| data | ||
| outputs | ||
| src | ||
| .gitignore | ||
| README.md | ||
Models of Bayesian-like updating under constrained compute
This repository contains some implementations of models of bayesian-like updating under constrained compute. The world in which these models operate is the set of sequences from the Online Encyclopedia of Integer Sequences, which can be downloaded from here.
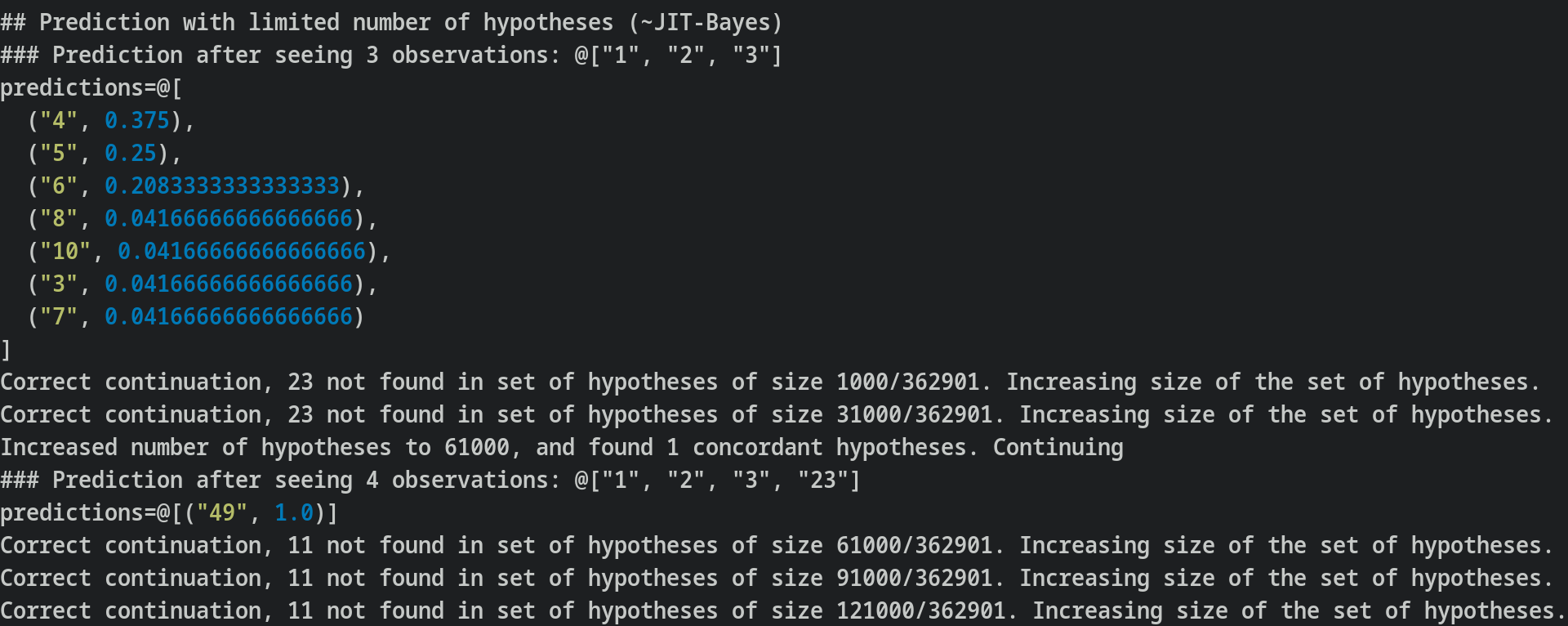
Models
Given the start of a sequence of integers, what is the probability of possible completions? This post offers various answers:
Unconstrained prediction
Just look at all possible sequence, and assign a probability to each continuation based on its frequency across all sequences
Prediction with access to subsequently more hypotheses.
Look at 10%, 20%,..., 80%, 90%, 100% of sequences, and give the probability of each continuation based on its frequencies across n% of sequences
Just in time Bayesianism
As described here, Just-in-time bayesianism is this scheme:
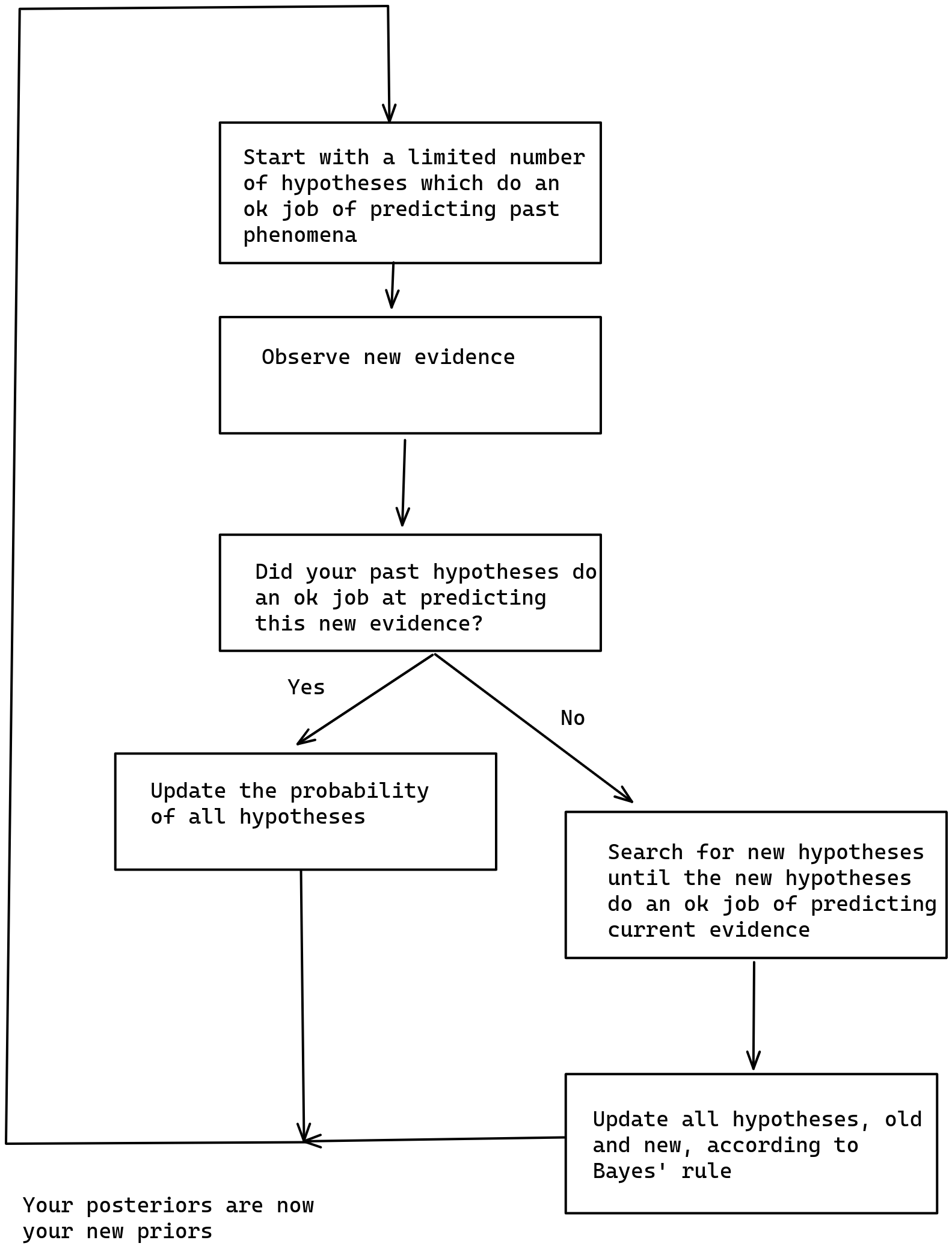
I think that the implementation here provides some value in terms of making fuzzy concepts explicit. For example, instead of "did your past hypotheses do an ok job at predicting this new evidence", I have code which looks at whether past predictions included the correct completion, and which expands the search for hypotheses if not.
I later elaborated on this type of scheme on A computable version of Solomonoff induction.
Infrabayesianism
Caveat for this section: This represents my partial understanding of some parts of infrabayesianism, and ideally I'd want someone to check it. Errors may exist.
Part I: Infrabayesianism in the sense of producing a deterministic policy that maximizes worst-case utility (minimizes worst-case loss)
In this example:
- environments are the possible OEIS sequences, shown one element at a time
- the actions are observing some elements, and making predictions about what the next element will be condition
- loss is the sum of the log scores after each observation.
- Note that at some point you arrive at the correct hypothesis, and so your subsequent probabilities are 1.0 (100%), and your subsequent loss 0 (log(1))
Claim: If there are n sequences which start with s, and m sequences that start with s and continue with q, the action which minimizes loss is assigning a probability of m/n to completion q.
Proof: In this case, let #{xs} denote the number of OEIS sequences that start with sequence xs, and let ø denote the empty sequence, such that ${ø} is the total number of OEIS sequences. Then your loss for a sequence (e1, e2, ..., en)—where en is the element by which you've identified the sequence with certainty—is log(#{e1}/#{ø}) + log(#{e1e2}/#{e1}) + ... + log(#{e1...en}/#{e1...e(n-1)}). Because log(a) + log(b) = log(a×b), that simplifies to log(#{e1...en}/#{ø}). But there is one unique sequence which starts with e1...en, and hence #{e1...en} = 1. Therefore this procedure just assigns the same probability to each sequence, namely 1/(number of sequences).
Now suppose you have some policy that makes predictions that deviate from the above, i.e., you assign a different probability than 1/#{} to some sequence. Then there is some sequence to which you are assigning a lower probability. Hence the maximum loss is higher. Therefore the policy which minimizes loss is the one described above.
Note: In the infrabayesianism post, the authors look at some extension of expected values which allow us to compute the minmax. But in this case, the result of policies in an environment is deterministic, and we can compute the minmax directly.
Note: To some extent having the result of policies in an environment be deterministic, and also the same in all environments, defeats a bit of the point of infrabayesianism. So I see this step as building towards a full implementation of Infrabayesianism.
Part II: Infrabayesianism in the additional sense of having hypotheses only over parts of the environment, without representing the whole environment
Have the same scheme as in Part I, but this time the environment is two OEIS sequences interleaved together.
Some quick math: If one sequence represented as an ASCII string is 4 Kilobytes (obtained with du -sh data/line), and the whole of OEIS takes 70MB, then all possibilities for two OEIS sequences interleaved together is 70MB/4K * 70MB, or over 1 TB.
But you can imagine more mischevous environments, like: a1, a2, b1, a3, b2, c1, a4, b3, c2, d1, a4, b4, c3, d2, ..., or in triangular form:
a1,
a2, b1,
a3, b2, c1,
a4, b3, c2, d1,
a4, b4, c3, d2, ...
(where (ai), (bi), etc. are independently drawn OEIS sequences)
Then you can't represent this environment with any amount of compute, and yet by only having hypotheses over different positions, you can make predictions about what the next element will be when given a list of observations.
We are not there yet, but interleaving OEIS sequences already provides an example of this sort.
Part III: Capture some other important aspect of infrabayesianism (e.g., non-deterministic environments)
[To do]
Built with
Why nim? Because it is nice to use and freaking fast.
Getting started
Prerequisites
Install nim and make. Then:
git clone https://git.nunosempere.com/personal/compute-constrained-bayes.git
cd compute-constrained-bayes
cd src
make deps ## get dependencies
Compilation
make fast ## also make, or make build, for compiling it with debug info.
./compute-constrained-bayes
Alternatively:
See here for a copy of the program's outputs.
Contributions
Contributions are very welcome, particularly around:
- Making the code more nim-like, using nim's standard styles and libraries
- Adding another example which is not logloss minimization for infrabayesianism?
- Adding other features of infrabayesianism?
Roadmap
- Exploration of OEIS data
- Subdivide subsequent tasks into steps
- Simple prediction of the next integer
- Simple predictions v1
- Wrangle the return types to something semi-elegant
- [-] Maybe add some caching, e.g., write continuations to file, and read them next time.
- JIT Bayesianism:
- Function to predict with a variable number of hypotheses
- Function to start predicting with a small number of hypotheses, and get more if the initial ones aren't enough.
- Add the loop of: start with some small number of sequences, and if these aren't enough, read more.
- Clean-up
- Infrabayesianism
- Infrabayesianism x1: Predicting interleaved sequences.
- Yeah, actually, I think this just captures an implicit assumption of Bayesianism as actually practiced.
- Infrabayesianism x2: Deterministic game of producing a fixed deterministic prediction, and then the adversary picking whatever minimizes your loss
- I am actually not sure of what the procedure is exactly for computing that loss. Do you minimize over subsequent rounds of the game, or only for the first round? Look this up.
- Also maybe ask for help from e.g., Alex Mennen?
- Lol, minimizing loss for the case where your utility is the logloss is actually easy.
- Infrabayesianism x1: Predicting interleaved sequences.
- Simple prediction of the next integer