets-governance)), an organization governed by prediction markets (i.e., a [futarchy](http://mason.gmu.edu/~rhanson/futarchy.html)): "The mission of GnosisDAO is to successfully steward the Gnosis ecosystem through futarchy: governance by prediction markets."
|
||||||
|
|
||||||
|
Metaculus have a new report on forecasting covid vaccines, testing and economic impact ([summary](https://www.metaculus.com/news/2020/11/17/forecasting-covid-19-vaccines-testing-economic-impact/), [full report](https://drive.google.com/file/d/1c0wpt94ba3sJucGXJyKPxb-cNS2t2ArJ/view)). They also organized [moderator elections](https://www.metaculus.com/questions/5596/fall-2020-metaculus-moderator-election/) and are hiring for a [product manager](https://www.metaculus.com/news/2020/11/17/hiring/).
|
||||||
|
|
||||||
|
Prediction markets have kept selling Trump not to be president in February at $0.85 to $0.9 ($0.9 as of now, where the contract resolves to $1 if Trump isn't president in February). Non-American readers might want to explore [PolyMarket](https://polymarket.com/) or [FTX](https://ftx.com/en/trade/TRUMPFEB), American readers with some time on their hands might want to actually put some money into [PredictIt](https://twitter.com/dglid/status/1330653172856213504). Otherwise, some members of the broader Effective Altruism and rationality communities made a fair amount of money betting on the election.
|
||||||
|
|
||||||
|
CSET recorded [Using Crowd Forecasts to Inform Policy](https://www.youtube.com/watch?v=ghF2WWzamF8&t=2m04s) with [Jason Matheny](https://en.wikipedia.org/wiki/Jason_Gaverick_Matheny), CSET's Founding Director, previously Director of IARPA. I particularly enjoyed the verbal history bits, the sheer expertise Jason Matheny radiated, and the comments on how the US government currently makes decisions.
|
||||||
|
> Q: Has the CIA changed its approach to using numbers rather than words?
|
||||||
|
> A: No, not really. They use some prediction markets, but most analytic products are still based on verbiage.
|
||||||
|
|
||||||
|
As a personal highlight, I was referred to as "top forecaster Sempere" towards the end of [this piece](https://www.cset-foretell.com/blog/top-forecaster-techniques) by CSET. I've since then lost the top spot, and I'm back to holding the second place.
|
||||||
|
|
||||||
|
I also organized the [Forecasting Innovation Prize](https://forum.effectivealtruism.org/posts/8Nwy3tX2WnDDSTRoi/announcing-the-forecasting-innovation-prize) ([LessWrong link](https://www.lesswrong.com/posts/WRqvohbWoq2wQkxKN/announcing-the-forecasting-innovation-prize)), which offers $1000 for research and projects on judgemental forecasting. For inspiration, see the [project suggestions](https://forum.effectivealtruism.org/posts/8Nwy3tX2WnDDSTRoi/announcing-the-forecasting-innovation-prize#Some_Possible_Research_Areas). Another post of mine, [Predicting the Value of Small Altruistic Projects: A Proof of Concept Experiment](https://forum.effectivealtruism.org/posts/qb56nicbnj9asSemx/predicting-the-value-of-small-altruistic-projects-a-proof-of) might also be of interest to readers in the Effective Altruism community. In particular, I'm looking for volunteers to expand it.
|
||||||
|
|
||||||
|
## Negative Examples
|
||||||
|
|
||||||
|
[Release of Covid-19 second wave death forecasting 'not in public interest', claims Scottish Government](https://www.scotsman.com/health/coronavirus/release-covid-19-second-wave-death-forecasting-not-public-interest-claims-scottish-government-3040449)
|
||||||
|
> The Scottish Government has been accused of "absurd" decision making after officials blocked the release of forecasting analysis examining the potential number of deaths from a second wave of Covid-19.
|
||||||
|
|
||||||
|
> Officials refused to release the information on the basis that it related to the formulation or development of government policy and was "not in the public interest" as it could lead to officials not giving "full and frank advice" to ministers.
|
||||||
|
|
||||||
|
> The response also showed no forecasting analysis had been undertaken by the Scottish Government over the summer on the potential of a second wave of Covid-19 on various sectors.
|
||||||
|
|
||||||
|
## United States Presidential Election Post-mortems
|
||||||
|
|
||||||
|
Thanks to the Metaculus Discord for suggestions for this section.
|
||||||
|
|
||||||
|
### Independent postmortems
|
||||||
|
- David Glidden's ([@dglid](https://twitter.com/dglid)) comprehensive [spreadsheet](https://docs.google.com/spreadsheets/d/1E7w5Kh9zrRJZN2Hy4NLVVkEM7o_oxhEEM3MUvZTAuZw/edit#gid=1216775508) comparing 538, the Economist, Smarkets and PredictIt in terms of Brier scores for everything. tl;dr: Prediction Markets did better in closer states. (see [here](https://www.lesswrong.com/posts/muEjyyYbSMx23e2ga/scoring-2020-u-s-presidential-election-predictions) for the log score.)
|
||||||
|
- [Hindsight is 2020](https://predictingpolitics.com/2020/11/12/hindsight-is-2020/); a nuanced take.
|
||||||
|
- [2020 Election: Prediction Markets versus Polling/Modeling Assessment and Postmortem](https://thezvi.wordpress.com/2020/11/18/2020-election-prediction-markets-versus-polling-modeling-assessment-and-postmortem/).
|
||||||
|
> "We find a market that treated day after day of good things for Biden and bad things for Trump, in a world in which Trump was already the underdog, as not relevant to the probability that Trump would win the election."
|
||||||
|
|
||||||
|
> Markets overreacted during election night.
|
||||||
|
|
||||||
|
> \[On methodology: \] You bet into the market, but the market also gets to bet into your fair values. That makes it a fair fight." \[Note: see [here](https://pivs538.herokuapp.com/) for a graph through time, and [here](https://sethburn.wordpress.com/2020/11/01/nate-silver-and-others-dance-with-the-green-knight/) for the orginal, though less readable source\]
|
||||||
|
|
||||||
|
> ...polls are being evaluated, as I've emphasized throughout, against a polls plus humans hybrid. They are not being evaluated against people who don't look at polls. That's not a fair comparison.
|
||||||
|
- [Partisans, Sharps, And The Uninformed Quake US Election Market](https://www.playusa.com/2020-election-betting-market-keeps-going/). tl;dr: "I find myself really torn between wanting people to be more rational and make better decisions. And then also, like, well, I want people to offer 8-1 on Trump being in office in February."
|
||||||
|
|
||||||
|
### Amerian Mainstream Media
|
||||||
|
Mostly unnuanced.
|
||||||
|
|
||||||
|
- The Cook Political Report on [Why Couldn't Democrats Ride the Blue Wave?](https://cookpolitical.com/analysis/national/national-politics/why-couldnt-democrats-ride-blue-wave). tl;dr: "If you wanted to sum up the election results in a few words, those words might be that by the barest of majority, voters were anti-Trump—but they were not anti-Republican."
|
||||||
|
- Wall Street Journal's [The Price of Bad Polling](https://www.wsj.com/articles/the-price-of-bad-polling-11606084656) ([unpaywalled archive link](https://archive.is/GLcD0))
|
||||||
|
- ABC news: [Were 2020 election polls wrong?](https://abcnews.go.com/Politics/2020-election-polls-wrong-fivethirtyeights-nate-silver-explains/story)
|
||||||
|
- The New York Times: [What Went Wrong With Polling? Some Early Theories](https://www.nytimes.com/2020/11/10/upshot/polls-what-went-wrong.html) and [Why Political Polling Missed the Mark. Again.](https://www.nytimes.com/2020/11/12/us/politics/election-polls-trump-biden.html)
|
||||||
|
- Fox News (handpicked for interestingness; see [here](https://web.archive.org/web/20201201141709/https://news.google.com/search?q=Fox+news+polls&hl=en-US&gl=US&ceid=US%3Aen) for more representative sample): [Stock market predicts Trump will defeat Biden](https://www.foxbusiness.com/markets/stock-market-trump-defeat-biden); [Nate Silver defends his analysis of 2020 election polls](https://www.foxnews.com/politics/nate-silver-defends-pollsters-2020); [Frank Luntz urges pollsters to seek new profession after Trump outperforms polls: 'Sell real estate'](https://www.foxnews.com/media/frank-luntz-pollsters-trump-outperforms-polls); [Karl Rove says Trump outperforming polls was 'remarkable achievement'](https://www.foxnews.com/politics/karl-rove-trump-outperforming-polls-incredible).
|
||||||
|
|
||||||
|
### FiveThirtyEight.
|
||||||
|
- [We Have A Lot Of New Polls, But There's Little Sign Of The Presidential Race Tightening](https://fivethirtyeight.com/features/we-have-a-lot-of-new-polls-but-theres-little-sign-of-the-presidential-race-tightening/)
|
||||||
|
- [FiveThirtyEight's Final 2020 presidential election forecast](https://fivethirtyeight.com/features/final-2020-presidential-election-forecast/)
|
||||||
|
- [Biden Won — Pretty Convincingly In The End](https://fivethirtyeight.com/features/a-pretty-convincing-win-for-biden-and-a-mediocre-performance-for-down-ballot-democrats/)
|
||||||
|
|
||||||
|
### Andrew Gelman.
|
||||||
|
- [Don't kid yourself. The polls messed up—and that would be the case even if we'd forecasted Biden losing Florida and only barely winning the electoral college](https://statmodeling.stat.columbia.edu/2020/11/04/dont-kid-yourself-the-polls-messed-up-and-that-would-be-the-case-even-wed-forecasted-biden-losing-florida-and-only-barely-winning-the-electoral-college/#more-44749) Gelman
|
||||||
|
- [Comparing election outcomes to our forecast and to the previous election](https://statmodeling.stat.columbia.edu/2020/11/06/comparing-election-outcomes-to-our-forecast-and-to-the-previous-election/)
|
||||||
|
> As we've discussed elsewhere, we can't be sure why the polls were off by so much, but our guess is a mix of differential nonresponse (Republicans being less likely than Democrats to answer, even after adjusting for demographics and previous vote) and differential turnout arising from on-the-ground voter registration and mobilization by Republicans (not matched by Democrats because of the coronavirus) and maybe Republicans being more motivated to go vote on election day in response to reports of 100 million early votes.
|
||||||
|
- [So, what's with that claim that Biden has a 96% chance of winning?](https://statmodeling.stat.columbia.edu/2020/11/02/so-whats-with-that-claim-that-biden-has-a-96-chance-of-winning-some-thoughts-with-josh-miller/ )
|
||||||
|
- [Why we are better off having election forecasts](https://statmodeling.stat.columbia.edu/2020/11/12/can-we-stop-talking-about-how-were-better-off-without-election-forecasting/)
|
||||||
|
- See also: [Multilevel regression with poststratification](https://en.wikipedia.org/wiki/Multilevel_regression_with_poststratification).
|
||||||
|
|
||||||
|
## Hard to Categorize
|
||||||
|
|
||||||
|
Forbes on [how to improve hurricane forecasting](https://www.forbes.com/sites/forbestechcouncil/2020/11/16/hurricanes-blow-but-our-forecasting-sucks-a-lesson-in-cross-organizational-collaboration/?sh=62ca29f72e15):
|
||||||
|
> ...to greatly improve the hurricane intensity forecast, we need to increase the subsurface ocean measurements by at least one order of magnitude...
|
||||||
|
|
||||||
|
> One of the most ambitious efforts to gather subsurface data is Argo, an international program designed to build a global network of 4,000 free-floating sensors that gather information like temperature, salinity and current velocity in the upper 2,000 meters of the ocean.
|
||||||
|
|
||||||
|
> Argo is managed by NOAA's climate office that monitors ocean warming in response to climate change. This office has a fixed annual budget to accomplish the Argo mission. The additional cost of expanding Argo's data collection by 10 times doesn't necessarily help this office accomplish the Argo mission. However, it would greatly improve the accuracy of hurricane forecasts, which would benefit the NOAA's weather office — a different part of NOAA. And the overall benefit of improving even one major hurricane forecast would be to save billions \[in economic losses\], easily offsetting the entire cost to expand the Argo mission.
|
||||||
|
|
||||||
|
[In wake of bad salmon season, Russia calls for new forecasting approach](https://www.seafoodsource.com/news/supply-trade/in-wake-of-bad-salmon-season-russia-calls-for-new-forecasting-approach):
|
||||||
|
> In late October, Ilya Shestakov, head of the Russian Federal Agency for Fisheries, met with Russian scientists from the Russian Research Institute of Fisheries and Oceanography (VNIRO) to talk about the possible reasons for the difference. According to scientists, the biggest surprises came from climate change.
|
||||||
|
|
||||||
|
> "We have succeeded in doing a deeper analysis of salmon by the combination of fisheries and academic knowledge added by data from longstanding surveys," Marchenko said. "No doubt, we will able to enhance the accuracy of our forecasts by including climate parameters into our models."
|
||||||
|
|
||||||
|
[Political Polarization and Expected Economic Outcomes](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3720679) ([summary](https://johnhcochrane.blogspot.com/2020/10/what-you-believe-depends-on-where-you.html))
|
||||||
|
> "87% of Democrats expect Biden to win while 84% of Republicans expect Trump to win"
|
||||||
|
|
||||||
|
> "Republicans expect a fairly rosy economic scenario if Trump is elected but a very dire one if Biden wins. Democrats ... expect calamity if Trump is re- elected but an economic boom if Biden wins."
|
||||||
|
|
||||||
|
Dart Throwing Spider Monkey proudly presents the third part of his Intro to Forecasting series: [Building Probabalistic Intuition](https://www.youtube.com/watch?v=VI1aF4kvsS0)
|
||||||
|
|
||||||
|
[A gentle introduction to information charts](https://www.lesswrong.com/posts/2mTHKTMgNYRmLopNu/a-framework-for-thinking-about-single-predictions): a simple tool for thinking about probabilities in general, but in particular for predictions with a sample size of one.
|
||||||
|
|
||||||
|
[A youtube playlist with forecasting content](https://www.youtube.com/playlist?list=PLnUdbSv_SNUu--30vjEDQC5d26-12s0DC) h/t Michal Dubrawski.
|
||||||
|
|
||||||
|
[Farm-level outbreak forecasting tool expands to new regions](https://www.nationalhogfarmer.com/animal-health/farm-level-outbreak-forecasting-tool-expands-new-regions)
|
||||||
|
|
||||||
|
An article with some examples of [Crime Location Forecasting](https://thecrimereport.org/2020/11/06/crime-location-forecasting-is-it-entrapment/), and on whether it can be construed as entrapment.
|
||||||
|
|
||||||
|
[Why Forecasting Snow Is So Difficult](https://spectrumlocalnews.com/nys/hudson-valley/weather/2020/11/10/why-forecasting-snow-is-so-difficult): Because it is very sensitive to initial conditions.
|
||||||
|
|
||||||
|
[Google looking for new ways to predict cyber-attackers' behavior](https://portswigger.net/daily-swig/google-project-zero-to-form-crystal-ball-forecast-panel-to-help-improve-vulnerability-disclosure).
|
||||||
|
|
||||||
|
## Long Content
|
||||||
|
|
||||||
|
[Taking a disagreeing perspective improves the accuracy of people's quantitative estimates](https://scholar.google.com/citations?user=b8t6h0MAAAAJ&hl=en#d=gs_md_cita-d&u=%2Fcitations%3Fview_op%3Dview_citation%26hl%3Den%26user%3Db8t6h0MAAAAJ%26citation_for_view%3Db8t6h0MAAAAJ%3AkNdYIx-mwKoC%26tzom%3D-60), but this depends on the question type.
|
||||||
|
> ...research suggests that the same principles underlying the wisdom of the crowd also apply when aggregating multiple estimates from the same person – a phenomenon known as the "wisdom of the inner crowd"
|
||||||
|
|
||||||
|
> Here, we propose the following strategy: combine people's first estimate with their second estimate made from the perspective of a person they often disagree with. In five pre-registered experiments (total N = 6425, with more than 53,000 estimates), we find that such a strategy produces highly accurate inner crowds (as compared to when people simply make a second guess, or when a second estimate is made from the perspective of someone they often agree with). In explaining its accuracy, we find that taking a disagreeing perspective prompts people to consider and adopt second estimates they normally would not consider as viable option, resulting in first- and second estimates that are highly diverse (and by extension more accurate when aggregated). However, this strategy backfires in situations where second estimates are likely to be made in the wrong direction. Our results suggest that disagreement, often highlighted for its negative impact, can be a powerful tool in producing accurate judgments.
|
||||||
|
|
||||||
|
> ..after making an initial estimate, people can be instructed to base their additional estimate on different assumptions or pieces of information. A demonstrated way to do this has been through "dialectical bootstrapping" where, when making a second estimate, people are prompted to question the accuracy of their initial estimate. This strategy has been shown to increase the accuracy of the inner crowd by getting the same person to generate more diverse estimates and errors...
|
||||||
|
> ...as a viable method to obtain more diverse estimates, we propose to combine people's initial estimate with their second estimate made from the perspective of a person they often disagree with...
|
||||||
|
> ...although generally undesirable, research in group decision-making indicates that disagreement between individuals may actually be beneficial when groups address complex problems. For example, groups consisting of members with opposing views and opinions tend to produce more innovative solutions, while polarized editorial teams on Wikipedia (i.e., teams consisting of ideologically diverse sets of editors) produce higher quality articles...
|
||||||
|
|
||||||
|
> These effects occur due to the notion that disagreeing individuals tend to produce more diverse estimates, and by extension errors, which are cancelled out across group members when averaged.
|
||||||
|
> ...we conducted two (pre-registered) experiments...
|
||||||
|
|
||||||
|
> People who made a second estimate from the perspective of a person they often disagree with benefited more from averaging than people who simply made a second guess.
|
||||||
|
|
||||||
|
> ... However, although generally beneficial, this strategy backfired in situations where second estimates were likely to be made in the wrong direction. [...] For example, imagine being asked the following question: "What percent of China's population identifies as Christian?". The true answer to this question is 5.1% and if you are like most people, your first estimate is probably leaning towards this lower end of the scale (say your first estimate is 10%). Given the position of the question's true answer and your first estimate, your second estimate is likely to move away from the true answer towards the opposite side of the scale (similar to the scale-end-effect45), effectively hurting the accuracy of the inner crowd.
|
||||||
|
|
||||||
|
> We predicted that the average of two estimates would not lead to an accuracy gain in situations where second estimates are likely to be made in the wrong direction. We found this to be the case when the answer to a question was close to the scale's end (e.g., an answer being 2% or 98% on a 0%-100% scale).
|
||||||
|
|
||||||
|
[A 2016 article attacking Nate Silver's model](https://www.huffpost.com/entry/nate-silver-election-forecast_n_581e1c33e4b0d9ce6fbc6f7f), key to understanding why Nate Silver is often so smug.
|
||||||
|
|
||||||
|
[Historical Presidential Betting Markets](https://pubs.aeaweb.org/doi/pdf/10.1257/0895330041371277), in the US before 2004.
|
||||||
|
> ...we show that the market did a remarkable job forecasting elections in an era before scientific polling. In only one case did the candidate clearly favored in the betting a month before Election Day lose, and even state-specific forecasts were quite accurate. This performance compares favorably with that of the Iowa Elec-tronic Market (currently [in 2004] the only legal venue for election betting in the United States). Second, the market was fairly efficient, despite the limited information of participants and attempts to manipulate the odds by political parties and newspapers.
|
||||||
|
> The extent of activity in the presidential betting markets of this time was astonishingly large. For brief periods, betting on political outcomes at the CurbExchange in New York would exceed trading in stocks and bonds.
|
||||||
|
|
||||||
|
> Covering developments in the Wall Street betting market was a staple of election reporting before World War II. Prior to the innovative polling efforts of Gallup, Roper and Crossley, the other information available about future election outcomes was limited to the results from early-season contests, overtly partisan canvasses and straw polls of unrepresentative and typically small samples. The largest and best-known nonscientific survey was the Literary Digest poll, which tabulated millions of returned postcard ballots that were mass mailed to a sample drawn from telephone directories and automobile registries. After predicting the presidential elections correctly from 1916 to 1932, the Digest famously called the 1936 contest for Landon in the election that F. Roosevelt won by the largest Electoral College landslide of all time. Notably, although the Democrat's odds prices were relatively low in 1936, the betting market did pick the winner correctly
|
||||||
|
> The betting quotes filled the demand for accurate odds from a public widely interested in wagering on elections. In this age before mass communication technologies reached into America's living rooms, election nights were highly social events, comparable to New Year's Eve or major football games. In large cities,crowds filled restaurants, hotels and sidewalks in downtown areas where newspapers and brokerage houses would publicize the latest returns and people withsporting inclinations would wager on the outcomes. Even for those who could not afford large stakes, betting in the run-up to elections was a cherished ritual. Awidely held value was that one should be prepared to "back one's beliefs" either with money or more creative dares. Making freak bets—where the losing bettor literally ate crow, pushed the winner around in a wheelbarrow or engaged in similar public displays—was wildly popular
|
||||||
|
|
||||||
|
> Gilliams (1901, p. 186) offered "a moderate estimate" that in the 1900 election "there were fully a half-million such \[freak\]bets—about one for every thirty voters." In this environment, it is hardly surprising that the leading newspapers kept their readership well informed about the latest market odds.
|
||||||
|
|
||||||
|
> The newspapers recorded many betting and bluffing contests between Col. Thomas Swords, Sergeant of Arms of the National RepublicanParty, and Democratic betting agents representing Richard Croker, Boss of Tam-many Hall, among others. In most but not all instances, these officials appear to betin favor of their party's candidate; in the few cases where they took the other side, it was typically to hedge earlier bets.
|
||||||
|
|
||||||
|
> ...In conclusion, the historical betting markets do not meet all of the exactingconditions for efficiency, but the deviations were not usually large enough togenerate consistently profitable betting strategies using public information
|
||||||
|
|
||||||
|
> The newspapers reported substantially less betting activity in specific contestsand especially after 1940. In part, this reduction in reporting reflected a growingreluctance of newspapers to give publicity to activities that many considered un-ethical. There were frequent complaints that election betting was immoral andcontrary to republican values. Among the issues that critics raised were moralhazard, election tampering, information withholding and strategic manipulation.
|
||||||
|
|
||||||
|
> In response to such concerns, New York state laws did increasingly attempt to limit organized election betting. Casual bets between private individuals always remained legal in New York. However, even an otherwise legal private bet on elections technically disqualified the participants from voting—although this provision was rarely enforced—and the legal system also discouraged using the courts to collect gambling debts. Anti-gambling laws passed in New York during the late 1870s and the late 1900s appear to put a damper on election betting, but in both cases, the market bounced back after the energy of the moral reformers flagged. Ultimately, New York's legalization of parimutuel betting on horse races in 1939 may have done more to reduce election betting than any anti-gambling policing. With horseracing, individuals interested in gambling could wager on several contests promising immediate rewards each day, rather than waiting through one long political contest.
|
||||||
|
> The New York Stock Exchange and the CurbMarket also periodically tried to crack down. The exchanges characteristically did not like the public to associate their socially productive risk-sharing and risk-taking functions with gambling on inherently zero-sum public or sporting events. In the 1910s and again after the mid-1920s, the stock exchanges passed regulations to reduce the public involvement of their members. In May 1924, for example, both the New York Stock Exchange and the Curb Market passed resolutions expressly barring their members from engaging in election gambling. After that, while betting activity continued to be reported in the newspapers, the articles rarely named the participants. During the 1930s, the press noted that securities of private electrical utilities had effectively become wagers on Roosevelt (on the grounds that New Deal policy initiatives such as the formation of the Securities and Exchange Commission and the Tennessee Valley Authority constrained the profits of existing private utilities).
|
||||||
|
|
||||||
|
> A final force pushing election betting underground was the rise of scientific polling. For newspapers, one of the functions of reporting Wall Street betting odds had been to provide the best available aggregate information [...] The scientific polls, available on a weekly basis, provided the media with a ready substitute for the betting odds, one not subject to the moral objections against gambling.
|
||||||
|
|
||||||
|
> In summer 2003, word leaked out that the Department of Defense was considering setting up a Policy Analysis Market, somewhat similar to the Iowa Electronic Market, which would seek to provide a market consensus about the likelihood of international political developments, especially in the Middle East. Critics argued that this market was subject to manipulation by insiders and might allow extremists to profit financially from their actions.
|
||||||
|
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [there](https://archive.org/) and input the dead link.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
> "I'd rather be a bookie than a goddamned poet." — Sherman Kent, 1964, when pushing for more probabilistic forecasts and being accused of trying to turn the CIA into "the biggest bookie shop in town."
|
||||||
|
|
||||||
|
***
|
||||||
98
ea/ForecastingNewsletter/October2020.md
Normal file
|
|
@ -0,0 +1,98 @@
|
||||||
|
## Highlights
|
||||||
|
- Facebook's Forecast now out of [out of beta](https://npe.fb.com/2020/10/01/forecast-update-making-forecast-available-to-everyone/).
|
||||||
|
- British Minister and experts give [probabilistic predictions](https://www.independent.co.uk/news/uk/politics/brexit-trade-deal-chances-probability-likelihood-boris-johnson-eu-summit-b1045775.html) of the chance of a Brexit deal.
|
||||||
|
- CSET/Foretell publishes an [issue brief](https://cset.georgetown.edu/wp-content/uploads/CSET-Future-Indices.pdf) on their approach to using forecasters to inform big picture policy questions.
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Highlights
|
||||||
|
- Prediction Markets & Forecasting Platforms
|
||||||
|
- In The News
|
||||||
|
- (Corrections)
|
||||||
|
- Long Content
|
||||||
|
- Hard To Categorize
|
||||||
|
|
||||||
|
FORUM: Sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020), browse past newsletters [here](https://forum.effectivealtruism.org/s/HXtZvHqsKwtAYP6Y7) or view this newsletter on the Effective Altruism forum [here](https://forum.effectivealtruism.org/posts/Y3QCTCKFNWrq9M7cF/forecasting-newsletter-october-2020). I'm considering creating a Patreon or substack for this newsletter; if you have any strong views, leave a [comment](https://forum.effectivealtruism.org/posts/Y3QCTCKFNWrq9M7cF/forecasting-newsletter-october-2020).
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting Platforms
|
||||||
|
|
||||||
|
Facebook's Forecast app now [out of beta](https://npe.fb.com/2020/10/01/forecast-update-making-forecast-available-to-everyone/) in the US and Canada.
|
||||||
|
|
||||||
|
Hypermind, a prediction market with virtual points but occasional monetary rewards, is organizing a [contest](https://prod.lumenogic.com/ngdp/en/welcome.html) for predicting US GDP in 2020, 2021 and 2022. Prizes sum up to $90k.
|
||||||
|
|
||||||
|
Metaculus held the [Road to Recovery](https://www.metaculus.com/questions/5335/forecasting-tournament--road-to-recovery/), and [20/20 Insight Forecasting](https://www.metaculus.com/questions/5336/the-2020-insight-forecasting-contest/) contests. It and collaborators also posted the results of their [2020 U.S. Election Risks Ssurvey](https://www.metaculus.com/news/2020/10/20/results-of-2020-us-election-risks-survey/).
|
||||||
|
|
||||||
|
[CSET](https://cset.georgetown.edu/wp-content/uploads/CSET-Future-Indices.pdf) publishes a report on using forecasters to inform big picture policy questions.
|
||||||
|
> We illustrate Foretell’s methodology with a concrete example: First, we describe three possible scenarios, or ways in which the tech-security landscape might develop over the next five years. Each scenario reflects different ways in which U.S.-China tensions and the fortunes of the artificial intelligence industry might develop. Then, we break each scenario down into near-term predictors and identify one or more metrics for each predictor. We then ask the crowd to forecast the metrics. Lastly, we compare the crowd’s forecasts with projections based on historical data to identify trend departures: the extent to which the metrics are expected to depart from their historical trajectories.
|
||||||
|
|
||||||
|
Replication Markets opens their [Prediction Market for COVID-19 Preprints](https://www.replicationmarkets.com/index.php/rm-c19/). Surveys opened on October 28, and markets will open on November 11, 2020.
|
||||||
|
|
||||||
|
## In the News
|
||||||
|
|
||||||
|
The European Union is attempting to build a model of the Earth [at 1km resolution](https://www.sciencemag.org/news/2020/10/europe-building-digital-twin-earth-revolutionize-climate-forecasts) as a test ground for its upcoming supercomputers. Typical models run at a resolution of 10 to 100km.
|
||||||
|
|
||||||
|
Michael Gove, a British Minister, gave a [66% chance to a Brexit deal](https://www.theguardian.com/politics/2020/oct/07/eu-needs-clear-sign-uk-will-get-real-in-brexit-talks-says-irish-minister). The Independent follows up by [giving the probabilities of different experts](https://www.independent.co.uk/news/uk/politics/brexit-trade-deal-chances-probability-likelihood-boris-johnson-eu-summit-b1045775.html)
|
||||||
|
|
||||||
|
Some 538 highlights:
|
||||||
|
- US general election polls are generally a random walk, rather than [having momentum](https://fivethirtyeight.com/features/the-misunderstanding-of-momentum/).
|
||||||
|
- [Pollsters have made some changes since 2016](https://fivethirtyeight.com/features/what-pollsters-have-changed-since-2016-and-what-still-worries-them-about-2020/), most notably weighing by education.
|
||||||
|
- An [interactive presidential forecast](https://fivethirtyeight.com/features/were-letting-you-mess-with-our-presidential-forecast-but-try-not-to-make-the-map-too-weird/)
|
||||||
|
|
||||||
|
[New York magazine](https://nymag.com/intelligencer/2020/10/nate-silver-and-g-elliott-morris-are-fighting-on-twitter.html) goes over some differences between 538's and The Economist's forecast for the US election.
|
||||||
|
|
||||||
|
[Reuters](https://www.reuters.com/article/global-forex-election/fx-options-market-reflects-more-confidence-in-biden-election-win-idUSL1N2GT207) looks at the volatility between the dollar and the yen or Swiss franc as a proxy for tumultuous elections. Reuters' interpretation is that a decline in long-run volatility implies that the election is not expected to be contested.
|
||||||
|
|
||||||
|
Meanwhile, new systems for [forecasting outbreaks](https://www.porkbusiness.com/article/forecasting-outbreaks-could-be-game-changer-pork-industry) in the American pork industry may help prevent outbreaks, and also make the industry more profitable.
|
||||||
|
- On the topic of animals, see also a Metaculus question on whether [the EU will announce going cage-free by 2024](https://www.metaculus.com/questions/5431/will-the-eu-announce-by-2024-going-cage-free/).
|
||||||
|
|
||||||
|
## Corrections
|
||||||
|
|
||||||
|
In the September newsletter, I claimed that bets on the order of $50k could visibly move Betfair's odds. I got some [pushback](https://www.reddit.com/r/slatestarcodex/comments/j25ct9/what_are_everyones_probabilities_for_a_biden_win/g778mg8/?context=8&depth=9). I asked Betfair itself, and their answer was:
|
||||||
|
|
||||||
|
> It would definitely be an oversimplification to say that “markets can be moved with 10 to 50k”, because it would depend on a number of other factors such as how much is available at that price at any one time and if anyone puts more money up at that price once all available money is taken.
|
||||||
|
|
||||||
|
> For example if someone placed £100k on Biden at 1.44 and there was £35k at 1.45, and £57k at 1.44, then around £7k would be unmatched and the market would now be 1.43-1.44 on Biden. But if someone else still thinks the price should remain at 1.45-1.46 they could place bets to get it back to that, so the market will shift back almost immediately.
|
||||||
|
|
||||||
|
> So to clarify, the bets outlined in those articles aren’t necessarily the sole reason for the market moving, therefore they can’t be deemed the causal connection. They are just headline examples to provide colour to the betting patterns at the time. I hope that is useful, let me know if you need any more info.
|
||||||
|
|
||||||
|
## Negative Examples
|
||||||
|
Boeing [releases](https://www.fool.com/investing/2020/10/15/boeings-commercial-market-outlook-seems-optimistic/) an extremely positive market outlook. "A year ago, Boeing was predicting services market demand to be $3.13 trillion from 2019-2028, making the prediction for $3 trillion from 2020-2029 look optimistic."
|
||||||
|
|
||||||
|
## Long Content
|
||||||
|
The [World Agricultural Supply and Demand Estimates](https://www.usda.gov/oce/commodity/wasde) is a monthly report by the US Department of Agriculture. It provides monthly estimates and past figures for crops worldwide, and for livestock production in the US specifically (meat, poultry, dairy), which might be of interest to the animal suffering movement. It also provides estimates of the past reliability of those forecasts. The October report can be found [here](https://www.usda.gov/oce/commodity/wasde/wasde1020.pdf), along with a summary [here](https://www.feedstuffs.com/markets/usda-raises-meat-poultry-production-forecast). The image below presents the 2020 and 2021 predictions, as well as the 2019 numbers:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
The Atlantic considers scenarios under which [Trump refuses to concede](https://www.theatlantic.com/magazine/archive/2020/11/what-if-trump-refuses-concede/616424/). Warning: very long, very chilling.
|
||||||
|
|
||||||
|
National Geographic on [the limits and recent history of weather forecasting](https://www.nationalgeographic.com/science/2020/10/hurricane-path-forecasts-have-improved-can-they-get-better/). There are reasons to think that forecasting the weather accurately two weeks in advance might be difficult.
|
||||||
|
|
||||||
|
Andreas Stuhlmüller, of Ought, plays around with GPT-3 to [output probabilities](https://twitter.com/stuhlmueller/status/1317492314495909888); I'm curious to see what comes out of it. I'd previously tried (and failed) to get GPT-3 to output reasonable probabilities for Good Judgment Open questions.
|
||||||
|
|
||||||
|
A 2019 paper by Microsoft on [End-User Probabilistic Programming](https://www.microsoft.com/en-us/research/uploads/prod/2019/09/End-User-Probabilistic-Programming-QEST-2019.pdf), that is, on adding features to spreadsheet software to support uncertain values, quantify uncertainty, propagate errors, etc.
|
||||||
|
|
||||||
|
The [2020 Presidential Election Forecasting symposium](https://www.cambridge.org/core/journals/ps-political-science-and-politics/2020-presidential-election-forecasting-symposium) presents 12 different election forecasts, ranging from blue wave to Trump win. [Here](https://www.cambridge.org/core/services/aop-cambridge-core/content/view/78235400F6BB7E2E370214D1A2307028/S104909652000147Xa.pdf/introduction_to_forecasting_the_2020_us_elections.pdf) is an overview.
|
||||||
|
|
||||||
|
[Blue Chip Economic Indicators](https://lrus.wolterskluwer.com/store/product/blue-chip-economic-indicators/) and [Blue Chip financial forecasts](https://lrus.wolterskluwer.com/store/product/blue-chip-financial-forecasts/) are an extremely expensive forecasting option for various econometric variables. A monthly suscription costs $2,401.00 and $2,423.00, respectively, and provides forecasts by 50 members of prestigious institutions ("Survey participants such as Bank of America, Goldman Sachs & Co., Swiss Re, Loomis, Sayles & Company, and J.P. MorganChase, provide forecasts..."). An estimate of previous track record and accuracy [isn't available](https://www.overcomingbias.com/2020/08/how-to-pick-a-quack.html) before purchase. Further information on [Wikipedia](https://en.wikipedia.org/wiki/Blue_Chip_Economic_Indicators)
|
||||||
|
- [Chief U.S. economist Ellen Zentner of Morgan Stanley](https://asunow.asu.edu/20201005-morgan-stanley-economist-wins-lawrence-r-klein-award-forecasting-accuracy) won the [Lawrence R. Klein Award](https://asunow.asu.edu/20201005-morgan-stanley-economist-wins-lawrence-r-klein-award-forecasting-accuracy) for the most accurate econometric forecasts among the 50 groups who participate in Blue Chip financial forecast surveys.
|
||||||
|
- I would be very curious to see if Metaculus' top forecasters, or another group of expert forecasts, could beat the Blue Chips. I'd also be curious how they fared on January, February and March of this year.
|
||||||
|
|
||||||
|
## Hard to categorize.
|
||||||
|
|
||||||
|
Scientists use [precariously balanced rock formations to improve accuracy of earthquake forecasts](https://www.dailymail.co.uk/sciencetech/article-8798677/Rock-clocks-balanced-boulders-improve-accuracy-earthquake-forecasts.html). They can estimate when the rock formation appeared, and can calculate what magnitude an earthquake would have had to be to destabilize it. Overall, a neat proxy.
|
||||||
|
|
||||||
|
Some [superforecasters](https://twitter.com/annieduke/status/1313653673994514432) to follow on twitter.
|
||||||
|
|
||||||
|
*Dart Throwing Spider Monkey* proudly presents *[Intro to Forecasting 01 - What is it and why should I care?](https://www.youtube.com/watch?v=e6Q7Ez3PkOw)* and *[Intro to Forecasting 02 - Reference class forecasting](https://www.youtube.com/watch?v=jrU3o7wK23s)*.
|
||||||
|
|
||||||
|
I've gone through the Effective Altruism Forum and LessWrong and added or made sure that the forecasting tag is applied to the relevant posts for October (LessWrong [link](https://www.lesswrong.com/tag/forecasting-and-prediction?sortedBy=new), Effective Altruism forum [link](https://forum.effectivealtruism.org/tag/forecasting?sortedBy=new)). This provides a change-log for the month. For the Effective Altruism forum, this only includes Linch Zhang's post on [Some learnings I had from forecasting in 2020](https://forum.effectivealtruism.org/posts/kAMfrLJwHpCdDSqsj/some-learnings-i-had-from-forecasting-in-2020). For LessWrong, this also includes a [post announcing that Forecast, a prediction platform by Facebook](https://www.lesswrong.com/posts/CZRyFcp6HSyZ7Jj8Q/launching-forecast-a-community-for-crowdsourced-predictions) is now out of beta.
|
||||||
|
- For readers coming from GJOpen or from CSET, the Effective Altruism forum and Less Wrong are online forums which attempt to host high-quality discussion devoted to doing good more effectively and human rationality, among other things.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [there](https://archive.org/) and input the dead link.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
Using actuarial life tables and an adjustment for covid, the implied probability that all 246 readers of this newsletter drop dead before the next month is at least 10^(-900) (if they were uncorrelated). See [this Wikipedia page](https://en.wikipedia.org/wiki/Orders_of_magnitude_(probability)) or [this xkcd comic](https://xkcd.com/2379/) for a comparison with other low probability events, such as asteroid impacts.
|
||||||
|
|
||||||
|
***
|
||||||
23
ea/ForecastingNewsletter/README.md
Normal file
|
|
@ -0,0 +1,23 @@
|
||||||
|
## A Forecasting Newsletter
|
||||||
|
|
||||||
|
A monthly forecasting newsletter with a focus on experimental forecasting. You can sign up [here](https://forecasting.substack.com/). Also available on the [EA Forum](https://forum.effectivealtruism.org/s/HXtZvHqsKwtAYP6Y7).
|
||||||
|
|
||||||
|
From December 2020 onwards, this newsletter lives on [forecasting.substack.com](https://forecasting.substack.com/).
|
||||||
|
|
||||||
|
## Past history
|
||||||
|
|
||||||
|
- [April 2021](https://forecasting.substack.com/p/forecasting-newsletter-april-2021)
|
||||||
|
- [March 2021](https://forecasting.substack.com/p/forecasting-newsletter-march-2021)
|
||||||
|
- [February 2021.](https://forecasting.substack.com/p/forecasting-newsletter-february-2021)
|
||||||
|
- [January 2021.](https://forecasting.substack.com/p/forecasting-newsletter-january-2021)
|
||||||
|
- [2020: Forecasting in Review](https://forecasting.substack.com/p/2020-forecasting-in-review)
|
||||||
|
- [December 2020](https://forecasting.substack.com/p/forecasting-newsletter-december-2020)
|
||||||
|
- [November 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/October2020)
|
||||||
|
- [October 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/October2020)
|
||||||
|
- [September 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/September2020)
|
||||||
|
- [August 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/August2020)
|
||||||
|
- [July 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/July2020)
|
||||||
|
- [June 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/June2020)
|
||||||
|
- [May 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/May2020)
|
||||||
|
- [April 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/April2020) (experimental)
|
||||||
|
- [March 2020](https://nunosempere.github.io/ea/ForecastingNewsletter/March2020) (proof of concept)
|
||||||
168
ea/ForecastingNewsletter/September2020.md
Normal file
|
|
@ -0,0 +1,168 @@
|
||||||
|
## Highlights
|
||||||
|
|
||||||
|
- Red Cross and Red Crescent societies have been trying out [forecast based financing](https://www.forecast-based-financing.org/our-projects/what-can-go-wrong/), where funds are released before a potential disaster happens based on forecasts thereof.
|
||||||
|
- Andrew Gelman releases [Information, incentives, and goals in election forecasts](http://www.stat.columbia.edu/~gelman/research/unpublished/forecast_incentives3.pdf); 538's 80% political predictions turn out to have happened [88% of the time](https://projects.fivethirtyeight.com/checking-our-work/).
|
||||||
|
- Nonprofit Ought organizes a [forecasting thread on existential risk](https://www.lesswrong.com/posts/6x9rJbx9bmGsxXWEj/forecasting-thread-existential-risk-1), where participants display and discuss their probability distributions for existential risk.
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Highlights
|
||||||
|
- Prediction Markets & Forecasting Platforms
|
||||||
|
- In The News
|
||||||
|
- Hard To Categorize
|
||||||
|
- Long Content
|
||||||
|
|
||||||
|
Sign up [here](https://forecasting.substack.com/p/forecasting-newsletter-december-2020) or browse past newsletters [here](https://forum.effectivealtruism.org/s/HXtZvHqsKwtAYP6Y7).
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting Platforms
|
||||||
|
|
||||||
|
Metaculus updated their [track record page](https://www.metaculus.com/questions/track-record/). You can now look at accuracy across time, at the distribution of brier scores, and a calibration graph. They also have a new black swan question: [When will US metaculus users face an emigration crisis?](https://www.metaculus.com/questions/5287/when-will-america-have-an-emigration-crisis/).
|
||||||
|
|
||||||
|
Good Judgement Open has a [thread](https://www.gjopen.com/questions/1779-are-there-any-forecasting-tips-tricks-and-experiences-you-would-like-to-share-and-or-discuss-with-your-fellow-forecasters) in which forecasters share and discuss tips, tricks and experiences. An account is needed to browse it.
|
||||||
|
|
||||||
|
[Augur](https://www.augur.net/blog/amm-para-augur/) modifications in response to higher ETH prices. Some unfiltered comments [on reddit](https://www.reddit.com/r/ethfinance/comments/ixhy3j/daily_general_discussion_september_22_2020/g68yra6/?context=3)
|
||||||
|
|
||||||
|
An overview of [PlotX](https://blockonomi.com/plotx-guide/), a new decentralized prediction protocol/marketplace. PlotX focuses on non-subjective markets that can be programmatically determined, like the exchange rate between currencies or tokens.
|
||||||
|
|
||||||
|
A Replication Markets participant wrote [What's Wrong with Social Science and How to Fix It: Reflections After Reading 2578 Papers](https://fantasticanachronism.com/2020/09/11/whats-wrong-with-social-science-and-how-to-fix-it/). See also: [An old long-form introduction to Replication Markets](https://www.adamlgreen.com/replication-markets/).
|
||||||
|
|
||||||
|
Georgetown's CSET is attempting to use forecasting to influence policy. A seminar discussing their approach [Using Crowd Forecasting to Inform Policy with Jason Matheny](https://georgetown.zoom.us/webinar/register/WN_nlXO7sQdSYyYBqhnzkh3hg) is scheduled for the 19th of October. But their current forecasting tournament, foretell, isn't yet very well populated, and the aggregate isn't that good because participants don't update all that often, leading to sometimes clearly outdated aggregates. Perhaps because of this relative lack of competition, my team is in 2nd place at the time of this writting (with myself at #6, Eli Lifland at #12 and Misha Yagudin at #21). You can join foretell [here](https://www.cset-foretell.com/).
|
||||||
|
|
||||||
|
There is a new contest on Hypermind, [The Long Fork Project](https://prod.hypermind.com/longfork/en/welcome.html), which aims to predict the impact of a Trump or a Biden victory in November, with $20k in prize money. H/t to user [ChickCounterfly](https://www.lesswrong.com/posts/hRsRgRcRk3zHLPpqm/forecasting-newsletter-august-2020?commentId=8gAKasi8w5v64QpbM).
|
||||||
|
|
||||||
|
The University of Chicago's Effective Altruism group is hosting a forecasting tournament between all interested EA college groups starting October 12th, 2020. More details [here](https://forum.effectivealtruism.org/posts/rePMmgXLwdSuk5Edg/ea-uni-group-forecasting-tournament)
|
||||||
|
|
||||||
|
## In the News
|
||||||
|
|
||||||
|
News media sensationalizes essentially random fluctuations on US election odds caused by big bettors entering prediction markets such as Betfair, where bets on the order of $50k can visibly alter the market price. Simultaneously, polls/models and prediction market odds have diverged, because a substantial fraction of bettors lend credence to the thesis that polls will be biased as in the previous elections, even though polling firms seem to have improved their methods.
|
||||||
|
- [Trump overtakes Biden as favorite to win in November: Betfair Exchange](https://www.reuters.com/article/us-usa-elections-bets-idUSKBN25T1L6)
|
||||||
|
- [US Election: Polls defy Trump's comeback narrative but will the market react?](https://betting.betfair.com/politics/us-politics/us-election-tips-and-odds-polls-defy-trumps-comeback-narrative-but-will-the-market-react-030920-171.html)
|
||||||
|
- [Betting Markets Swing Toward Trump, Forecasting Tightening Race](https://www.forbes.com/sites/jackbrewster/2020/09/02/betting-markets-swing-toward-trump-forecasting-tightening-race/#22fafa8b6bfe)
|
||||||
|
- [Biden leads in the polls, but betters are taking a gamble on Trump](https://www.foxnews.com/politics/biden-leads-polls-betters-gamble-trump)
|
||||||
|
- [UK Bookmaker Betfair Shortens Joe Biden 2020 Odds After Bettor Wagers $67K](https://www.casino.org/news/uk-bookmaker-betfair-shortens-joe-biden-2020-odds/)
|
||||||
|
- [Avoid The Monster Trump Gamble - The Fundamental Numbers Haven’t Changed](http://politicalgambler.com/avoid-the-monster-trump-gamble-the-fundamental-numbers-havent-changed/)
|
||||||
|
|
||||||
|
Red Cross and Red Crescent societies have been trying out forecast based financing. The idea is to create forecasts and early warning indicators for some negative outcome, such as a flood, using weather forecasts, satellite imagery, climate models, etc, and then release funds automatically if the forecast reaches a given threshold, allowing the funds to be put to work before the disaster happens in a more automatic, fast and efficient manner. Goals and modus operandi might resonate with the Effective Altruism community:
|
||||||
|
> "In the precious window of time between a forecast and a potential disaster, FbF releases resources to take early action. Ultimately, we hope this early action will be more **effective at reducing suffering**, compared to waiting until the disaster happens and then doing only disaster response. For example, in Bangladesh, people who received a forecast-based cash transfer were less malnourished during a flood in 2017." (bold not mine)
|
||||||
|
- Here is the "what can go wrong" section of their [slick yet difficult to navigate webpage](https://www.forecast-based-financing.org/our-projects/what-can-go-wrong/), and an introductory [video](https://www.youtube.com/watch?v=FcuKUBihHVI).
|
||||||
|
|
||||||
|
[Prediction Markets' Time Has Come, but They Aren't Ready for It](https://www.coindesk.com/prediction-markets-election). Prediction markets could have been useful for predicting the spread of the pandemic (see: coronainformationmarkets.com), or for informing presidential election consequences (see: Hypermind above), but their relatively small size makes them less informative. Blockchain based prediction technologies, like Augur, Gnosis or Omen could have helped bypass US regulatory hurdles (which ban many kinds of gambling), but the recent increase in transaction fees means that "everything below a $1,000 bet is basically economically unfeasible"
|
||||||
|
|
||||||
|
Floods in India and Bangladesh:
|
||||||
|
- [Time to develop a reliable flood forecasting model (for Bangladesh)](https://www.thedailystar.net/opinion/news/time-develop-reliable-flood-forecasting-model-1952061)
|
||||||
|
> This year, flood started somewhat earlier than usual. The Brahmaputra water crossed the danger level (DL) on June 28, subsided after a week, and then crossed the DL again on July 13 and continued for 26 days. It inundated over 30 percent of the country
|
||||||
|
- [Google's AI Flood Forecasting Initiative now expanded to all parts of India](https://www.timesnownews.com/technology-science/article/googles-ai-flood-forecasting-initiative-now-expanded-to-all-parts-of-india-heres-how-it-helps/646340); [Google bolsters its A.I.-enabled flood alerts for India and Bangladesh](https://fortune.com/2020/09/01/google-ai-flood-alerts-india-bangladesh/)
|
||||||
|
> “One assumption that was presumed to be true in hydrology is that you cannot generalize across water basins,” Nevo said. “Well, it’s not true, as it turns out.” He said Google’s A.I.-based forecasting model has performed better on watersheds it has never encountered before in training than classical hydrologic models that were designed specifically for that river basin.
|
||||||
|
|
||||||
|
[The many tribes of 2020 election worriers: An ethnographic report](https://www.washingtonpost.com/outlook/2020/09/01/many-tribes-2020-election-worriers-an-ethnographic-report/) by the Washington Post.
|
||||||
|
|
||||||
|
Electricity time series demand and supply forecasting startup [raises $8 million](https://news.crunchbase.com/news/myst-ai-closes-6m-series-a-to-forecast-energy-demand-supply/). I keep seeing this kind of announcement; doing forecasting well in an underforecasted domain seems to be somewhat profitable right now, and it's not like there is an absence of domains to which forecasting can be applied. This might be a good idea for an earning-to-give startup.
|
||||||
|
|
||||||
|
[NSF and NASA partner to address space weather research and forecasting](https://www.nsf.gov/news/special_reports/announcements/090120.01.jsp). Together, NSF and NASA are investing over $17 million into six, three-year awards, each of which contributes to key research that can expand the nation's space weather prediction capabilities.
|
||||||
|
|
||||||
|
In its monthly report, OPEC said it expects the pandemic to reduce demand by 9.5 million barrels a day, forecasting a fall in demand of 9.5% from last year, [reports the Wall Street Journal](https://www.wsj.com/articles/opec-deepens-forecast-for-decline-in-global-oil-demand-11600083622)
|
||||||
|
|
||||||
|
Some [criticism](https://www.theblockcrypto.com/post/76453/arca-gnosis-defi-project-call) of Gnosis, a decentralized prediction markets startup, by early investors who want to cash out. [Here](https://www.ar.ca/blog/understanding-arcas-request-for-change-at-gnosis) is a blog post by said early investors; they claim that "Gnosis took out what was in effect a 3+ year interest-free loan from token holders and failed to deliver the products laid out in its fundraising whitepaper, quintupled the size of its balance sheet due simply to positive price fluctuations in ETH, and then launched products that accrue value only to Gnosis management."
|
||||||
|
|
||||||
|
[What a study of video games can tell us about being better decision makers](https://qz.com/1899461/how-individuals-and-companies-can-get-better-at-making-decisions/) ($), a frustratingly well-paywalled, yet exhaustive, complete and informative overview of the IARPA's FOCUS tournament:
|
||||||
|
> To study what makes someone good at thinking about counterfactuals, the intelligence community decided to study the ability to forecast the outcomes of simulations. A simulation is a computer program that can be run again and again, under different conditions: essentially, rerunning history. In a simulated world, the researchers could know the effect a particular decision or intervention would have. They would show teams of analysts the outcome of one run of the simulation and then ask them to predict what would have happened if some key variable had been changed.
|
||||||
|
|
||||||
|
## Negative Examples
|
||||||
|
|
||||||
|
[Why Donald Trump Isn’t A Real Candidate, In One Chart](https://fivethirtyeight.com/features/why-donald-trump-isnt-a-real-candidate-in-one-chart/), wrote 538 in 2015.
|
||||||
|
> For this reason alone, Trump has a better chance of cameoing in another “Home Alone” movie with Macaulay Culkin — or playing in the NBA Finals — than winning the Republican nomination.
|
||||||
|
|
||||||
|
[Travel CFOs Hesitant on Forecasts as Pandemic Fogs Outlook](https://www.airbus.com/newsroom/press-releases/en/2020/09/airbus-reveals-new-zeroemission-concept-aircraft.html), reports the Wall Street Journal.
|
||||||
|
> "We're basically prevented from saying the word 'forecast' right now because whatever we forecast...it's wrong," said Shannon Okinaka, chief financial officer at Hawaiian Airlines. "So we've started to use the word 'planning scenarios' or 'planning assumptions.'"
|
||||||
|
|
||||||
|
## Long Content
|
||||||
|
|
||||||
|
Andrew Gelman et al. release [Information, incentives, and goals in election forecasts](http://www.stat.columbia.edu/~gelman/research/unpublished/forecast_incentives3.pdf).
|
||||||
|
- Neither The Economist's model nor 538's are fully Bayesian. In particular, they are not martingales, that is, their current probability is not the expected value of their future probability.
|
||||||
|
> campaign polls are more stable than every before,and even the relatively small swings that do appear can largely be attributed to differential nonresponse
|
||||||
|
|
||||||
|
> Regarding predictions for 2020, the creator of the Fivethirtyeight forecast writes, "we think it’s appropriate to make fairly conservative choices *especially* when it comes to the tails of your distributions. Historically this has led 538 to well-calibrated forecasts (our 20%s really mean 20%)" (Silver, 2020b). But conservative prediction corresponds can produce a too-wide interval, one that plays it safe by including extra uncertainty. In other words, conservative forecasts should lead to underconfidence: intervals whose coverage is greater than advertised. And, indeed, according to the calibration plot shown by Boice and Wezerek (2019) of Fivethirtyeight’s political forecasts, in this domain 20% for them really means 14%, and 80% really means 88%.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
[The Literary Digest Poll of 1936](https://en.wikipedia.org/wiki/The_Literary_Digest#Presidential_poll). A poll so bad that it destroyed the magazine.
|
||||||
|
- Compare the Literary Digest and Gallup polls of 1936 with The New York Times's [model of 2016](https://www.nytimes.com/interactive/2016/upshot/presidential-polls-forecast.html) and [538's 2016 forecast](https://projects.fivethirtyeight.com/2016-election-forecast/#plus), respectively.
|
||||||
|
|
||||||
|
> In retrospect, the polling techniques employed by the magazine were to blame. Although it had polled ten million individuals (of whom 2.27 million responded, an astronomical total for any opinion poll),[5] it had surveyed its own readers first, a group with disposable incomes well above the national average of the time (shown in part by their ability to afford a magazine subscription during the depths of the Great Depression), and those two other readily available lists, those of registered automobile owners and that of telephone users, both of which were also wealthier than the average American at the time.
|
||||||
|
|
||||||
|
> Research published in 1972 and 1988 concluded that as expected this sampling bias was a factor, but non-response bias was the primary source of the error - that is, people who disliked Roosevelt had strong feelings and were more willing to take the time to mail back a response.
|
||||||
|
|
||||||
|
> George Gallup's American Institute of Public Opinion achieved national recognition by correctly predicting the result of the 1936 election, while Gallup also correctly predicted the (quite different) results of the Literary Digest poll to within 1.1%, using a much smaller sample size of just 50,000.[5] Gallup's final poll before the election also predicted Roosevelt would receive 56% of the popular vote: the official tally gave Roosevelt 60.8%.
|
||||||
|
|
||||||
|
> This debacle led to a considerable refinement of public opinion polling techniques, and later came to be regarded as ushering in the era of modern scientific public opinion research.
|
||||||
|
|
||||||
|
[Feynman in 1985](https://infoproc.blogspot.com/2020/09/feynman-on-ai.html), answering questions about whether machines will ever be more intelligent than humans.
|
||||||
|
|
||||||
|
[Why Most Published Research Findings Are False](https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.0020124), back from 2005. The abstract reads:
|
||||||
|
> There is increasing concern that most current published research findings are false. The probability that a research claim is true may depend on study power and bias, the number of other studies on the same question, and, importantly, the ratio of true to no relationships among the relationships probed in each scientific field. In this framework, a research finding is less likely to be true when the studies conducted in a field are smaller; when effect sizes are smaller; when there is a greater number and lesser preselection of tested relationships; where there is greater flexibility in designs, definitions, outcomes, and analytical modes; when there is greater financial and other interest and prejudice; and when more teams are involved in a scientific field in chase of statistical significance. Simulations show that for most study designs and settings, it is more likely for a research claim to be false than true. Moreover, for many current scientific fields, claimed research findings may often be simply accurate measures of the prevailing bias. In this essay, I discuss the implications of these problems for the conduct and interpretation of research.
|
||||||
|
|
||||||
|
[Reference class forecasting](https://en.wikipedia.org/wiki/Reference_class_forecasting). Reference class forecasting or comparison class forecasting is a method of predicting the future by looking at similar past situations and their outcomes. The theories behind reference class forecasting were developed by Daniel Kahneman and Amos Tversky. The theoretical work helped Kahneman win the Nobel Prize in Economics.Reference class forecasting is so named as it predicts the outcome of a planned action based on actual outcomes in a reference class of similar actions to that being forecast.
|
||||||
|
|
||||||
|
[Reference class problem](https://en.wikipedia.org/wiki/Reference_class_problem)
|
||||||
|
> In statistics, the reference class problem is the problem of deciding what class to use when calculating the probability applicable to a particular case.
|
||||||
|
> For example, to estimate the probability of an aircraft crashing, we could refer to the frequency of crashes among various different sets of aircraft: all aircraft, this make of aircraft, aircraft flown by this company in the last ten years, etc. In this example, the aircraft for which we wish to calculate the probability of a crash is a member of many different classes, in which the frequency of crashes differs. It is not obvious which class we should refer to for this aircraft. In general, any case is a member of very many classes among which the frequency of the attribute of interest differs. The reference class problem discusses which class is the most appropriate to use.
|
||||||
|
- See also some thoughts on this [here](https://www.lesswrong.com/posts/iyRpsScBa6y4rduEt/model-combination-and-adjustment)
|
||||||
|
|
||||||
|
[The Base Rate Book](https://research-doc.credit-suisse.com/docView?language=ENG&format=PDF&source_id=csplusresearchcp&document_id=1065113751&serialid=Z1zrAAt3OJhElh4iwIYc9JHmliTCIARGu75f0b5s4bc%3D) by Credit Suisse.
|
||||||
|
> This book is the first comprehensive repository for base rates of corporate results. It examines sales growth, gross profitability, operating leverage, operating profit margin, earnings growth, and cash flow return on investment. It also examines stocks that have declined or risen sharply and their subsequent price performance.
|
||||||
|
> We show how to thoughtfully combine the inside and outside views.
|
||||||
|
> The analysis provides insight into the rate of regression toward the mean and the mean to which results regress.
|
||||||
|
|
||||||
|
## Hard To Categorize
|
||||||
|
|
||||||
|
[Improving decisions with market information: an experiment on corporate prediction markets](https://link.springer.com/article/10.1007/s10683-020-09654-y) ([sci-hub](https://sci-hub.se/https://link.springer.com/article/10.1007/s10683-020-09654-y); [archive link](https://web.archive.org/web/20200927114741/https://sci-hub.se/https://link.springer.com/article/10.1007/s10683-020-09654-y))
|
||||||
|
> We conduct a lab experiment to investigate an important corporate prediction market setting: A manager needs information about the state of a project, which workers have, in order to make a state-dependent decision. Workers can potentially reveal this information by trading in a corporate prediction market. We test two different market designs to determine which provides more information to the manager and leads to better decisions. We also investigate the effect of top-down advice from the market designer to participants on how the prediction market is intended to function. Our results show that the theoretically superior market design performs worse in the lab—in terms of manager decisions—without top-down advice. With advice, manager decisions improve and both market designs perform similarly well, although the theoretically superior market design features less mis-pricing. We provide a behavioral explanation for the failure of the theoretical predictions and discuss implications for corporate prediction markets in the field.
|
||||||
|
|
||||||
|
The nonprofit Ought organized a [forecasting thread on existential risk](https://www.lesswrong.com/posts/6x9rJbx9bmGsxXWEj/forecasting-thread-existential-risk-1), where participants display and discuss their probability distributions for existential risk, and outline some [reflections on a previous forecasting thread on AI timelines](https://www.lesswrong.com/posts/6LJjzTo5xEBui8PqE/reflections-on-ai-timelines-forecasting-thread).
|
||||||
|
|
||||||
|
A [draft report on AI timelines](https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines), [summarized in the comments](https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines?commentId=7d4q79ntst6ryaxWD)
|
||||||
|
|
||||||
|
Gregory Lewis has a series of posts related to forecasting and uncertainty:
|
||||||
|
- [Use resilience, instead of imprecision, to communicate uncertainty](https://forum.effectivealtruism.org/posts/m65R6pAAvd99BNEZL/use-resilience-instead-of-imprecision-to-communicate)
|
||||||
|
- [Challenges in evaluating forecaster performance](https://forum.effectivealtruism.org/posts/JsTpuMecjtaG5KHbb/challenges-in-evaluating-forecaster-performance)
|
||||||
|
- [Take care with notation for uncertain quantities](https://forum.effectivealtruism.org/posts/E3CjL7SEuq958MDR4/take-care-with-notation-for-uncertain-quantities)
|
||||||
|
|
||||||
|
[Estimation of probabilities to get tenure track in academia: baseline and publications during the PhD](https://forum.effectivealtruism.org/posts/3TQTec6FKcMSRBT2T/estimation-of-probabilities-to-get-tenure-track-in-academia).
|
||||||
|
|
||||||
|
[How to think about an uncertain future: lessons from other sectors & mistakes of longtermist EAs](https://forum.effectivealtruism.org/posts/znaZXBY59Ln9SLrne/how-to-think-about-an-uncertain-future-lessons-from-other). The central thesis is:
|
||||||
|
> Expected value calculations, the favoured approach for EA decision making, are all well and good for comparing evidence backed global health charities, but they are often the wrong tool for dealing with situations of high uncertainty, the domain of EA longtermism.
|
||||||
|
|
||||||
|
Discussion by a PredictIt bettor on [how he made money by following Nate Silver's predictions](https://www.reddit.com/r/TheMotte/comments/i6yuis/culture_war_roundup_for_the_week_of_august_10_2020/g1ab8qh/?context=3&sort=best), from r/TheMotte.
|
||||||
|
|
||||||
|
Also on r/TheMotte, on [the promises and deficiencies of prediction markets](https://www.reddit.com/r/TheMotte/comments/iseo9j/culture_war_roundup_for_the_week_of_september_14/g59ydcx/?context=3):
|
||||||
|
> Prediction markets will never be able to predict the unpredictable. Their promise is to be better than all of the available alternatives, by incorporating all available information sources, weighted by experts who are motivated by financial returns.
|
||||||
|
|
||||||
|
> So, you'll never have a perfect prediction of who will win the presidential election, but a good prediction market could provide the best possible guess of who will win the presidential election.
|
||||||
|
|
||||||
|
> To reach that potential, you'd need to clear away the red tape. It would need to be legal to make bets on the market, fees for making transaction need to be low, participants would need faith in the bet adjudication process, and there can't be limits to the amount you can bet. Signs that you'd succeeded would include sophisticated investors making large bets with a narrow bid/ask spread.
|
||||||
|
|
||||||
|
> Unfortunately prediction markets are nowhere close to that ideal today; they're at most "barely legal," bet sizes are limited, transaction fees are high, getting money in or out is clumsy and sketchy, trading volumes are pretty low, and you don't see any hedge funds with "prediction market" desks or strategies. As a result, I put very little stock in political prediction markets today. At best they're populated by dumb money, and at worst they're actively manipulated by campaigns or partisans who are not motivated by direct financial returns.
|
||||||
|
|
||||||
|
[Nate Silver](https://twitter.com/NateSilver538/status/1300449268633866241) on a small twitter thread on prediction markets: "Most of what makes political prediction markets dumb is that people assume they have expertise about election forecasting because they a) follow politics and b) understand "data" and "markets". Without more specific domain knowledge, though, that combo is a recipe for stupidity."
|
||||||
|
- Interestingly, I've recently found out that 538's political predictions are probably [underconfident](https://projects.fivethirtyeight.com/checking-our-work/), i.e., an 80% happens 88% of the time.
|
||||||
|
|
||||||
|
[Deloitte](https://www2.deloitte.com/us/en/pages/about-deloitte/articles/press-releases/a-tale-of-two-holiday-seasons-as-a-k-shaped-recovery-model-emerges-consumer-spending-heavily-bifurcated.html) forecasts US holiday season retail sales (but doesn't provide confidence intervals.)
|
||||||
|
|
||||||
|
[Solar forecast](https://www.nytimes.com/2020/09/15/science/sun-solar-cycle.html). Sun to leave the quietest part of its cycle, but still remain relatively quiet and not produce world-ending coronal mass ejections, the New York Times reports.
|
||||||
|
|
||||||
|
The Foresight Insitute organizes weekly talks; here is one with Samo Burja on [long-lived institutions](https://www.youtube.com/watch?v=6cCcX0xydmk).
|
||||||
|
|
||||||
|
[Some examples of failed technology predictions](https://eandt.theiet.org/content/articles/2020/09/the-eccentric-engineer-the-perils-of-forecasting/).
|
||||||
|
|
||||||
|
Last, but not least, Ozzie Gooen on [Multivariate estimation & the Squiggly language](https://www.lesswrong.com/posts/kTzADPE26xh3dyTEu/multivariate-estimation-and-the-squiggly-language):
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go [there](https://archive.org/) and input the dead link.
|
||||||
|
|
||||||
|
***
|
||||||
|
|
||||||
|
> [Littlewood's law](https://en.wikipedia.org/wiki/Littlewood%27s_law) states that a person can expect to experience events with odds of one in a million (defined by the law as a "miracle") at the rate of about one per month."
|
||||||
|
|
||||||
|
***
|
||||||
66
ea/ForecastingNewsletter/Template.md
Normal file
|
|
@ -0,0 +1,66 @@
|
||||||
|
Whatever happened to forecasting? April 2020
|
||||||
|
============================================
|
||||||
|
|
||||||
|
A forecasting digest with a focus on experimental forecasting. You can sign up [here](https://mailchi.mp/18fccca46f83/forecastingnewsletter). The newsletter itself is experimental, but there will be at least five more iterations.
|
||||||
|
|
||||||
|
## Index
|
||||||
|
- Prediction Markets & Forecasting platforms.
|
||||||
|
- Augur.
|
||||||
|
- PredictIt & Election Betting Odds.
|
||||||
|
- Replication Markets.
|
||||||
|
- Coronavirus Information Markets.
|
||||||
|
- Foretold. (c.o.i).
|
||||||
|
- Metaculus.
|
||||||
|
- Good Judgement Open.
|
||||||
|
- In the News.
|
||||||
|
- Long Content.
|
||||||
|
|
||||||
|
## Prediction Markets & Forecasting platforms.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Augur: [augur.net](https://www.augur.net/)
|
||||||
|
|
||||||
|
Augur is a decentralized prediction market.
|
||||||
|
|
||||||
|
### Predict It & Election Betting Odds: [predictIt.org](https://www.predictit.org/) & [electionBettingOdds.com](http://electionbettingodds.com/)
|
||||||
|
|
||||||
|
PredictIt is a prediction platform restricted to US citizens or those who bother using a VPN.
|
||||||
|
|
||||||
|
In PredictIt, the [world politics](https://www.predictit.org/markets/5/World) section...
|
||||||
|
|
||||||
|
|
||||||
|
[Election Betting Odds](https://electionbettingodds.com/) aggregates PredictIt with other such services for the US presidential elections.
|
||||||
|
|
||||||
|
### Replication Markets: [replicationmarkets.com](https://www.replicationmarkets.com)
|
||||||
|
Replication Markets is a project where volunteer forecasters try to predict whether a given study's results will be replicated with high power. Rewards are monetary, but only given out to the top N forecasters, and markets suffer from sometimes being dull.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Coronavirus Information Markets: [coronainformationmarkets.com](https://coronainformationmarkets.com/)
|
||||||
|
For those who want to put their money where their mouth is, there is now a prediction market for coronavirus related information. The number of questions is small, and the current trading volume started at $8000, but may increase. Another similar platform is [waves.exchange/prediction](https://waves.exchange/prediction), which seems to be just a wallet to which a prediction market has been grafted on.
|
||||||
|
|
||||||
|
Unfortunately, I couldn't make a transaction in these markets with ~30 mins; the time needed to be included in an ethereum block is longer and I may have been too stingy with my gas fee.
|
||||||
|
|
||||||
|
### Foretold: [foretold.io](https://www.foretold.io/) (c.o.i)
|
||||||
|
|
||||||
|
Foretold is an forecasting platform which has experimentation and exploration of forecasting methods in mind. They bring us:
|
||||||
|
|
||||||
|
- A new [distribution builder](https://www.highlyspeculativeestimates.com/dist-builder) to visualize and create probability distributions.
|
||||||
|
|
||||||
|
### Metaculus: [metaculus.com](https://www.metaculus.com/)
|
||||||
|
|
||||||
|
Metaculus is a forecasting platform with an active community and lots of interesting questions.
|
||||||
|
|
||||||
|
### /(Good Judgement?[^]*)|(Superforecast(ing|er))/gi
|
||||||
|
|
||||||
|
Good Judgement Inc. is the organization which grew out of Tetlock's research on forecasting, and out of the Good Judgement Project, which won the [IARPA ACE forecasting competition](https://en.wikipedia.org/wiki/Aggregative_Contingent_Estimation_(ACE)_Program), and resulted in the research covered in the *Superforecasting* book.
|
||||||
|
|
||||||
|
Good Judgement Inc. also organizes the Good Judgement Open [gjopen.com](https://www.gjopen.com/), a forecasting platform open to all, with a focus on serious geopolitical questions. They structure their questions in challenges.
|
||||||
|
|
||||||
|
## In the News
|
||||||
|
|
||||||
|
## Grab bag
|
||||||
|
|
||||||
|
## Long Content
|
||||||
|
|
||||||
{kind=link}
|
After Width: | Height: | Size: 82 KiB |
BIN
ea/GalaxyBrainTemplate.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.2 MiB |
BIN
ea/HarryPotterCharactersTemplate.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.2 MiB |
BIN
ea/IfCauseXsWereHarryPotterCharacters.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 MiB |
BIN
ea/InaccessibleInformation.pdf
Normal file
BIN
ea/LaborCapitalAndTheOptimalGrowthOfSocialMovementsMay5_2021.pdf
Normal file
BIN
ea/LaborCapitalOptimalGrowth.pdf
Normal file
6
ea/LitanyOfLight.md
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
# The Litany of Light.
|
||||||
|
|
||||||
|
In brightest day, in blackest night,
|
||||||
|
we strive to make the world more right;
|
||||||
|
let us deploy insight and might
|
||||||
|
to reduce plight and multiply delight.
|
||||||
6
ea/LitanyOfLight.md~
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
# The Litany of Light.
|
||||||
|
|
||||||
|
In brightest day, in blackest night,
|
||||||
|
we strive to make the world more right;
|
||||||
|
let us deploy insight and might
|
||||||
|
to reduce plight and multiply delight.
|
||||||
BIN
ea/MH-EA-How.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 63 KiB |
BIN
ea/MH-For-Whom.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 44 KiB |
BIN
ea/MH-Why.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 21 KiB |