254 lines
25 KiB
Markdown
Executable File
254 lines
25 KiB
Markdown
Executable File
Predicting the Value of Small Altruistic Projects: A Proof of Concept Experiment.
|
||
==============
|
||
|
||
**tl;dr^2:** We could continuously forecast the value of small projects, choose the most valuable and informative ones, carry them out, and then make better forecasts and choose better projects with each round. I have a small experiment which does that. If this sounds like something you might want to participate in, sign up [here](https://docs.google.com/forms/d/e/1FAIpQLSdNsFton2XYf9-AlXePTdBNCRC2pVl0zNX541dWgjmbZv6CXA/viewform).
|
||
|
||
**tl;dr**: I conducted an experiment to forecast the impact of small altruistic projects. Forecasters attempted to predict upvotes, because I initially thought that they would correlate more robustly with impact, and because upvotes are appealingly simple as a metric, and thus easy to forecast. Forecasters proved somewhat able to produce predictions which discriminated between projects with more upvotes, and projects with less upvotes, but were generally too optimistic. And, in hindsight, upvotes aren't that great a metric for impact, so, going forward, I'd probably have forecasters predict a [scoring rubric](https://forum.effectivealtruism.org/posts/GseREh8MEEuLCZayf/nunosempere-s-shortform?commentId=sYxbbjWhbP3hFfTb7), i.e., an aggregate of different metrics, graded by more than one judge. Nonetheless, I think that the forecasting pipeline in this experiment is interesting, and might help the EA community more systematically identify valuable small projects to carry out, in contrast with today, where individuals or EA groups carry out projects more idiosyncratically. Because the experiment was very underpowered, I'm looking for volunteer participants to expand it.
|
||
|
||
## Index
|
||
|
||
* Introduction
|
||
* Experiment design
|
||
* Projects carried out, predictions and their results
|
||
* Observations about participants
|
||
* Upvotes maybe not a good measure of impact
|
||
* Going forward
|
||
|
||
## Introduction
|
||
|
||
I report the outcomes of a forecasting experiment in which 10 forecasters predicted the value of 20 potential altruistic projects. I then carried out 8, of which I made 5 public–an additional project developed into my Summer Research Fellowship at FHI.
|
||
|
||
Overall, the experiment was underpowered (n=10 forecasters, n=5 published projects, n=135 predictions (246 including bots, more on that below)). Nonetheless, I think that the idea is promising, and I elaborate on some interesting properties of the prediction setup, the problems in the EA community it may solve, and why I'm personally excited about it. I'm considering scaling it up somewhat; thoughts and ideas are welcome.
|
||
|
||
If you'd be interested in participating in a scaled-up version of this experiment or in later forecasting experiments, fill out [this form](https://docs.google.com/forms/d/e/1FAIpQLSdNsFton2XYf9-AlXePTdBNCRC2pVl0zNX541dWgjmbZv6CXA/viewform).
|
||
|
||
Previous literature on the EA forum:
|
||
|
||
* [Request for comments: EA Projects evaluation platform](https://forum.effectivealtruism.org/posts/PagT8Fg6HZu6KjHDb/request-for-comments-ea-projects-evaluation-platform). In particular, from the comments section:
|
||
_The empirical reality of the EA project landscape seems to be that EAs keep stumbling on the same project ideas over and over with little awareness of what has been proposed or attempted in the past. If this post goes like the typical project proposal post, nothing will come of it, it will soon be forgotten, and 6 months later someone will independently come up with a similar idea and write a similar post (which will meet a similar fate)._
|
||
* [EA is vetting constrained](https://forum.effectivealtruism.org/posts/G2Pfpkcwv3bJNF8o9/ea-is-vetting-constrained)
|
||
* [Amplifying generalist research via forecasting](https://forum.effectivealtruism.org/posts/ZCZZvhYbsKCRRDTct/part-1-amplifying-generalist-research-via-forecasting-models)
|
||
* [What to do with people?](https://forum.effectivealtruism.org/posts/oNY76m8DDWFiLo7nH/what-to-do-with-people), which proposes a hierarchical networked structure. In contrast, the structure I propose in the latter sections is modular and decentralized.
|
||
* [Prediction Augmented Evaluation Systems](https://www.lesswrong.com/posts/kMmNdHpQPcnJgnAQF/prediction-augmented-evaluation-systems), which proposes the general idea of which this experiment is an example. Holomanga also had a similar idea.
|
||
|
||
Thanks to Andis Draguns, Jacob Lagerros, Ray, Ozzie Gooen, Misha Yagudin, Cadillion, Gavin Leech, Datscilly and Holomanga for taking part in this project as forecasters; congratulations to Gavin Leech for overall being the most accurate forecaster. Thanks to Ozzie Gooen et. al. for creating foretold, to Jaime Sevilla for providing feedback on ideas, and to Jacob Lagerros for encouragement and funding. Thanks to various people on the EA Editing and Review Facebook group for feedback.
|
||
|
||
## Experiment design.
|
||
|
||
The setup of the experiment was as follows:
|
||
|
||
* I produced a list of potential altruistic projects, by distilling other lists of projects, lists of lists, research agendas, and by coming up with projects myself. This original list had 75 potential projects. Since then, I've kept accumulating projects and project lists.
|
||
* From these original 75, I selected 26 on the basis of being a good personal fit, particularly promising, short in duration, and in general suitable for this experiment.
|
||
* A more senior friend gave feedback on the original list of ideas, after which I pruned the list to 20.
|
||
* Using the infrastructure built by foretold.io, I created a community to predict the value of each project, operationalized as how many upvotes it would gather on the Effective Altruism Forum or on LessWrong (more on that below).
|
||
* Monetary rewards were scaled to how much forecasters beat a prior I created, individually and as a team.
|
||
* After the value of the projects was predicted, I intended to choose the top two, two chosen randomly, and two chosen however I wished, and implement them.
|
||
|
||
This setup can be understood as having two steps, similar to those in [_Babble and Prune_](https://www.lesswrong.com/s/pC6DYFLPMTCbEwH8W) (a sequence on LW):
|
||
|
||
* Babble. Use a weak and local filter to (perhaps even randomly) generate a lot of possibilities.
|
||
* Prune. Use a strong and global filter to test for the best, or at least a satisfactory, choice.
|
||
|
||
The forecasts for this experiment were made in [foretold](https://www.foretold.io/), a prediction platform geared towards performing experiments, which made this experiment easier. In particular, it was more convenient than sharing thoughts using Google Docs, or Google Sheets. Besides reducing the hassle in carrying out the experiment, it is possible that foretold may have acted as a tool for thought, such that it existing may make it easier to come up with experiments like this, in the same way that Guesstimate makes the thought "I'll conduct a Monte Carlo simulation to quantify my uncertainty" easier to think.
|
||
|
||
**Scoring rule**
|
||
|
||
(Some familiarity with scoring rules is assumed in this section. See: [Brier score](https://en.wikipedia.org/wiki/Brier_score) and [Proper scoring rule](https://en.wikipedia.org/wiki/Scoring_rule#Proper_scoring_rules))
|
||
|
||
Forecasters labored under a collaborative scoring rule I created, inspired by [Shapley Values](https://forum.effectivealtruism.org/posts/3NYDwGvDbhwenpDHb/shapley-values-reloaded-philantropic-coordination-theory-and), such that I first produced a prior by instantiating different perspectives (see below), and each forecaster was rewarded in proportion to:
|
||
|
||
1/2 \* (The information they added over that prior, excluding other forecasters) + 1/2 \* (The information other forecasters added over that prior).
|
||
|
||
Note that this scoring rule is both roughly proper and solves all incentive problems in [Incentive Problems in Current Forecasting Tournaments](https://forum.effectivealtruism.org/posts/ztmBA8v6KvGChxw92/incentive-problems-with-current-forecasting-competitions).
|
||
|
||
In this particular case, "information added" is defined in terms of the [Kullback–Leibler divergence](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) between a prediction and the resolution. However, the spirit might be easier to understand (and compute) in terms of the Brier score. That is, the scoring rule could have been
|
||
|
||
1/2 \* (The forecaster's Brier score - the Brier score of the prior) + 1/2 \* (The aggregate without the forecaster's Brier score - the Brier score of the prior).
|
||
|
||
In practice, when converting the score into a monetary reward, a constant would have to be added so that the reward is never less than $0, but I didn't think about that beforehand.
|
||
|
||
I also had a payout for insightful comments, such that the nth most upvoted comment would get $36\*(2/3)^(n-1). Total payouts were $259 (or an average payout of $25.9 per forecaster), of which around $100 were given out for comments, which was a larger proportion than I expected. One forecaster didn’t receive a payout because he didn’t make a prediction on any project which was then carried out.
|
||
|
||
## Projects carried out, predictions and their results
|
||
|
||
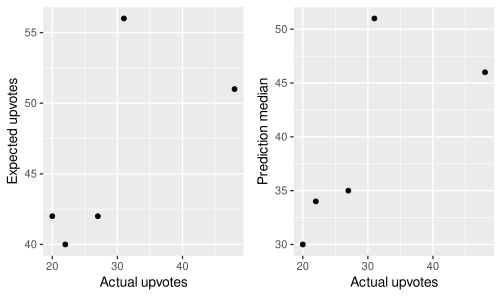
Note that the projects were _not_ chosen so as to maximize impact, but rather as to maximize information about whether their value could be predicted.
|
||
|
||
|
||
|
||
We observe that:
|
||
|
||
1. The experiment is underpowered; there are only five projects, hardly enough to be confident in conclusions
|
||
2. Predictions do show some ability to discriminate between more valuable and not so valuable projects.
|
||
3. If one looks at the distributions, they broadly have a similar shape. This can be explained by the use of bots to generate a prior (more of which in the next section), which made the aggregate sticky.
|
||
4. Predictions turned out to be over-optimistic. This can also partially be explained by the choice of a sticky prior, which used an out of distribution historical prior (before the start of the experiment I’d only written up posts which were chosen because I thought they were likely to be particularly valuable, as opposed to random posts for this experiment.) Subjectively, however, forecasters didn’t correct enough for that.
|
||
|
||
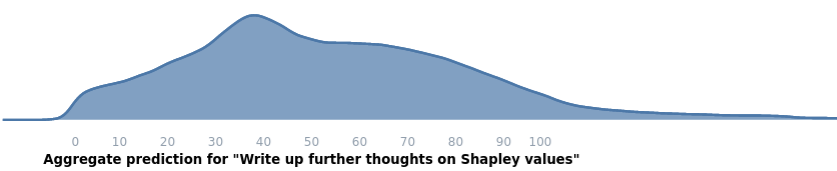
**Project 1: Write up further thoughts on Shapley values.**
|
||
|
||
Output: [Here](https://forum.effectivealtruism.org/posts/3NYDwGvDbhwenpDHb/shapley-values-reloaded-philantropic-coordination-theory-and) are the further thoughts. I provide some further thoughts after [my first post on Shapley values](https://forum.effectivealtruism.org/posts/XHZJ9i7QBtAJZ6byW/shapley-values-better-than-counterfactuals), including a procedure for allowing two philanthropic funders with slightly different values to share the burden of funding interventions they value differently, and an impossibility theorem for value attribution.
|
||
|
||
Outcome: Nothing much happened, but I do keep the idea of Shapley values in my head and occasionally use it (e.g., when thinking about designing better incentives for forecasters.)
|
||
|
||
Predictions:
|
||
|
||
* Expected value: 56
|
||
* Median: 51
|
||
* Highest likelihood value: 38
|
||
* Centered 50% confidence interval: 33 to 74
|
||
* Centered 95% confidence interval: 11 to 111
|
||
|
||
|
||
|
||
Actual upvotes after one month: 31
|
||
|
||
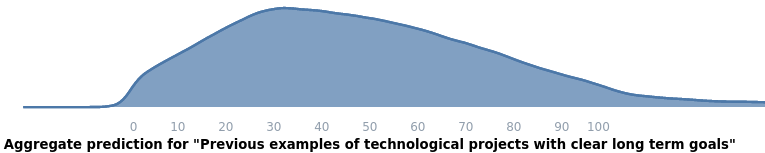
**Project 2: Identify previous examples of technological projects with clear long-term goals, and then produce estimates of the time required to achieve those goals to varying degrees.**
|
||
|
||
Output: [Here](https://www.lesswrong.com/posts/yWmmYLCJft7u7XL5o/some-examples-of-technology-timelines) is a LW post about this. This then gave me intuitions about technological progress, but led me to realize that what I actually wanted was something more systematic, so I ended up writing a post on [A prior for technological discontinuities](https://www.lesswrong.com/posts/FaCqw2x59ZFhMXJr9/a-prior-for-technological-discontinuities), which I think was significantly more valuable.
|
||
|
||
Outcome: Better personal intuitions about technological progress, a rough prior for technological discontinuities.
|
||
|
||
Predictions:
|
||
|
||
* Expected upvotes: 51
|
||
* Median: 46
|
||
* Highest likelihood value: 32
|
||
* Centered 50% confidence interval: 28 to 68
|
||
* Centered 95% confidence interval: 9 to 106
|
||
|
||
|
||
|
||
Actual upvotes after one month: 20 for the [first post](https://www.lesswrong.com/posts/yWmmYLCJft7u7XL5o/some-examples-of-technology-timelines), 49 for the [second one](https://www.lesswrong.com/posts/FaCqw2x59ZFhMXJr9/a-prior-for-technological-discontinuities). I'm taking 49 as the resolution.
|
||
|
||
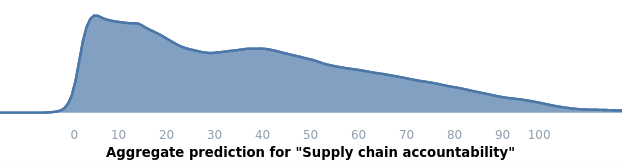
**Project 3: Investigate international supply chain accountability as cause X.**
|
||
|
||
Output: [Here](https://forum.effectivealtruism.org/posts/ME4zE34KBSYnt6hGp/new-top-ea-cause-international-supply-chain-accountability) is an EA forum post.
|
||
|
||
Outcome: Unfortunately I posted this on April Fools' day together with other ["New Top EA Cause Area"](https://forum.effectivealtruism.org/posts/Nc5Ep9iFjbLPK87HT/april-fool-s-day-is-very-serious-business) posts, and it didn't get taken too seriously. But I do still think that this cause could potentially use many millions of dollars per year from the EA community.
|
||
|
||
Predictions:
|
||
|
||
* Expected upvotes: 40
|
||
* Median: 34
|
||
* Highest likelihood value: 5
|
||
* Centered 50% confidence interval: 15 to 57
|
||
* Centered 95% confidence interval: 4 to 91
|
||
|
||
|
||
|
||
Actual upvotes after one month: 22
|
||
|
||
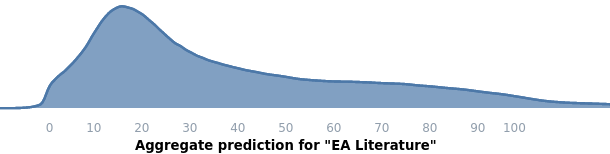
**Project 4: Look into EA literature.**
|
||
|
||
Output: I looked into some past examples of literature which might have influenced the world in some way, available as a comment [here](https://forum.effectivealtruism.org/posts/Bc8J5P938BmzBuL9Y/when-can-writing-fiction-change-the-world?commentId=RnEpvpozD5tEEsM9b). Originally this was part of a longer piece, which I ended up not posting.
|
||
|
||
Outcome: I became marginally more enlightened about the role of literature in history.
|
||
|
||
Predictions:
|
||
|
||
* Expected upvotes: 42
|
||
* Median: 30
|
||
* Highest likelihood value: 15
|
||
* Centered 50% confidence interval: 17 to 60
|
||
* Centered 95% confidence interval: 6 to 102
|
||
|
||
|
||
|
||
Actual upvotes after one month: 20
|
||
|
||
**Project 5: Review two books on survey making.**
|
||
|
||
Output: [Here](https://forum.effectivealtruism.org/posts/DCcciuLxRveSkBng2/a-review-of-two-books-on-survey-making) is the review.
|
||
|
||
Outcome: It spread the knowledge among some people that I was available to ask questions about survey-making. In particular, some people later reached out to me for help with surveys for their projects, and my help might have been valuable.
|
||
|
||
Predictions:
|
||
|
||
* Expected upvotes: 42
|
||
* Median: 35, Highest likelihood value: 17
|
||
* Centered 50% confidence interval: 19 to 59
|
||
* Centered 95% confidence interval: 7 to 92
|
||
|
||

|
||
|
||
Actual upvotes after one month: 27
|
||
|
||
**Other projects**
|
||
|
||
There were three further projects which I carried out but which for various reasons didn't end up posting publicly: Some historical research was too sensitive, and I made two suggestions privately by email rather than by writing a post publicly.
|
||
|
||
A further idea was my proposal for my Summer Research Fellowship at FHI, though it changed upon execution. The predictions for that project were:
|
||
|
||
* Expected upvotes: 50
|
||
* Median: 45, Highest likelihood value: 21
|
||
* Centered 50% confidence interval: 24 to 70
|
||
* Centered 95% confidence interval: 10 to 103
|
||
|
||

|
||
|
||
I take these data-points as further evidence that this setup is interesting or worth it; arguably a major take-away for this project is “a fairly simple forecasting system is able to produce a project which gets accepted to the FHI summer fellowship.” Because the program got ~300 [applications](https://forum.effectivealtruism.org/posts/EPGdwe6vsCY7A9HPa/review-of-fhi-s-summer-research-fellowship-2020), but only 27 participants were accepted, this puts this forecasting setup on the top 9% of applicants in terms of some fuzzy “optimization power” (though this is a simplification, because the project proposal was probably one of many factors.)
|
||
|
||
## Observations about participants
|
||
|
||
The value which the forecasters provided was distributed like a power-law, with the top few forecasters providing most of the value. For example, the most upvoted forecaster received 43% of upvotes. Comments by forecasters were fairly valuable, for example, some pointed to previous similar efforts, to possible research directions, or gave caveats and warnings.
|
||
|
||
I also recruited some participants from the LessWrong Slack group. One of them, who is a regular there and had made valuable comments in the past, turned out to behave like a troll and made somewhat unpleasant or unproductive comments (e.g., writing “I was looking at a tree outside and this is what it said” as a comment rationale), which in the end I decided not to censor. They also blatantly attempted to manipulate the market by inputting high predictions for the projects they personally wanted to be carried out, rather than making honest predictions.
|
||
|
||
As well as giving my all-things-considered forecast, I also forecasted using different perspectives, using foretold's bot functionality, and this defined a prior against which forecasters were compared. I created bots for the following perspectives:
|
||
|
||
* The Historical Extrapolator. Just taking the upvote distribution of my previous posts. In hindsight, this was too high, and I would have done better considering the distribution of all posts, or of all posts with authors with more than three posts, etc.
|
||
* The Unrepentant Insider. A sometimes optimistic inside view.
|
||
* The Bent Cynic. Is very cynical; channels depression.
|
||
* The Unimpressed Augur. Foresees middling success.
|
||
* The Equalizer. Uniform distribution between 1 and 100.
|
||
* The All-Father. An aggregate which weights the above equally.
|
||
|
||
It was disappointing, but not surprising, to see that the Bent Cynic, the part of me which I associate with being depressed, had the best score not only among all perspectives, but also among all participants. My interpretation is that this perspective is able to see through social fictions and sympathetic lies, which improves its accuracy. But other explanations are possible, such as forecasters giving too much weight to an out of distribution historical base rate.
|
||
|
||
Additionally, the presence of a "historical extrapolator", "unrepentant insider" and "uniform distribution" bots made the aggregate predictions be overly optimistic, and the presence of many bots made the aggregate slightly sticky; i.e., each individual prediction couldn’t change the aggregate all that much.
|
||
|
||
## Upvotes maybe not a good measure of impact
|
||
|
||
Initially, I thought that forecasting popularity on the Forum or LW would be a good enough proxy for the projects’ value, if perhaps far from perfect. I'd ideally want something like an efficient market in impact certificates populated by trustworthy altruists instead.
|
||
|
||
[Here](https://forum.effectivealtruism.org/posts/GseREh8MEEuLCZayf/nunosempere-s-shortform?commentId=kLuhtmQRZBJpcaHhH) are some factors that might be reducing the correlation between upvotes and value, based on my own judgement and some light data analysis. Due to those limitations, in addition to forecasts of popularity, I also ended up paying attention to the comments under the forecasts, to whether a project could cause harm, and to personal taste when deciding which projects to carry out.
|
||
|
||
However, despite those limitations, the number of upvotes does discriminate between more and less valuable projects, to a certain extent. For example, I took 25 randomly selected EA forum posts posted during July, and rated them on a 1-10 scale according to how valuable I thought they were, and the correlation between that and upvotes had an R^2 = 0.2715 (subjectively, a small/medium correlation).
|
||
|
||
From where I'm standing now, one could have forecasted a [rubric](https://en.wikipedia.org/wiki/Rubric_(academic)) of measures, possibly decided by a group of trusted judges after the project is completed, in a way similar to what [Charity Entrepreneurship](https://www.lesswrong.com/posts/AZ9WGEJ85fXNp95wh/using-a-spreadsheet-to-make-good-decisions-five-examples) does, or what 80k [used to do](https://80000hours.org/2014/06/how-to-quantify-research-quality/). Alternatively, one could have tried to compare the value of each project to e.g., the value of a QALY, or to a set of previously completed projects (and forecast said value beforehand). Further, in hindsight it would have been more informative to forecast the value of a project per unit of time, rather than the total value.
|
||
|
||
## Going forward.
|
||
|
||
I think that a setup like the above could develop into something more widely useful, though this first proof of concept was very under-powered and maybe not that informative. One reason I'm excited about this is that successive prediction → implementation cycles could each bring their own improvement:
|
||
|
||
* Lessons in forecasting gained from forecasting the value of projects can be used to better forecast the value of projects. This would be both by detecting better forecasters based on their track record, and by giving forecasters more data with which to work. For example, the right historical base-rate could be determined. This would correspond to better "pruning" of babble.
|
||
* Lessons in how valuable projects are (after completing them and seeing how they turn out) may lead one to suggest better projects. This would correspond to better babble.
|
||
* So overall, you can create a loop: Project suggestions → Forecasts → Projects are implemented → Feedback on the EA forum → Better forecasts & better project suggestions.
|
||
|
||
Note that the loop is recursive, but it doesn't necessarily have to keep increasing forever. For example, there might be a ceiling to how good forecasts can be.
|
||
|
||
Further:
|
||
|
||
* Such a process could be left continuously running; there could be a community in foretold always taking suggestions for new projects, always forecasting their value, and always implementing them.
|
||
* One might scale this pretty arbitrarily (though gradually). This experiment starts out pretty small, but I could imagine it generalizing it to one local group, and then to many EA local groups.
|
||
* On the ambitious side, I could imagine this just becoming a mainstream way to allocate projects to idle altruists.
|
||
* Eventually, with enough data in one place, one might more systematically learn what kinds of small projects are valuable, and have that knowledge in one place so that it can be made actionable, rather than distributed across the EA community as it is now. One might even be able to pose the problem as a [multi-armed bandit problem](https://en.wikipedia.org/wiki/Multi-armed_bandit), where different types of projects are the different arms of the bandit.
|
||
|
||
Overall, if it is the case that EA is [vetting constrained](https://forum.effectivealtruism.org/posts/G2Pfpkcwv3bJNF8o9/ea-is-vetting-constrained), a prediction pipeline like the one in this experiment could be created to solve this problem by identifying both projects with high expected value and individuals who can carry them out. Note that many kinds of people could be used, not just forecasters:
|
||
|
||
* People to suggest projects.
|
||
* People to come up with a rubric which captures the factors which make a project valuable.
|
||
* People to check that projects do no harm.
|
||
* People to share intuitions about whether projects would be valuable or not, even if they can't put them into probabilities.
|
||
* People to forecast the value of projects.
|
||
* Finding people to carry out projects.
|
||
* People to carry out projects.
|
||
* People to evaluate the value of projects after they have been completed.
|
||
* ...
|
||
|
||
In fact, the most time-consuming part of this project was not designing the experiment or doing the forecasting, but actually carrying the projects out. Nonetheless, it is not clear whether forecasting is currently cheap enough to be scalable.
|
||
|
||
If you would be interested in participating in a scaled-up version of this experiment (as a project-implementer, forecaster, etc.), or in later forecasting experiments, fill out [this form](https://docs.google.com/forms/d/e/1FAIpQLSdNsFton2XYf9-AlXePTdBNCRC2pVl0zNX541dWgjmbZv6CXA/viewform). I'm unsure about whether to scale this experiment, but if I do, I expect both recruitment to be a bottleneck and this first proposal to be read by more people than any subsequent announcement, hence the link now.
|
||
|
||
---
|
||
|
||
Conflict of interest: I've worked in the past as a paid contractor for foretold/Ozzie Gooen. Jacob Lagerros provided 2/3rds of the payout funding.
|