Run prettier on website code
This commit is contained in:
parent
79ac1700d1
commit
efb0f5e05a
1
packages/website/.prettierignore
Normal file
1
packages/website/.prettierignore
Normal file
|
|
@ -0,0 +1 @@
|
|||
.docusaurus
|
||||
|
|
@ -6,23 +6,26 @@ This website is built using [Docusaurus 2](https://docusaurus.io/), a modern sta
|
|||
|
||||
This one actually works without running `yarn` at the monorepo level, but it doesn't hurt. You must at least run it at this package level
|
||||
|
||||
``` sh
|
||||
```sh
|
||||
yarn
|
||||
```
|
||||
|
||||
This command generates static content into the `build` directory and can be served using any static contents hosting service.
|
||||
``` sh
|
||||
|
||||
```sh
|
||||
yarn build
|
||||
```
|
||||
|
||||
Your local dev server is here, opening up a browser window.
|
||||
``` sh
|
||||
|
||||
```sh
|
||||
yarn start
|
||||
```
|
||||
|
||||
Most changes are reflected live without having to restart the server.
|
||||
|
||||
Clean up the build artefacts.
|
||||
``` sh
|
||||
|
||||
```sh
|
||||
yarn clean
|
||||
```
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
module.exports = {
|
||||
presets: [
|
||||
require.resolve('@docusaurus/core/lib/babel/preset'),
|
||||
["@babel/preset-react", { "runtime": "automatic" }]
|
||||
require.resolve("@docusaurus/core/lib/babel/preset"),
|
||||
["@babel/preset-react", { runtime: "automatic" }],
|
||||
],
|
||||
};
|
||||
|
|
|
|||
|
|
@ -5,9 +5,10 @@ authors: ozzie
|
|||
---
|
||||
|
||||
# Multivariate estimation & the Squiggly language
|
||||
*This post was originally published on Aug 2020, on [LessWrong](https://www.lesswrong.com/posts/g9QdXySpydd6p8tcN/sunday-august-16-12pm-pdt-talks-by-ozzie-gooen-habryka-ben). The name of the project has since been changed from Suiggly to Squiggle*
|
||||
|
||||
*(Talk given at the LessWrong Lighting Talks in 2020. Ozzie Gooen is responsible for the talk, Jacob Lagerros and Justis Mills edited the transcript.* [an event on Sunday 16th of August](https://www.lesswrong.com/posts/g9QdXySpydd6p8tcN/sunday-august-16-12pm-pdt-talks-by-ozzie-gooen-habryka-ben))
|
||||
_This post was originally published on Aug 2020, on [LessWrong](https://www.lesswrong.com/posts/g9QdXySpydd6p8tcN/sunday-august-16-12pm-pdt-talks-by-ozzie-gooen-habryka-ben). The name of the project has since been changed from Suiggly to Squiggle_
|
||||
|
||||
_(Talk given at the LessWrong Lighting Talks in 2020. Ozzie Gooen is responsible for the talk, Jacob Lagerros and Justis Mills edited the transcript._ [an event on Sunday 16th of August](https://www.lesswrong.com/posts/g9QdXySpydd6p8tcN/sunday-august-16-12pm-pdt-talks-by-ozzie-gooen-habryka-ben))
|
||||
|
||||

|
||||
**Ozzie:** This image is my [TLDR](https://en.wikipedia.org/wiki/Wikipedia:Too_long;_didn%27t_read) on probability distributions:
|
||||
|
|
@ -49,16 +50,17 @@ So that's why I've been working on the Squiggly language.
|
|||
Let’s look at some quick examples!
|
||||
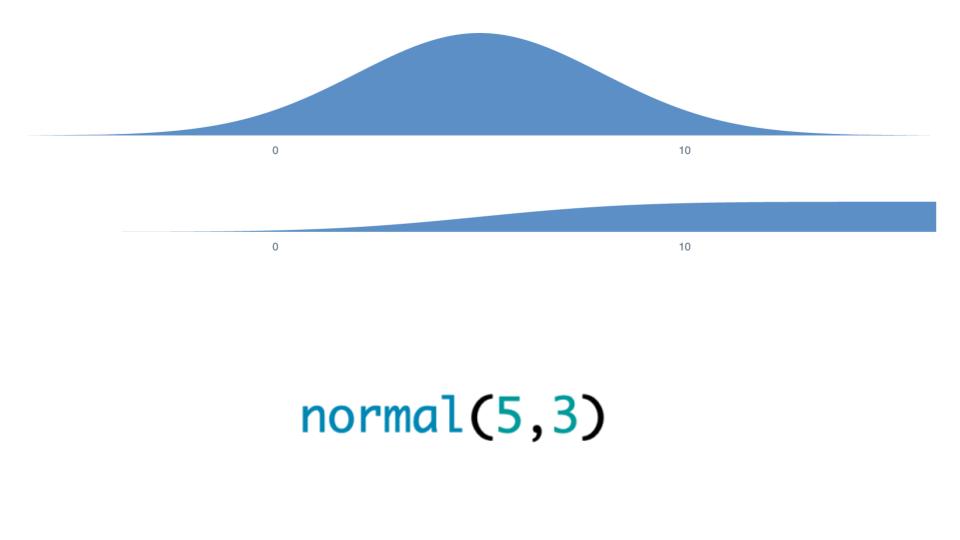
|
||||
This is a classic normal distribution, but once you have this, some of the challenge is making it as easy as possible to make functions that return distributions.
|
||||
Here's a case for any *t*:
|
||||
Here's a case for any _t_:
|
||||
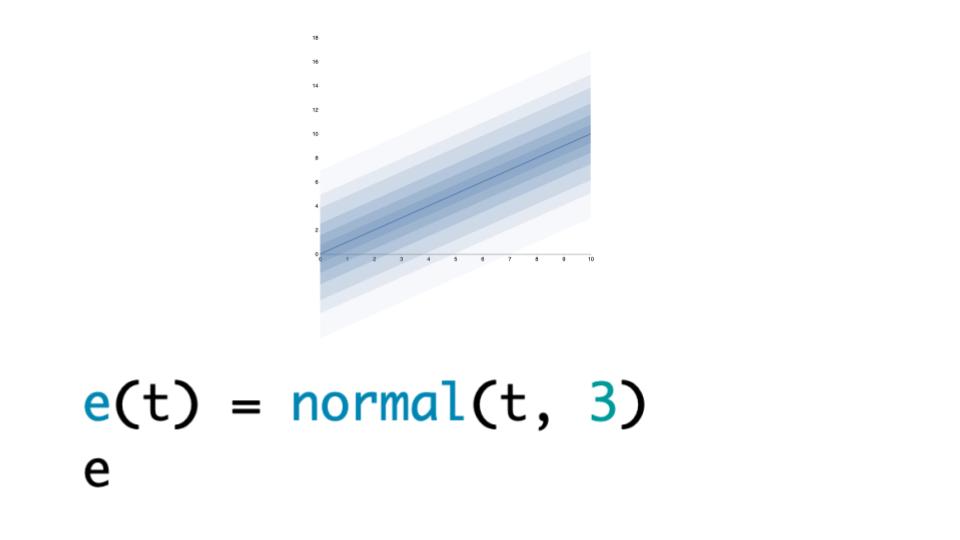
|
||||
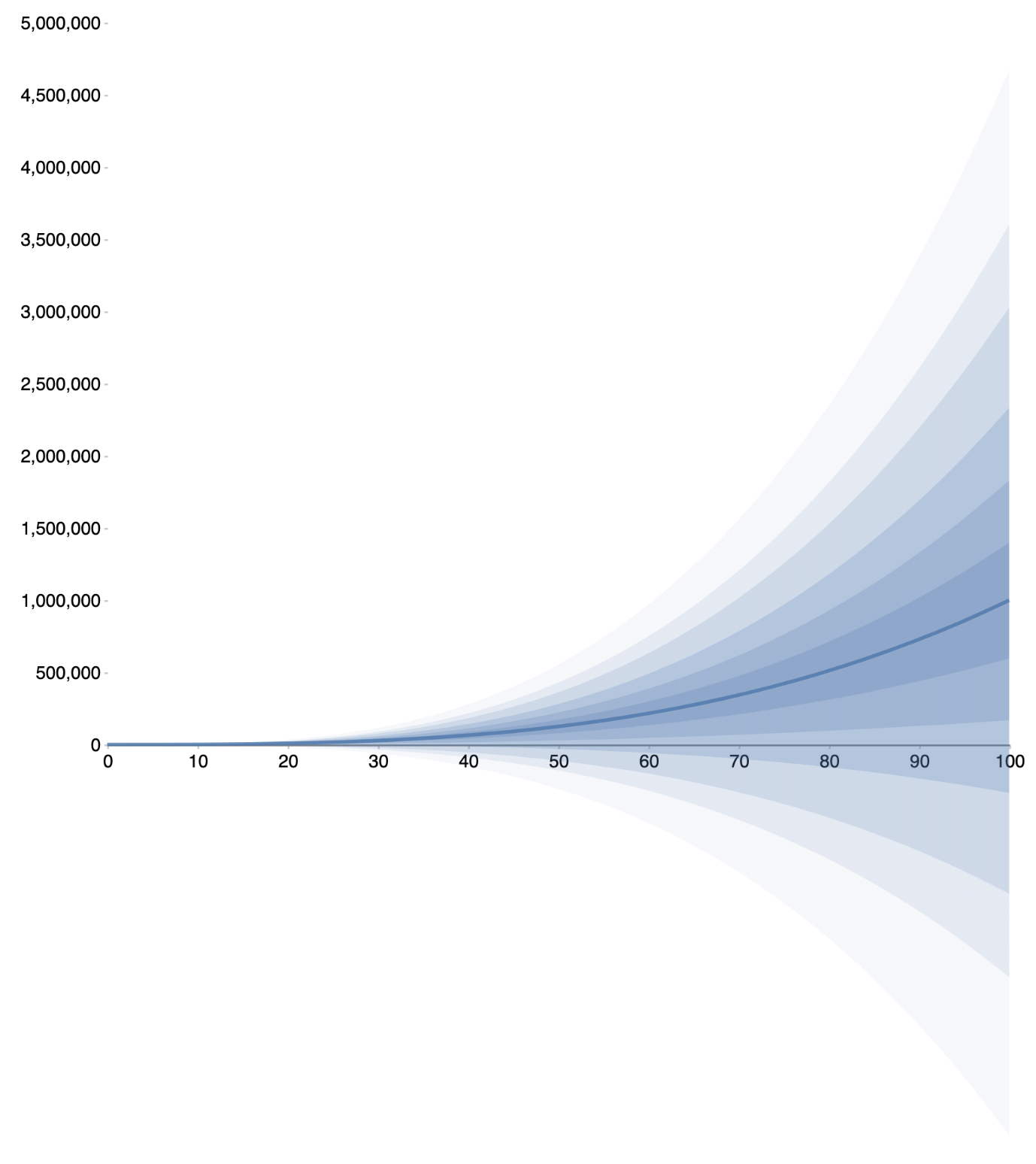
We're going to give you a normal, with *t* as a mean and the standard deviation of 3. This is a plot where it's basically showing bars at each one of the deciles. It gets a bit wider at the end. It's very easy once you have this to just create it for any specific combination of values.
|
||||
We're going to give you a normal, with _t_ as a mean and the standard deviation of 3. This is a plot where it's basically showing bars at each one of the deciles. It gets a bit wider at the end. It's very easy once you have this to just create it for any specific combination of values.
|
||||
It’s also cool, because once you have it in this format, it’s very easy to combine multiple models. For instance, here’s a lognormal.
|
||||
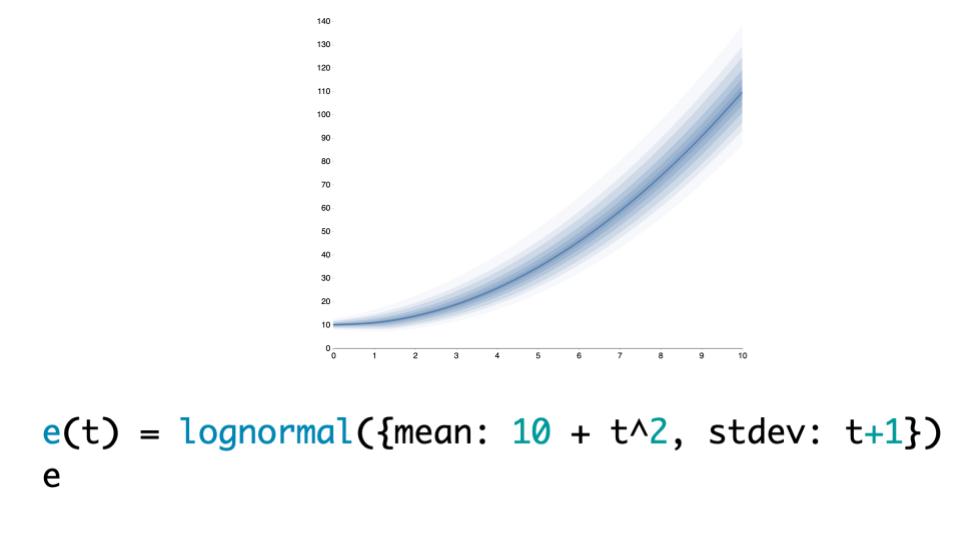
|
||||
For example, if I have an estimate and my friend Jacob has an estimate, then we could write a function that for every time *t*, basically queries each one of our estimates and gives that as a combined result.
|
||||
For example, if I have an estimate and my friend Jacob has an estimate, then we could write a function that for every time _t_, basically queries each one of our estimates and gives that as a combined result.
|
||||
This kind of shows you a problem with fan charts, that they don’t show the fact that all the probability amasses on the very top and the very bottom. That’s an issue that we’ll get over soon. Here’s what it looks like if I aggregate my model with Jacob’s.
|
||||

|
||||
|
||||
## Questions
|
||||
|
||||
**Raemon:**
|
||||
I had a little bit of excitement, and then fear, and then excitement again, when you talked about a unified format. The excitement was like, “Ah, a unified format, that sounds nice.” Then I had an image of all of the giant coordination problems that result from failed attempts to create a new unified format, where the attempted unified format becomes [yet another distinct format](https://xkcd.com/927/) among all the preexisting options.
|
||||
|
||||
|
|
@ -75,7 +77,8 @@ Yeah, you can build the thing that seems good for you. That seems good. If you g
|
|||
**Ozzie:**
|
||||
Yeah. Right now, I’m aiming for something that’s good at a bunch of things but not that great at any one of them. I’m also very curious to get outside opinions. Hopefully people could start playing with this, and I can get their thoughts.
|
||||
|
||||
- - - -
|
||||
---
|
||||
|
||||
**habryka:**
|
||||
This feels very similar to [Guesstimate](https://www.getguesstimate.com/) , which you also built, just in programming language as opposed to visual language. How does this project differ?
|
||||
|
||||
|
|
@ -86,7 +89,8 @@ Really, a lot of Squiggly is me trying to remake for my sins with Guesstimate. W
|
|||
|
||||
So I think these new features are pretty fundamental. I think that this is a pretty big step in the right direction. In general text-based solutions have a lot of benefits when you can use them, but it is kind of tricky to use them.
|
||||
|
||||
- - - -
|
||||
---
|
||||
|
||||
**Johnswentworth:**
|
||||
I’m getting sort of mixed vibes about what exactly the use case here is. If we’re thinking of this as a sort of standard for representing models, then I should be able to convert models in other formats, right? Like, if I have a model in Excel or I have a model in [Pyro](https://pyro.ai/) , then there should be some easy way to turn it into this standard format?
|
||||
|
||||
|
|
@ -112,7 +116,7 @@ It’s complicated. If you made your model in Pyro and you wanted to then export
|
|||
Why would people run that though? Why do people want that compressed model?
|
||||
|
||||
**Ozzie:**
|
||||
I mean, a lot of the COVID models are like that, where basically the *running* of the simulation was very time intensive and required one person’s whole PC. But it would still be nice to be able to export the *results*of that and then make those interactable, right?
|
||||
I mean, a lot of the COVID models are like that, where basically the _running_ of the simulation was very time intensive and required one person’s whole PC. But it would still be nice to be able to export the *results*of that and then make those interactable, right?
|
||||
|
||||
**Johnswentworth:**
|
||||
Oh, I see. Okay, I buy that.
|
||||
|
|
@ -123,9 +127,10 @@ I also don’t want to have to write all of the work to do all of the Pyro stuff
|
|||
**Johnswentworth:**
|
||||
Usually, when I’m thinking about this sort of thing, and I look at someone’s model, I really want to know what the underlying gears were behind it. Which is exactly the opposite of what you’re talking about. So it’s just a use case that I’m not used to thinking through. But I agree, it does make sense.
|
||||
|
||||
- - - -
|
||||
---
|
||||
|
||||
**habryka:**
|
||||
Why call the language Squiggly? There were a surprising lack of squiggles in the language. I was like, “Ah, it makes sense, you just use the squiggles as the primary abstraction” — but then you showed me your code editor and there were no squiggles, and I was very disappointed.
|
||||
|
||||
**Ozzie:**
|
||||
Yeah, so I haven’t written my own parser yet. I’ve been using the one from math.js. When I write my own, it’s possible I’ll add it. I also am just really unsure about the name.
|
||||
Yeah, so I haven’t written my own parser yet. I’ve been using the one from math.js. When I write my own, it’s possible I’ll add it. I also am just really unsure about the name.
|
||||
|
|
|
|||
|
|
@ -3,24 +3,30 @@ slug: technical-overview
|
|||
title: Technical Overview
|
||||
authors: ozzie
|
||||
---
|
||||
|
||||
# Squiggle Technical Overview
|
||||
|
||||
This piece is meant to be read after [Squiggle: An Overview](https://www.lesswrong.com/posts/i5BWqSzuLbpTSoTc4/squiggle-an-overview) . It includes technical information I thought best separated out for readers familiar with coding. As such, it’s a bit of a grab-bag. It explains the basic internals of Squiggle, outlines ways it could be used in other programming languages, and details some of the history behind it.
|
||||
|
||||
The Squiggle codebase is organized in [this github repo](https://github.com/foretold-app/squiggle) . It’s open source. The code is quite messy now, but do ping me if you’re interested in running it or understanding it.
|
||||
|
||||
## Project Subcomponents
|
||||
|
||||
I think of Squiggle in three distinct clusters.
|
||||
|
||||
1. A high-level ReasonML library for probability distributions.
|
||||
2. A simple programming language.
|
||||
3. Custom visualizations and GUIs.
|
||||
|
||||
### 1. A high-level ReasonML library for probability distribution functions
|
||||
|
||||
Python has some great libraries for working with probabilities and symbolic mathematics. Javascript doesn’t. Squiggle is to be run in Javascript (for interactive editing and use), so the first step for this is to have good libraries to do the basic math.
|
||||
|
||||
The second step is to have-level types that could express various types of distributions and functions of distributions. For example, some distributions have symbolic representations, and others are rendered (stored as x-y coordinates). These two types have to be dealt with separately. Squiggle also has limited support for continuous and discrete mixtures, and the math for this adds more complexity.
|
||||
|
||||
When it comes to performing functions on expressions, there’s a lot of optimization necessary for this to go smoothly.
|
||||
Say you were to write the function,
|
||||
|
||||
```
|
||||
multimodal(normal(5,2), normal(10,1) + uniform(1,10)) * 100
|
||||
```
|
||||
|
|
@ -30,6 +36,7 @@ You’d want to apply a combination of symbolic, numeric, and sampling technique
|
|||
This type-dependent function operations can be confusing to users, but hopefully less confusing than having to figure out how to do each of the three and doing them separately. I imagine there could be some debugging UI to better explain what operations are performed.
|
||||
|
||||
### 2. Simple programming language functionality
|
||||
|
||||
It can be useful to think of Squiggle as similar to SQL, Excel, or Probabilistic Programming Languages like [WebPPL](http://webppl.org/) . There are simple ways to declare variables and write functions, but don’t expect to use classes, inheritance, or monads. There’s no for loops, though it will probably have some kinds of reduce() methods in the future.
|
||||
|
||||
So far the parsing is done with MathJS, meaning we can’t change the syntax. I’m looking forward to doing so and have been thinking about what it should be like. One idea I’m aiming for is to allow for simple dependent typing for the sake of expressing limited functions. For instance,
|
||||
|
|
@ -44,6 +51,7 @@ This function would return an error if called with a float less than 0 or greate
|
|||
With some introspection it should be possible to auto-generate calculator-like interfaces.
|
||||
|
||||
### 3. Visualizations and GUIs
|
||||
|
||||
The main visualizations need to be made from scratch because there’s little out there now in terms of quality open-source visualizations of probability distributions and similar. This is especially true for continuous and discrete mixtures. D3 seems like the main library here, and D3 can be gnarly to write and maintain.
|
||||
|
||||
Right now we’re using a basic [Vega](https://vega.github.io/) chart for the distribution over a variable, but this will be replaced later.
|
||||
|
|
@ -51,6 +59,7 @@ Right now we’re using a basic [Vega](https://vega.github.io/) chart for the
|
|||
In the near term, I’m interested in making calculator-like user interfaces of various kinds. I imagine one prediction function could be used for many interfaces of calculators.
|
||||
|
||||
## Deployment Story, or, Why Javascript?
|
||||
|
||||
Squiggle is written in ReasonML which compiles to Javascript. The obvious alternative is Python. Lesser obvious but interesting options are Mathematica or Rust via WebAssembly.
|
||||
|
||||
The plan for Squiggle is to prioritize small programs that could be embedded in other programs and run quickly. Perhaps there will be 30 submissions for a “Covid-19 over time per location” calculator, and we’d want to run them in parallel in order to find the average answer or to rank them. I could imagine many situations where it would be useful to run these functions for many different inputs; for example, for kinds of sensitivity analyses.
|
||||
|
|
@ -76,11 +85,13 @@ ReasonML compiles to OCaml before it compiles to Javascript. I’ve found it con
|
|||
I imagine the landscape will change a lot in the next 3 to 10 years. I’m going to continue to keep an eye on the space. If things change I could very much imagine pursuing a rewrite, but I think it will be a while before any change seems obvious.
|
||||
|
||||
## Using Squiggle with other languages
|
||||
|
||||
Once the basics of Squiggle are set up, it could be used to describe the results of models that come from other programs. Similar to how many programming languages have ORMs to generate custom SQL statements, similar tools could be made to generate Squiggle functions. The important thing to grok is that Squiggle functions are submitted information, not just internally useful tools. If there were an API to accept “predictions”, people would submit Squiggle code snippets directly to this API.
|
||||
|
||||
*I’d note here that I find it somewhat interesting how few public APIs do accept code snippets. I could imagine a version of Facebook where you could submit a Javascript function that would take in information about a post and return a number that would be used for ranking it in your feed. This kind of functionality seems like it could be very powerful. My impression is that it’s currently thought to be too hard to do given existing technologies. This of course is not a good sign for the feasibility of my proposal here, but this coarse seems like a necessary one to do at some time.*
|
||||
_I’d note here that I find it somewhat interesting how few public APIs do accept code snippets. I could imagine a version of Facebook where you could submit a Javascript function that would take in information about a post and return a number that would be used for ranking it in your feed. This kind of functionality seems like it could be very powerful. My impression is that it’s currently thought to be too hard to do given existing technologies. This of course is not a good sign for the feasibility of my proposal here, but this coarse seems like a necessary one to do at some time._
|
||||
|
||||
### Example #1:
|
||||
|
||||
Say you calculate a few parameters, but know they represent a multimodal combination of a normal distribution and a uniform distribution. You want to submit that as your prediction or estimate via the API of Metaculus or Foretold. You could write that as (in Javascript):
|
||||
|
||||
```
|
||||
|
|
@ -92,6 +103,7 @@ The alternative to this is that you send a bunch of X-Y coordinates representing
|
|||
With Squiggle, you don’t need to calculate the shape of the function in your code, you just need to express it symbolically and send that off.
|
||||
|
||||
### Example #2:
|
||||
|
||||
Say you want to describe a distribution with a few or a bunch of calculated CDF points. You could do this by wrapping these points into a function that would convert them into a smooth distribution using one of several possible interpolation methods. Maybe in Javascript this would be something like,
|
||||
|
||||
```
|
||||
|
|
@ -102,6 +114,7 @@ var squiggleValue = `interpolatePoints(${points}, metalog)`
|
|||
I could imagine it is possible that the majority of distributions generated from other code would be sent this way. However, I can’t tell what the specifics of that now or what interpolation strategies may be favored. Doing it with many options would allow us to wait and learn what seems to be best. If there is one syntax used an overwhelming proportion of the time, perhaps that could be separated into its own simpler format.
|
||||
|
||||
### Example #3:
|
||||
|
||||
Say you want to estimate Tesla stock at every point in the next 10 years. You decide to estimate this using a simple analytical equation, where you predict that the price of Tesla stock can be modeled as growing by a mean of -3 to 8 percent each year from the current price using a normal distribution (apologies to Nassim Taleb).
|
||||
|
||||
You have a script that fetches Tesla’s current stock, then uses that in the following string template:
|
||||
|
|
@ -113,6 +126,7 @@ var squiggleValue = `(t) => ${current_price} * (0.97 to 1.08)^t`
|
|||
It may seem a bit silly to not just fetch Tesla’s price from within Squiggle, but it does help separate concerns. Data fetching within Squiggle would raise a bunch of issues, especially when trying to score Squiggle functions.It may seem a bit silly to not just fetch Tesla’s price from within Squiggle, but it does help separate concerns. Data fetching within Squiggle would raise a bunch of issues, especially when trying to score Squiggle functions.
|
||||
|
||||
## History: From Guesstimate to Squiggle
|
||||
|
||||
The history of “Squiggle” goes back to early Guesstimate. It’s been quite a meandering journey. I was never really expecting things to go the particular way they did, but at least am relatively satisfied with how things are right now. I imagine these details won’t be interesting to most readers, but wanted to include it for those particularly close to the project, or for those curious on what I personally have been up to.
|
||||
|
||||
90% of the work on Squiggle has been on a probability distribution editor (“A high-level ReasonML library for probability distribution functions**”)**. This has been a several year process, including my time with Guesstimate. The other 10% of the work, with the custom functions, is much more recent.
|
||||
|
|
@ -128,11 +142,13 @@ Limited distribution editors like those in Metaculus or Elicit don’t use sampl
|
|||
It took a while, but we eventually created a simple editor that would use numeric techniques to combine a small subset of distributions and functions using a semi-flexible string representation. If users would request functionality not available in this editor (like multiplying two distributions together, which would require sampling), it would fall back to using the old editor. This was useful but suboptimal. It required us to keep two versions of the editor with slightly different syntaxes, which was not fun for users to keep track of.
|
||||
|
||||
The numeric solver could figure out syntaxes like,
|
||||
|
||||
```
|
||||
multimodal(normal(5,2), uniform(10,13), [.2,.8])
|
||||
```
|
||||
|
||||
But would break anytime you wanted to use any other function, like,
|
||||
|
||||
```
|
||||
multimodal(normal(5,2) + lognormal(1,1.5), uniform(10,13), [.2,.8])*100
|
||||
```
|
||||
|
|
|
|||
|
|
@ -4,9 +4,9 @@ title: Squiggle Overview
|
|||
authors: ozzie
|
||||
---
|
||||
|
||||
I’ve spent a fair bit of time over the last several years iterating on a text-based probability distribution editor (the ``5 to 10`` input editor in Guesstimate and Foretold). Recently I’ve added some programming language functionality to it, and have decided to refocus it as a domain-specific language.
|
||||
I’ve spent a fair bit of time over the last several years iterating on a text-based probability distribution editor (the `5 to 10` input editor in Guesstimate and Foretold). Recently I’ve added some programming language functionality to it, and have decided to refocus it as a domain-specific language.
|
||||
|
||||
The language is currently called *Squiggle*. Squiggle is made for expressing distributions and functions that return distributions. I hope that it can be used one day for submitting complex predictions on Foretold and other platforms.
|
||||
The language is currently called _Squiggle_. Squiggle is made for expressing distributions and functions that return distributions. I hope that it can be used one day for submitting complex predictions on Foretold and other platforms.
|
||||
|
||||
Right now Squiggle is very much a research endeavor. I’m making significant sacrifices for stability and deployment in order to test out exciting possible features. If it were being developed in a tech company, it would be in the “research” or “labs” division.
|
||||
|
||||
|
|
@ -16,13 +16,16 @@ I expect to spend a lot of time on Squiggle in the next several months or years.
|
|||
|
||||
Squiggle was previously introduced in a short talk that was transcribed [here](https://www.lesswrong.com/posts/kTzADPE26xh3dyTEu/multivariate-estimation-and-the-squiggly-language) , and Nuño Sempere wrote a post about using it [here](https://www.lesswrong.com/posts/kTzADPE26xh3dyTEu/multivariate-estimation-and-the-squiggly-language) .
|
||||
|
||||
*Note: the code for this has developed since my time on Guesstimate. With Guesstimate, I had one cofounder, Matthew McDermott. During the last two years, I’ve had a lot of help from a handful of programmers and enthusiasts. Many thanks to Sebastian Kosch and Nuño Sempere, who both contributed. I’ll refer to this vague collective as “we” throughout this post.*
|
||||
_Note: the code for this has developed since my time on Guesstimate. With Guesstimate, I had one cofounder, Matthew McDermott. During the last two years, I’ve had a lot of help from a handful of programmers and enthusiasts. Many thanks to Sebastian Kosch and Nuño Sempere, who both contributed. I’ll refer to this vague collective as “we” throughout this post._
|
||||
|
||||
---
|
||||
|
||||
# Video Demo
|
||||
|
||||
<iframe width="675" height="380" src="https://www.youtube.com/embed/kJLybQWujco" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
||||
|
||||
## A Quick Tour
|
||||
|
||||
The syntax is forked from Guesstimate and Foretold.
|
||||
|
||||
**A simple normal distribution**
|
||||
|
|
@ -30,11 +33,13 @@ The syntax is forked from Guesstimate and Foretold.
|
|||
```
|
||||
normal(5,2)
|
||||
```
|
||||
|
||||

|
||||
|
||||
You may notice that unlike Guesstimate, the distribution is nearly perfectly smooth. It’s this way because it doesn’t use sampling for (many) functions where it doesn’t need to.
|
||||
|
||||
**Lognormal shorthand**
|
||||
|
||||
```
|
||||
5 to 10
|
||||
```
|
||||
|
|
@ -43,20 +48,20 @@ You may notice that unlike Guesstimate, the distribution is nearly perfectly smo
|
|||
|
||||
This results in a lognormal distribution with 5 to 10 being the 5th and 95th confidence intervals respectively.
|
||||
You can also write lognormal distributions as: ### lognormal(1,2)
|
||||
or ### lognormal({mean: 3, stdev: 8})
|
||||
or ### lognormal({mean: 3, stdev: 8})
|
||||
.
|
||||
|
||||
**Mix distributions with the multimodal function**
|
||||
|
||||
```multimodal(normal(5,2), uniform(14,19), [.2, .8])```
|
||||
`multimodal(normal(5,2), uniform(14,19), [.2, .8])`
|
||||
|
||||
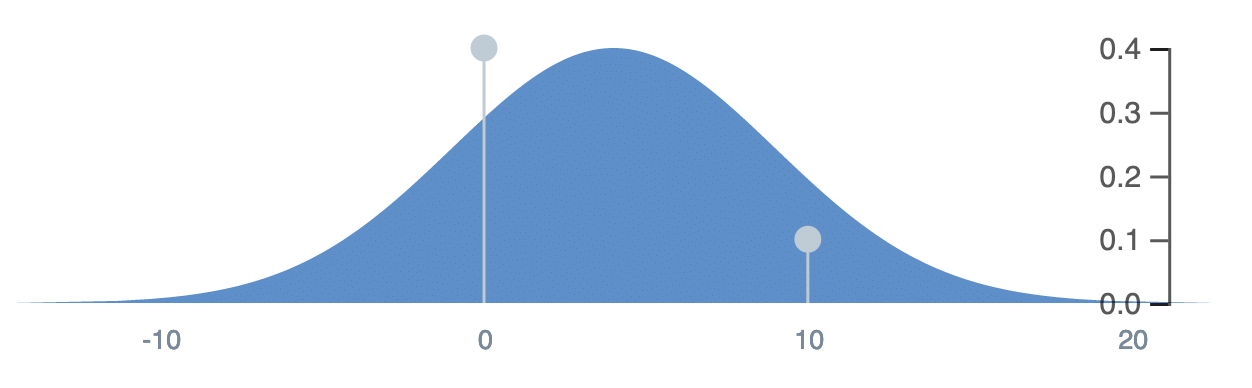
|
||||
|
||||
You can also use the shorthand *mm*(), and add an array at the end to represent the weights of each combined distribution.
|
||||
*Note: Right now, in the demo, I believe “multimodal” is broken, but you can use “mm”.*
|
||||
You can also use the shorthand _mm_(), and add an array at the end to represent the weights of each combined distribution.
|
||||
_Note: Right now, in the demo, I believe “multimodal” is broken, but you can use “mm”._
|
||||
|
||||
**Mix distributions with discrete data**
|
||||
*Note: This is particularly buggy.* .
|
||||
_Note: This is particularly buggy._ .
|
||||
|
||||
```
|
||||
multimodal(0, 10, normal(4,5), [.4,.1, .5])
|
||||
|
|
@ -65,6 +70,7 @@ multimodal(0, 10, normal(4,5), [.4,.1, .5])
|
|||

|
||||
|
||||
**Variables**
|
||||
|
||||
```
|
||||
expected_case = normal(5,2)
|
||||
long_tail = 3 to 1000
|
||||
|
|
@ -73,6 +79,7 @@ multimodal(expected_case, long_tail, [.2,.8])
|
|||
|
||||
**Simple calculations**
|
||||
When calculations are done on two distributions, and there is no trivial symbolic solution the system will use Monte Carlo sampling for these select combinations. This assumes they are perfectly independent.
|
||||
|
||||
```
|
||||
multimodal(normal(5,2) + uniform(10,3), (5 to 10) + 10) * 100
|
||||
```
|
||||
|
|
@ -81,6 +88,7 @@ multimodal(normal(5,2) + uniform(10,3), (5 to 10) + 10) * 100
|
|||
|
||||
**Pointwise calculations**
|
||||
We have an infix for what can be described as pointwise distribution calculations. Calculations are done along the y-axis instead of the x-axis, so to speak. “Pointwise” multiplication is equivalent to an independent Bayesian update. After each calculation, the distributions are renormalized.
|
||||
|
||||
```
|
||||
normal(10,4) .* normal(14,3)
|
||||
```
|
||||
|
|
@ -105,18 +113,20 @@ myFunction
|
|||
|
||||
|
||||
## Reasons to Focus on Functions
|
||||
|
||||
Up until recently, Squiggle didn’t have function support. Going forward this will be the primary feature.
|
||||
|
||||
Functions are useful for two distinct purposes. First, they allow composition of models. Second, they can be used directly to be submitted as predictions. For instance, in theory you could predict, “For any point in time T, and company N, from now until 2050, this function will predict the market cap of the company.”
|
||||
|
||||
At this point I’m convinced of a few things:
|
||||
* It’s possible to intuitively write distributions and functions that return distributions, with the right tooling.
|
||||
* Functions that return distributions are highly preferable to specific distributions, if possible.
|
||||
* It would also be great if existing forecasting models could be distilled into common formats.
|
||||
* There’s very little activity in this space now.
|
||||
* There’s a high amount of value of information to further exploring the space.
|
||||
* Writing a small DSL like this will be a fair bit of work, but can be feasible if the functionality is kept limited.
|
||||
* Also, there are several other useful aspects about having a simple language equivalent for Guesstimate style models.
|
||||
|
||||
- It’s possible to intuitively write distributions and functions that return distributions, with the right tooling.
|
||||
- Functions that return distributions are highly preferable to specific distributions, if possible.
|
||||
- It would also be great if existing forecasting models could be distilled into common formats.
|
||||
- There’s very little activity in this space now.
|
||||
- There’s a high amount of value of information to further exploring the space.
|
||||
- Writing a small DSL like this will be a fair bit of work, but can be feasible if the functionality is kept limited.
|
||||
- Also, there are several other useful aspects about having a simple language equivalent for Guesstimate style models.
|
||||
|
||||
I think that this is a highly neglected area and I’m surprised it hasn’t been explored more. It’s possible that doing a good job is too challenging for a small team, but I think it’s worth investigating further.
|
||||
|
||||
|
|
@ -137,20 +147,24 @@ One analogy is to think about the online estimation “calculators” and “mod
|
|||
If they were to use a hypothetical front end unified format, this would mean converting their results into a Javascript function that could be called using a standardized interface. This standardization would make it easier for these calculators to be called by third party wigets and UIs, or for them to be downloaded and called from other workflows. The priority here is that the calculators could be run quickly and that the necessary code and data is minimized in size. Heavy calculation and analysis would still happen separately.
|
||||
|
||||
### Future “Comprehensive” Uses
|
||||
|
||||
On the more comprehensive end, it would be interesting to figure out how individuals or collectives could make large clusters of these functions, where many functions call other functions, and continuous data is pulled in. The latter would probably require some server/database setup that ingests Squiggle files.
|
||||
|
||||
I think the comprehensive end is significantly more exciting than simpler use cases but also significantly more challenging. It’s equivalent to going from Docker the core technology, to Docker hub, then making an attempt at Kubernetes. Here we barely have a prototype of the proverbial Docker, so there’s a lot of work to do.
|
||||
|
||||
### Why doesn’t this exist already?
|
||||
|
||||
I will briefly pause here to flag that I believe the comprehensive end seems fairly obvious as a goal and I’m quite surprised it hasn’t really been attempted yet, from what I can tell. I imagine such work could be useful to many important actors, conditional on them understanding how to use it.
|
||||
|
||||
My best guess is this is due to some mix between:
|
||||
* It’s too technical for many people to be comfortable with.
|
||||
* There’s a fair amount of work to be done, and it’s difficult to monetize quickly.
|
||||
* There’s been an odd, long-standing cultural bias against clearly intuitive estimates.
|
||||
* The work is substantially harder than I realize.
|
||||
|
||||
- It’s too technical for many people to be comfortable with.
|
||||
- There’s a fair amount of work to be done, and it’s difficult to monetize quickly.
|
||||
- There’s been an odd, long-standing cultural bias against clearly intuitive estimates.
|
||||
- The work is substantially harder than I realize.
|
||||
|
||||
# Related Tools
|
||||
|
||||
**Guesstimate**
|
||||
I previously made Guesstimate and take a lot of inspiration from it. Squiggle will be a language that uses pure text, not a spreadsheet. Perhaps Squiggle could one day be made available within Guesstimate cells.
|
||||
|
||||
|
|
@ -181,11 +195,12 @@ Knowledge graphs seem like the best tool for describing semantic relationships i
|
|||
For example, someone could write a function that takes in a “standard location schema” and returns a calculation of the number of piano tuners at that location. Later when someone queries Wikipedia for a town, it will recognize that that town has data on [Wikidata](https://www.wikidata.org/wiki/Wikidata:Main_Page) , which can be easily converted into the necessary schema.
|
||||
|
||||
## Next Steps
|
||||
|
||||
Right now I’m the only active developer of Squiggle. My work is split between Squiggle, writing blog posts and content, and other administrative and organizational duties for QURI.
|
||||
|
||||
My first plan is to add some documentation, clean up the internals, and begin writing short programs for personal and group use. If things go well and we could find a good developer to hire, I would be excited to see what we could do after a year or two.
|
||||
|
||||
Ambitious versions of Squiggle would be a *lot* of work (as in, 50 to 5000+ engineer years work), so I want to take things one step at a time. I would hope that if progress is sufficiently exciting, it would be possible to either raise sufficient funding or encourage other startups and companies to attempt their own similar solutions.
|
||||
Ambitious versions of Squiggle would be a _lot_ of work (as in, 50 to 5000+ engineer years work), so I want to take things one step at a time. I would hope that if progress is sufficiently exciting, it would be possible to either raise sufficient funding or encourage other startups and companies to attempt their own similar solutions.
|
||||
|
||||
## Footnotes
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
sidebar_position: 7
|
||||
---
|
||||
|
||||
import { SquiggleEditor } from '../src/components/SquiggleEditor'
|
||||
import { SquiggleEditor } from "../src/components/SquiggleEditor";
|
||||
|
||||
# Squiggle Functions Reference
|
||||
|
||||
|
|
@ -22,7 +22,6 @@ two given numbers.
|
|||
|
||||
<SquiggleEditor initialSquiggleString="uniform(3, 7)" />
|
||||
|
||||
|
||||
### Lognormal distribution
|
||||
|
||||
The `lognormal(mu, sigma)` returns the log of a normal distribution with parameters
|
||||
|
|
@ -42,7 +41,6 @@ and standard deviation, using `lognormalFromMeanAndStdDev`.
|
|||
|
||||
<SquiggleEditor initialSquiggleString="lognormalFromMeanAndStdDev(20, 10)" />
|
||||
|
||||
|
||||
### Beta distribution
|
||||
|
||||
The `beta(a, b)` function creates a beta distribution with parameters a and b:
|
||||
|
|
@ -56,7 +54,6 @@ mean.
|
|||
|
||||
<SquiggleEditor initialSquiggleString="exponential(1)" />
|
||||
|
||||
|
||||
### The Triangular distribution
|
||||
|
||||
The `triangular(a,b,c)` function creates a triangular distribution with lower
|
||||
|
|
@ -84,6 +81,7 @@ As well as mixed distributions:
|
|||
## Other Functions
|
||||
|
||||
### PDF of a distribution
|
||||
|
||||
The `pdf(distribution, x)` function returns the density of a distribution at the
|
||||
given point x.
|
||||
|
||||
|
|
@ -104,11 +102,13 @@ or all values lower than x. It is the inverse of `inv`.
|
|||
<SquiggleEditor initialSquiggleString="cdf(normal(0,1),0)" />
|
||||
|
||||
### Mean of a distribution
|
||||
|
||||
The `mean(distribution)` function gives the mean (expected value) of a distribution.
|
||||
|
||||
<SquiggleEditor initialSquiggleString="mean(normal(5, 10))" />
|
||||
|
||||
### Sampling a distribution
|
||||
|
||||
The `sample(distribution)` samples a given distribution.
|
||||
|
||||
<SquiggleEditor initialSquiggleString="sample(normal(0, 10))" />
|
||||
|
|
|
|||
|
|
@ -3,16 +3,18 @@ sidebar_position: 4
|
|||
---
|
||||
|
||||
# Future Features
|
||||
|
||||
Squiggle is still very early. The main first goal is to become stable. This means having a clean codebase, having decent test coverage, and having a syntax we are reasonably confident in. Later on, there are many other features that will be interesting to explore.
|
||||
|
||||
## Programming Language Features
|
||||
|
||||
- Equality (a == b)
|
||||
- If/else statements
|
||||
- Arrays
|
||||
- Tables / Matrices
|
||||
- Simple objects
|
||||
- A simple type system
|
||||
- Simple module system (``Dist.Normal`` instead of ``normal``)
|
||||
- Simple module system (`Dist.Normal` instead of `normal`)
|
||||
- A simple time library & notation
|
||||
- Optional and default paramaters for functions
|
||||
- Anonymous Functions (This is particularly convenient in cases where tiny functions are submitted in forecasting competitions)
|
||||
|
|
@ -21,16 +23,17 @@ Squiggle is still very early. The main first goal is to become stable. This mean
|
|||
- "Partial-domain" distributions. For example, maybe someone has a distribution for when AGI will happen, but doesn't want to make any estimates past 2200.
|
||||
|
||||
## Distribution Features
|
||||
``Distribution.fromSamples([])``
|
||||
|
||||
`Distribution.fromSamples([])`
|
||||
Converts a list of samples, for example, from Guesstimate, into a distribution shape. Maybe takes a list of optional parameters.
|
||||
|
||||
``Distribution.fromCoordinates({xs, ys})``
|
||||
`Distribution.fromCoordinates({xs, ys})`
|
||||
Convert XY coordinates into a distribution. Figure out a good way to do this for continuous, discrete, and mixed distributions.
|
||||
|
||||
[Metalog Distribution](https://en.wikipedia.org/wiki/Metalog_distribution)
|
||||
Add the Metalog distribution, and some convenient methods for generating these distributions. This might be a bit tricky because we might need or build a library to fit data. There's no Metalog javascript library yet, this would be pretty useful. There's already a Metalog library in Python, so that one could be used for inspiration.
|
||||
|
||||
``Distribution.smoothen(p)``
|
||||
`Distribution.smoothen(p)`
|
||||
Takes a distribution and smoothens it. For example, [Elicit Forecast](https://forecast.elicit.org/) does something like this, with uniform distributions.
|
||||
|
||||
## Major Future Additions
|
||||
|
|
@ -72,39 +75,39 @@ It might be useful to allow people to annotate functions and variables with long
|
|||
Right now, Monte Carlo simulations are totally random. It would be nicer to be able to enter a seed somehow in order to control the randomness. Or, with the same seed, the function should always return the same values. This would make debugging and similar easier.
|
||||
|
||||
## Major Standard Language Features
|
||||
|
||||
- Some testing story.
|
||||
- A custom code highlighting format.
|
||||
- Possibly a decent web GUI (a much more advanced playground).
|
||||
- A VS Code extention and similar.
|
||||
|
||||
## Bugs
|
||||
- Discrete distributions are particularly buggy. Try ``mm(1,2,3,4,5,6,7,8,9,10) .* (5 to 8)``
|
||||
|
||||
- Discrete distributions are particularly buggy. Try `mm(1,2,3,4,5,6,7,8,9,10) .* (5 to 8)`
|
||||
|
||||
## New Functions
|
||||
|
||||
### Distributions
|
||||
|
||||
```js
|
||||
cauchy()
|
||||
pareto()
|
||||
metalog()
|
||||
cauchy();
|
||||
pareto();
|
||||
metalog();
|
||||
```
|
||||
|
||||
Possibly change mm to mix, or mx(). Also, change input format, maybe to mx([a,b,c], [a,b,c]).
|
||||
|
||||
|
||||
### Functions
|
||||
|
||||
```js
|
||||
samples(distribution, n)
|
||||
toPdf(distribution)
|
||||
toCdf(distribution)
|
||||
toHash(distribution)
|
||||
trunctate(distribution, leftValue, rightValue)
|
||||
leftTrunctate(distribution, leftValue)
|
||||
rightTrunctate(distribution, rightValue)
|
||||
distributionFromSamples(array, params)
|
||||
distributionFromPoints()
|
||||
distributionFromHash()
|
||||
samples(distribution, n);
|
||||
toPdf(distribution);
|
||||
toCdf(distribution);
|
||||
toHash(distribution);
|
||||
trunctate(distribution, leftValue, rightValue);
|
||||
leftTrunctate(distribution, leftValue);
|
||||
rightTrunctate(distribution, rightValue);
|
||||
distributionFromSamples(array, params);
|
||||
distributionFromPoints();
|
||||
distributionFromHash();
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -5,8 +5,9 @@ sidebar_position: 3
|
|||
# Javascript Libraries
|
||||
|
||||
There are two JavaScript packages currently available for Squiggle:
|
||||
- [`@quri/squiggle-lang`](https://www.npmjs.com/package/@quri/squiggle-lang)
|
||||
- [`@quri/squiggle-components`](https://www.npmjs.com/package/@quri/squiggle-components)
|
||||
|
||||
- [`@quri/squiggle-lang`](https://www.npmjs.com/package/@quri/squiggle-lang)
|
||||
- [`@quri/squiggle-components`](https://www.npmjs.com/package/@quri/squiggle-components)
|
||||
|
||||
Types are available for both packages.
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
sidebar_position: 2
|
||||
---
|
||||
|
||||
import { SquiggleEditor } from '../src/components/SquiggleEditor'
|
||||
import { SquiggleEditor } from "../src/components/SquiggleEditor";
|
||||
|
||||
# Squiggle Language
|
||||
|
||||
|
|
@ -13,8 +13,10 @@ it is by simply looking at examples.
|
|||
|
||||
As an example:
|
||||
|
||||
<SquiggleEditor initialSquiggleString={`value_of_work = 10 to 70
|
||||
value_of_work`} />
|
||||
<SquiggleEditor
|
||||
initialSquiggleString={`value_of_work = 10 to 70
|
||||
value_of_work`}
|
||||
/>
|
||||
|
||||
Squiggle can declare variables (`value_of_work = 10 to 70`) and declare exports
|
||||
(the lone `value_of_work` line). Variables can be used later in a squiggle program
|
||||
|
|
@ -30,7 +32,8 @@ the exports can be expressions, such as:
|
|||
|
||||
Squiggle supports functions, including the rendering of functions:
|
||||
|
||||
<SquiggleEditor initialSquiggleString={`ozzie_estimate(t) = lognormal({mean: 3 + (t+.1)^2.5, stdev: 8})
|
||||
<SquiggleEditor
|
||||
initialSquiggleString={`ozzie_estimate(t) = lognormal({mean: 3 + (t+.1)^2.5, stdev: 8})
|
||||
ozzie_estimate
|
||||
`} />
|
||||
|
||||
`}
|
||||
/>
|
||||
|
|
|
|||
|
|
@ -2,6 +2,6 @@
|
|||
sidebar_position: 2
|
||||
---
|
||||
|
||||
import { SquigglePlayground } from '../src/components/SquigglePlayground'
|
||||
import { SquigglePlayground } from "../src/components/SquigglePlayground";
|
||||
|
||||
<SquigglePlayground initialSquiggleString="normal(0,1)"/>
|
||||
<SquigglePlayground initialSquiggleString="normal(0,1)" />
|
||||
|
|
|
|||
|
|
@ -4,16 +4,16 @@ sidebar_position: 5
|
|||
|
||||
# Three Formats of Distributions
|
||||
|
||||
*Author: Ozzie Gooen*
|
||||
*Written on: Feb 19, 2022*
|
||||
_Author: Ozzie Gooen_
|
||||
_Written on: Feb 19, 2022_
|
||||
|
||||
Probability distributions have several subtle possible formats. Three important ones that we deal with in Squiggle are symbolic, sample set, and graph formats.
|
||||
|
||||
_Symbolic_ formats are just the math equations. ``normal(5,3)`` is the symbolic representation of a normal distribution.
|
||||
_Symbolic_ formats are just the math equations. `normal(5,3)` is the symbolic representation of a normal distribution.
|
||||
|
||||
When you sample distributions (usually starting with symbolic formats), you get lists of samples. Monte Carlo techniques return lists of samples. Let’s call this the “_Sample Set_” format.
|
||||
|
||||
Lastly is what I’ll refer to as the _Graph_ format. It describes the coordinates, or the shape, of the distribution. You can save these formats in JSON, for instance, like, ``{xs: [1, 2, 3, 4…], ys: [.0001, .0003, .002, …]}``.
|
||||
Lastly is what I’ll refer to as the _Graph_ format. It describes the coordinates, or the shape, of the distribution. You can save these formats in JSON, for instance, like, `{xs: [1, 2, 3, 4…], ys: [.0001, .0003, .002, …]}`.
|
||||
|
||||
Symbolic, Sample Set, and Graph formats all have very different advantages and disadvantages.
|
||||
|
||||
|
|
@ -25,8 +25,8 @@ Note that the name "Symbolic" is fairly standard, but I haven't found common nam
|
|||
Mathematical representations. Require analytic solutions. These are often ideal where they can be applied, but apply to very few actual functions. Typically used sparsely, except for the starting distributions (before any computation is performed).
|
||||
|
||||
**Examples**
|
||||
```Normal(5,2)```
|
||||
```pdf(normal(2,5), 1.2) + beta(5, log(2))```
|
||||
`Normal(5,2)`
|
||||
`pdf(normal(2,5), 1.2) + beta(5, log(2))`
|
||||
|
||||
**How to Do Computation**
|
||||
To perform calculations of symbolic systems, you need to find analytical solutions. For example, there are equations to find the pdf or cdf of most distribution shapes at any point. There are also lots of simplifications that could be done in particular situations. For example, there’s an analytical solution for combining normal distributions.
|
||||
|
|
@ -35,25 +35,29 @@ To perform calculations of symbolic systems, you need to find analytical solutio
|
|||
The Metalog distribution seems like it can represent almost any reasonable distribution. It’s symbolic. This is great for storage, but it’s not clear if it helps with calculation. My impression is that we don’t have symbolic ways of doing most functions (addition, multiplication, etc) on metalog distributions. Also, note that it can take a fair bit of computation to fit a shape to the Metalog distribution.
|
||||
|
||||
**Advantages**
|
||||
* Maximally compressed; i.e. very easy to store.
|
||||
* Very readable.
|
||||
* When symbolic operations are feasible and easy to discover, they are trivially fast and completely accurate.
|
||||
|
||||
- Maximally compressed; i.e. very easy to store.
|
||||
- Very readable.
|
||||
- When symbolic operations are feasible and easy to discover, they are trivially fast and completely accurate.
|
||||
|
||||
**Disadvantages**
|
||||
* It’s often either impossible or computationally infeasible to find analytical solutions to most symbolic equations.
|
||||
* Solving symbolic equations requires very specialized tooling that’s very rare. There are a few small symbolic solver libraries out there, but not many. Wolfram Research is the main group that seems very strong here, and their work is mostly closed source + expensive.
|
||||
|
||||
- It’s often either impossible or computationally infeasible to find analytical solutions to most symbolic equations.
|
||||
- Solving symbolic equations requires very specialized tooling that’s very rare. There are a few small symbolic solver libraries out there, but not many. Wolfram Research is the main group that seems very strong here, and their work is mostly closed source + expensive.
|
||||
|
||||
**Converting to Graph Formats**
|
||||
* Very easy. Choose X points such that you capture most of the distribution (you can set a threshold, like 99.9%). For each X point, calculate the pdf, and save as the Y points.
|
||||
|
||||
- Very easy. Choose X points such that you capture most of the distribution (you can set a threshold, like 99.9%). For each X point, calculate the pdf, and save as the Y points.
|
||||
|
||||
**Converting to Sample List Formats**
|
||||
* Very easy. Just sample a bunch of times. The regular way is to randomly sample (This is trivial to do for all distributions with inverse-cdf functions.) If you want to get more fancy, you could provide extra samples from the tails, that would be weighted lower. Or, you could take samples in equal distances (of probability mass) along the entire distribution, then optionally shuffle it. (In the latter case, these would not be random samples, but sometimes that’s fine.)
|
||||
|
||||
- Very easy. Just sample a bunch of times. The regular way is to randomly sample (This is trivial to do for all distributions with inverse-cdf functions.) If you want to get more fancy, you could provide extra samples from the tails, that would be weighted lower. Or, you could take samples in equal distances (of probability mass) along the entire distribution, then optionally shuffle it. (In the latter case, these would not be random samples, but sometimes that’s fine.)
|
||||
|
||||
**How to Visualize**
|
||||
Convert to graph, then display that. (Optionally, you can also convert to samples, then display those using a histogram, but this is often worse you have both options.)
|
||||
|
||||
|
||||
## Graph Formats
|
||||
|
||||
**TLDR**
|
||||
Lists of the x-y coordinates of the shape of a distribution. (Usually the pdf, which is more compressed than the cdf). Some key functions (like pdf, cdf) and manipulations can work on almost any graphally-described distribution.
|
||||
|
||||
|
|
@ -65,37 +69,44 @@ See [this facebook thread](https://www.facebook.com/ozzie.gooen/posts/1016593626
|
|||
Use graph techniques. These can be fairly computationally-intensive (particularly finding integrals, which take a whole lot of adding). In the case that you want to multiply independent distributions, you can try convolution, but it’s pretty expensive.
|
||||
|
||||
**Examples**
|
||||
``{xs: [1, 2, 3, 4…], ys: [.0001, .0003, .002, .04, ...]} ``
|
||||
``[[1, .0001], [2, .0003], [3, .002]...] ``
|
||||
`{xs: [1, 2, 3, 4…], ys: [.0001, .0003, .002, .04, ...]} `
|
||||
`[[1, .0001], [2, .0003], [3, .002]...] `
|
||||
|
||||
**Advantages**
|
||||
* Much more compressed than Sample List formats, but much less compressed than Symbolic formats.
|
||||
* Many functions (pdf, cdf, percentiles, mean, integration, etc) and manipulations (truncation, scaling horizontally or vertically), are possible on essentially all graph distributions.
|
||||
|
||||
- Much more compressed than Sample List formats, but much less compressed than Symbolic formats.
|
||||
- Many functions (pdf, cdf, percentiles, mean, integration, etc) and manipulations (truncation, scaling horizontally or vertically), are possible on essentially all graph distributions.
|
||||
|
||||
**Disadvantages**
|
||||
* Most calculations are infeasible/impossible to perform graphally. In these cases, you need to use sampling.
|
||||
* Not as accurate or fast as symbolic methods, where the symbolic methods are applicable.
|
||||
* The tails get cut off, which is subideal. It’s assumed that the value of the pdf outside of the bounded range is exactly 0, which is not correct. (Note: If you have ideas on how to store graph formats that don’t cut off tails, let me know)
|
||||
|
||||
- Most calculations are infeasible/impossible to perform graphally. In these cases, you need to use sampling.
|
||||
- Not as accurate or fast as symbolic methods, where the symbolic methods are applicable.
|
||||
- The tails get cut off, which is subideal. It’s assumed that the value of the pdf outside of the bounded range is exactly 0, which is not correct. (Note: If you have ideas on how to store graph formats that don’t cut off tails, let me know)
|
||||
|
||||
**Converting to Symbolic Formats**
|
||||
* Okay, if you are okay with a Metalog approximation or similar. Metaculus uses an additive combination of up to [Logistic distributions](https://www.metaculus.com/help/faq/); you could also fit this. Fitting takes a little time (it requires several attempts and some optimization), can be arbitrarily accurate.
|
||||
* If you want to be very fancy, you could try to fit graph distributions into normal / lognormal / etc. but this seems like a lot of work for little gain.
|
||||
|
||||
- Okay, if you are okay with a Metalog approximation or similar. Metaculus uses an additive combination of up to [Logistic distributions](https://www.metaculus.com/help/faq/); you could also fit this. Fitting takes a little time (it requires several attempts and some optimization), can be arbitrarily accurate.
|
||||
- If you want to be very fancy, you could try to fit graph distributions into normal / lognormal / etc. but this seems like a lot of work for little gain.
|
||||
|
||||
**Converting to Sample List Formats**
|
||||
* Just sample a lot. The same as converting symbolic formats into samples.
|
||||
|
||||
- Just sample a lot. The same as converting symbolic formats into samples.
|
||||
|
||||
**How to Visualize**
|
||||
* It’s already in a good format for visualization, just plot it in any library.
|
||||
|
||||
- It’s already in a good format for visualization, just plot it in any library.
|
||||
|
||||
**Handling Long Tails / Optimization**
|
||||
* You can choose specific points to use to save computation. For example, taking extra points at the ends.
|
||||
|
||||
- You can choose specific points to use to save computation. For example, taking extra points at the ends.
|
||||
|
||||
**Additional Metadata**
|
||||
* The format mentioned above does not suggest any specific form of interpolation, or strategy of dealing with the tails. Several interpolation methods are possible; for example, linear interpolation, or stepwise interpolation.
|
||||
|
||||
- The format mentioned above does not suggest any specific form of interpolation, or strategy of dealing with the tails. Several interpolation methods are possible; for example, linear interpolation, or stepwise interpolation.
|
||||
|
||||
**Potential Alternatives**
|
||||
* [Bézier curves](https://en.wikipedia.org/wiki/B%C3%A9zier_curve) could, in theory, be more optimal. Bézier are used for vector image programs. They represent a more complicated format than a list of x-y coordinate pairs, but come with much more flexibility. Arguably, they sit somewhere between fitting distributions to Metalog distributions, and just taking many x-y points.
|
||||
|
||||
- [Bézier curves](https://en.wikipedia.org/wiki/B%C3%A9zier_curve) could, in theory, be more optimal. Bézier are used for vector image programs. They represent a more complicated format than a list of x-y coordinate pairs, but come with much more flexibility. Arguably, they sit somewhere between fitting distributions to Metalog distributions, and just taking many x-y points.
|
||||
|
||||
## Sample Set Formats
|
||||
|
||||
|
|
@ -106,19 +117,21 @@ Random samples. Use Monte Carlo simulation to perform calculations. This is the
|
|||
Use [Monte Carlo methods](https://en.wikipedia.org/wiki/Monte_Carlo_method). You could get fancy with these with a [probabilistic programming language](https://en.wikipedia.org/wiki/Probabilistic_programming), which often have highly optimized Monte Carlo tooling. Variational inference is used for very similar problems.
|
||||
|
||||
**Examples**
|
||||
``[3.23848, 4.82081, 1.382833, 9.238383…]``
|
||||
`[3.23848, 4.82081, 1.382833, 9.238383…]`
|
||||
|
||||
**Advantages**
|
||||
* Monte Carlo methods are effectively the only ways to calculate many/most functions.
|
||||
* The use of Monte Carlo methods make for very easy sensitivity analysis.
|
||||
* [Probabilistic inference](https://machinelearningmastery.com/markov-chain-monte-carlo-for-probability/) is only possible using Monte Carlo methods.
|
||||
* In some cases, Monte Carlo computation functionally represents possible worlds. There’s no very clear line between Monte Carlo methods and agent based modeling simulations.
|
||||
* You can handle math with distributions that are correlated with each other. (I believe, but am not sure).
|
||||
|
||||
- Monte Carlo methods are effectively the only ways to calculate many/most functions.
|
||||
- The use of Monte Carlo methods make for very easy sensitivity analysis.
|
||||
- [Probabilistic inference](https://machinelearningmastery.com/markov-chain-monte-carlo-for-probability/) is only possible using Monte Carlo methods.
|
||||
- In some cases, Monte Carlo computation functionally represents possible worlds. There’s no very clear line between Monte Carlo methods and agent based modeling simulations.
|
||||
- You can handle math with distributions that are correlated with each other. (I believe, but am not sure).
|
||||
|
||||
**Disadvantages**
|
||||
* Monte Carlo methods can be very slow.
|
||||
* Requires fairly heavy tooling to make efficient.
|
||||
* Sampling methods are very lossy, especially for tails.
|
||||
|
||||
- Monte Carlo methods can be very slow.
|
||||
- Requires fairly heavy tooling to make efficient.
|
||||
- Sampling methods are very lossy, especially for tails.
|
||||
|
||||
**Converting to Symbolic Formats**
|
||||
I don’t know of a straightforward way of doing this. Convert to Sample List first, then you can convert to Metalog or similar.
|
||||
|
|
@ -127,17 +140,16 @@ I don’t know of a straightforward way of doing this. Convert to Sample List fi
|
|||
[Kernel density estimation](https://en.wikipedia.org/wiki/Kernel_density_estimation) works. However, it requires a few parameters from the user, for tuning. There are functions to estimate these parameters, but this is tricky. Two forms of density estimation are shown as code [here](https://github.com/jasondavies/science.js/blob/master/src/stats/bandwidth.js). There’s some more description in the webppl documentation [here](https://webppl.readthedocs.io/en/master/distributions.html#KDE).
|
||||
|
||||
**Handling Long Tails / Optimization**
|
||||
* You can weight samples differently. This allows you to save more at the tails, for more granularity there, without biasing the results. (I’m not sure how difficult this would be.)
|
||||
|
||||
- You can weight samples differently. This allows you to save more at the tails, for more granularity there, without biasing the results. (I’m not sure how difficult this would be.)
|
||||
|
||||
**How to Visualize**
|
||||
Use a histogram.
|
||||
|
||||
|
||||
|
||||
| | Symbolic | Symbolic(metalog) | Numeric | Samples/MC |
|
||||
|------------------------|--------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------|------------------------------------------------------------------------------------------------|-------------------------------------|
|
||||
| ---------------------- | ------------------------------------------------------------------------------------------------------------------------ | ----------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- | ----------------------------------------------------------- |
|
||||
| Example | normal(5,2) | metalog([(2,3)]) | [[1,2,3,4], [3,5,9,10]] | [1.38483, 0.233, 38.8383, …] |
|
||||
| Techniques | Analytic | Analytic | Numeric | Monte Carlo, variational inference |
|
||||
| Available calculations | Pdf(), cdf(), sample, inverse Add or multiply normal distributions Add lognormal distributions Select other calculations | Pdf(), cdf(), sample(), inverseCdf() | Pointwise operations Truncate Mixture Select regular operations by constants (normal(5,2) * 3) | Normal operations, most functions. Not pointwise functions. |
|
||||
| Available calculations | Pdf(), cdf(), sample, inverse Add or multiply normal distributions Add lognormal distributions Select other calculations | Pdf(), cdf(), sample(), inverseCdf() | Pointwise operations Truncate Mixture Select regular operations by constants (normal(5,2) \* 3) | Normal operations, most functions. Not pointwise functions. |
|
||||
| Use for computation | Lossless, Very fast, Extremely limited | | Medium speed, Minor accuracy loss, Select useful, but limited functions | Slow and lossy, but very general-purpose. |
|
||||
| Use for storage | Tiny, Lossless, Extremely limited | (Assuming other data is fit to metalog) High information densityt | Medium information density | Low information density |
|
||||
|
|
|
|||
|
|
@ -1,56 +1,62 @@
|
|||
// @ts-check
|
||||
// Note: type annotations allow type checking and IDEs autocompletion
|
||||
|
||||
const lightCodeTheme = require('prism-react-renderer/themes/github');
|
||||
const darkCodeTheme = require('prism-react-renderer/themes/dracula');
|
||||
const path = require('path');
|
||||
const lightCodeTheme = require("prism-react-renderer/themes/github");
|
||||
const darkCodeTheme = require("prism-react-renderer/themes/dracula");
|
||||
const path = require("path");
|
||||
|
||||
/** @type {import('@docusaurus/types').Config} */
|
||||
const config = {
|
||||
title: 'Squiggle (alpha)',
|
||||
title: "Squiggle (alpha)",
|
||||
tagline: "Estimation language for forecasters",
|
||||
url: 'https://squiggle-language.com',
|
||||
baseUrl: '/',
|
||||
onBrokenLinks: 'throw',
|
||||
onBrokenMarkdownLinks: 'warn',
|
||||
favicon: 'img/favicon.ico',
|
||||
organizationName: 'QURIResearch', // Usually your GitHub org/user name.
|
||||
projectName: 'squiggle', // Usually your repo name.
|
||||
url: "https://squiggle-language.com",
|
||||
baseUrl: "/",
|
||||
onBrokenLinks: "throw",
|
||||
onBrokenMarkdownLinks: "warn",
|
||||
favicon: "img/favicon.ico",
|
||||
organizationName: "QURIResearch", // Usually your GitHub org/user name.
|
||||
projectName: "squiggle", // Usually your repo name.
|
||||
|
||||
plugins: [
|
||||
() => ({
|
||||
configureWebpack(config, isServer, utils, content) {
|
||||
return {
|
||||
resolve: {
|
||||
alias : {
|
||||
"@quri/squiggle-components": path.resolve(__dirname, "../components/src"),
|
||||
"@quri/squiggle-lang": path.resolve(__dirname, "../squiggle-lang/src/js")
|
||||
}
|
||||
}
|
||||
|
||||
alias: {
|
||||
"@quri/squiggle-components": path.resolve(
|
||||
__dirname,
|
||||
"../components/src"
|
||||
),
|
||||
"@quri/squiggle-lang": path.resolve(
|
||||
__dirname,
|
||||
"../squiggle-lang/src/js"
|
||||
),
|
||||
},
|
||||
},
|
||||
};
|
||||
}
|
||||
})
|
||||
},
|
||||
}),
|
||||
],
|
||||
|
||||
presets: [
|
||||
[
|
||||
'classic',
|
||||
"classic",
|
||||
/** @type {import('@docusaurus/preset-classic').Options} */
|
||||
({
|
||||
docs: {
|
||||
sidebarPath: require.resolve('./sidebars.js'),
|
||||
sidebarPath: require.resolve("./sidebars.js"),
|
||||
// Please change this to your repo.
|
||||
editUrl: 'https://github.com/foretold-app/squiggle/tree/main/packages/website/',
|
||||
editUrl:
|
||||
"https://github.com/foretold-app/squiggle/tree/main/packages/website/",
|
||||
},
|
||||
blog: {
|
||||
showReadingTime: true,
|
||||
// Please change this to your repo.
|
||||
editUrl:
|
||||
'https://github.com/foretold-app/squiggle/tree/main/packages/website/',
|
||||
"https://github.com/foretold-app/squiggle/tree/main/packages/website/",
|
||||
},
|
||||
theme: {
|
||||
customCss: require.resolve('./src/css/custom.css'),
|
||||
customCss: require.resolve("./src/css/custom.css"),
|
||||
},
|
||||
}),
|
||||
],
|
||||
|
|
@ -60,54 +66,54 @@ const config = {
|
|||
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */
|
||||
({
|
||||
navbar: {
|
||||
title: 'Squiggle',
|
||||
title: "Squiggle",
|
||||
logo: {
|
||||
alt: 'Squiggle Logo',
|
||||
src: 'img/logo.svg',
|
||||
alt: "Squiggle Logo",
|
||||
src: "img/logo.svg",
|
||||
},
|
||||
items: [
|
||||
{
|
||||
type: 'doc',
|
||||
docId: 'Introduction',
|
||||
position: 'left',
|
||||
label: 'Documentation',
|
||||
type: "doc",
|
||||
docId: "Introduction",
|
||||
position: "left",
|
||||
label: "Documentation",
|
||||
},
|
||||
{to: '/blog', label: 'Blog', position: 'left'},
|
||||
{ to: "/blog", label: "Blog", position: "left" },
|
||||
{
|
||||
type: 'doc',
|
||||
docId: 'Playground',
|
||||
label: 'Playground',
|
||||
position: 'left'
|
||||
type: "doc",
|
||||
docId: "Playground",
|
||||
label: "Playground",
|
||||
position: "left",
|
||||
},
|
||||
{
|
||||
href: 'https://github.com/QURIresearch/squiggle',
|
||||
label: 'GitHub',
|
||||
position: 'right',
|
||||
href: "https://github.com/QURIresearch/squiggle",
|
||||
label: "GitHub",
|
||||
position: "right",
|
||||
},
|
||||
],
|
||||
},
|
||||
footer: {
|
||||
style: 'dark',
|
||||
style: "dark",
|
||||
links: [
|
||||
{
|
||||
title: 'Blog',
|
||||
title: "Blog",
|
||||
items: [
|
||||
{
|
||||
label: 'Overview',
|
||||
to: '/docs/Language',
|
||||
label: "Overview",
|
||||
to: "/docs/Language",
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'More',
|
||||
title: "More",
|
||||
items: [
|
||||
{
|
||||
label: 'Blog',
|
||||
to: '/blog',
|
||||
label: "Blog",
|
||||
to: "/blog",
|
||||
},
|
||||
{
|
||||
label: 'GitHub',
|
||||
href: 'https://github.com/QURIresearch/squiggle',
|
||||
label: "GitHub",
|
||||
href: "https://github.com/QURIresearch/squiggle",
|
||||
},
|
||||
],
|
||||
},
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
|
||||
const sidebars = {
|
||||
// By default, Docusaurus generates a sidebar from the docs folder structure
|
||||
tutorialSidebar: [{type: 'autogenerated', dirName: '.'}],
|
||||
tutorialSidebar: [{ type: "autogenerated", dirName: "." }],
|
||||
|
||||
// But you can create a sidebar manually
|
||||
/*
|
||||
|
|
|
|||
|
|
@ -1,37 +1,37 @@
|
|||
import React from 'react';
|
||||
import clsx from 'clsx';
|
||||
import styles from './HomepageFeatures.module.css';
|
||||
import React from "react";
|
||||
import clsx from "clsx";
|
||||
import styles from "./HomepageFeatures.module.css";
|
||||
|
||||
const FeatureList = [
|
||||
{
|
||||
title: 'Probabilistic',
|
||||
title: "Probabilistic",
|
||||
description: (
|
||||
<>Squiggle makes working with probability distributions really easy.</>
|
||||
),
|
||||
},
|
||||
{
|
||||
title: "Portable",
|
||||
description: (
|
||||
<>
|
||||
Squiggle makes working with probability distributions really easy.
|
||||
Squiggle is in a small Rescript / Javascript library. It can be used
|
||||
wherever Rescript and Javascript are available.
|
||||
</>
|
||||
),
|
||||
},
|
||||
{
|
||||
title: 'Portable',
|
||||
title: "Fast",
|
||||
description: (
|
||||
<>
|
||||
Squiggle is in a small Rescript / Javascript library. It can be used wherever Rescript and Javascript are available.
|
||||
</>
|
||||
),
|
||||
},
|
||||
{
|
||||
title: 'Fast',
|
||||
description: (
|
||||
<>
|
||||
Squiggle tries to get as far as it can without resorting to Monte Carlo simulation, but does so when necessary.
|
||||
Squiggle tries to get as far as it can without resorting to Monte Carlo
|
||||
simulation, but does so when necessary.
|
||||
</>
|
||||
),
|
||||
},
|
||||
];
|
||||
|
||||
function Feature({Svg, title, description}) {
|
||||
function Feature({ Svg, title, description }) {
|
||||
return (
|
||||
<div className={clsx('col col--4')}>
|
||||
<div className={clsx("col col--4")}>
|
||||
<div className="text--center padding-horiz--md">
|
||||
<h3>{title}</h3>
|
||||
<p>{description}</p>
|
||||
|
|
|
|||
|
|
@ -1,11 +1,11 @@
|
|||
import BrowserOnly from '@docusaurus/BrowserOnly';
|
||||
import BrowserOnly from "@docusaurus/BrowserOnly";
|
||||
|
||||
export function SquiggleEditor(props) {
|
||||
return (
|
||||
<BrowserOnly fallback={<div>Loading...</div>}>
|
||||
{() => {
|
||||
const LibComponent =
|
||||
require('@quri/squiggle-components').SquiggleEditor;
|
||||
require("@quri/squiggle-components").SquiggleEditor;
|
||||
return <LibComponent {...props} />;
|
||||
}}
|
||||
</BrowserOnly>
|
||||
|
|
|
|||
|
|
@ -1,11 +1,11 @@
|
|||
import BrowserOnly from '@docusaurus/BrowserOnly';
|
||||
import BrowserOnly from "@docusaurus/BrowserOnly";
|
||||
|
||||
export function SquigglePlayground(props) {
|
||||
return (
|
||||
<BrowserOnly fallback={<div>Loading...</div>}>
|
||||
{() => {
|
||||
const LibComponent =
|
||||
require('@quri/squiggle-components').SquigglePlayground;
|
||||
require("@quri/squiggle-components").SquigglePlayground;
|
||||
return <LibComponent {...props} />;
|
||||
}}
|
||||
</BrowserOnly>
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@
|
|||
}
|
||||
|
||||
/* For readability concerns, you should choose a lighter palette in dark mode. */
|
||||
html[data-theme='dark'] {
|
||||
html[data-theme="dark"] {
|
||||
--ifm-color-primary: #25c2a0;
|
||||
--ifm-color-primary-dark: #21af90;
|
||||
--ifm-color-primary-darker: #1fa588;
|
||||
|
|
@ -34,6 +34,6 @@ html[data-theme='dark'] {
|
|||
padding: 0 var(--ifm-pre-padding);
|
||||
}
|
||||
|
||||
html[data-theme='dark'] .docusaurus-highlight-code-line {
|
||||
html[data-theme="dark"] .docusaurus-highlight-code-line {
|
||||
background-color: rgba(0, 0, 0, 0.3);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,31 +1,31 @@
|
|||
import React from 'react';
|
||||
import clsx from 'clsx';
|
||||
import Layout from '@theme/Layout';
|
||||
import Link from '@docusaurus/Link';
|
||||
import useDocusaurusContext from '@docusaurus/useDocusaurusContext';
|
||||
import styles from './index.module.css';
|
||||
import HomepageFeatures from '../components/HomepageFeatures';
|
||||
import React from "react";
|
||||
import clsx from "clsx";
|
||||
import Layout from "@theme/Layout";
|
||||
import Link from "@docusaurus/Link";
|
||||
import useDocusaurusContext from "@docusaurus/useDocusaurusContext";
|
||||
import styles from "./index.module.css";
|
||||
import HomepageFeatures from "../components/HomepageFeatures";
|
||||
|
||||
function HomepageHeader() {
|
||||
const {siteConfig} = useDocusaurusContext();
|
||||
const { siteConfig } = useDocusaurusContext();
|
||||
return (
|
||||
<header className={clsx('hero hero--primary', styles.heroBanner)}>
|
||||
<header className={clsx("hero hero--primary", styles.heroBanner)}>
|
||||
<div className="container">
|
||||
<h1 className="hero__title">{siteConfig.title}</h1>
|
||||
<p className="hero__subtitle">{siteConfig.tagline}</p>
|
||||
<div className={styles.buttons}>
|
||||
</div>
|
||||
<div className={styles.buttons}></div>
|
||||
</div>
|
||||
</header>
|
||||
);
|
||||
}
|
||||
|
||||
export default function Home() {
|
||||
const {siteConfig} = useDocusaurusContext();
|
||||
const { siteConfig } = useDocusaurusContext();
|
||||
return (
|
||||
<Layout
|
||||
title={`Hello from ${siteConfig.title}`}
|
||||
description="Description will go into a meta tag in <head />">
|
||||
description="Description will go into a meta tag in <head />"
|
||||
>
|
||||
<HomepageHeader />
|
||||
<main>
|
||||
<HomepageFeatures />
|
||||
|
|
|
|||
Loading…
Reference in New Issue
Block a user