| data | ||
| node_modules | ||
| src | ||
| .gitignore | ||
| metaforecasts.png | ||
| package-lock.json | ||
| package.json | ||
| README.md | ||
{kind=link}
What this is
This is a set of libraries and a command line interface that fetches probabilities/forecasts from prediction markets and forecasting platforms.
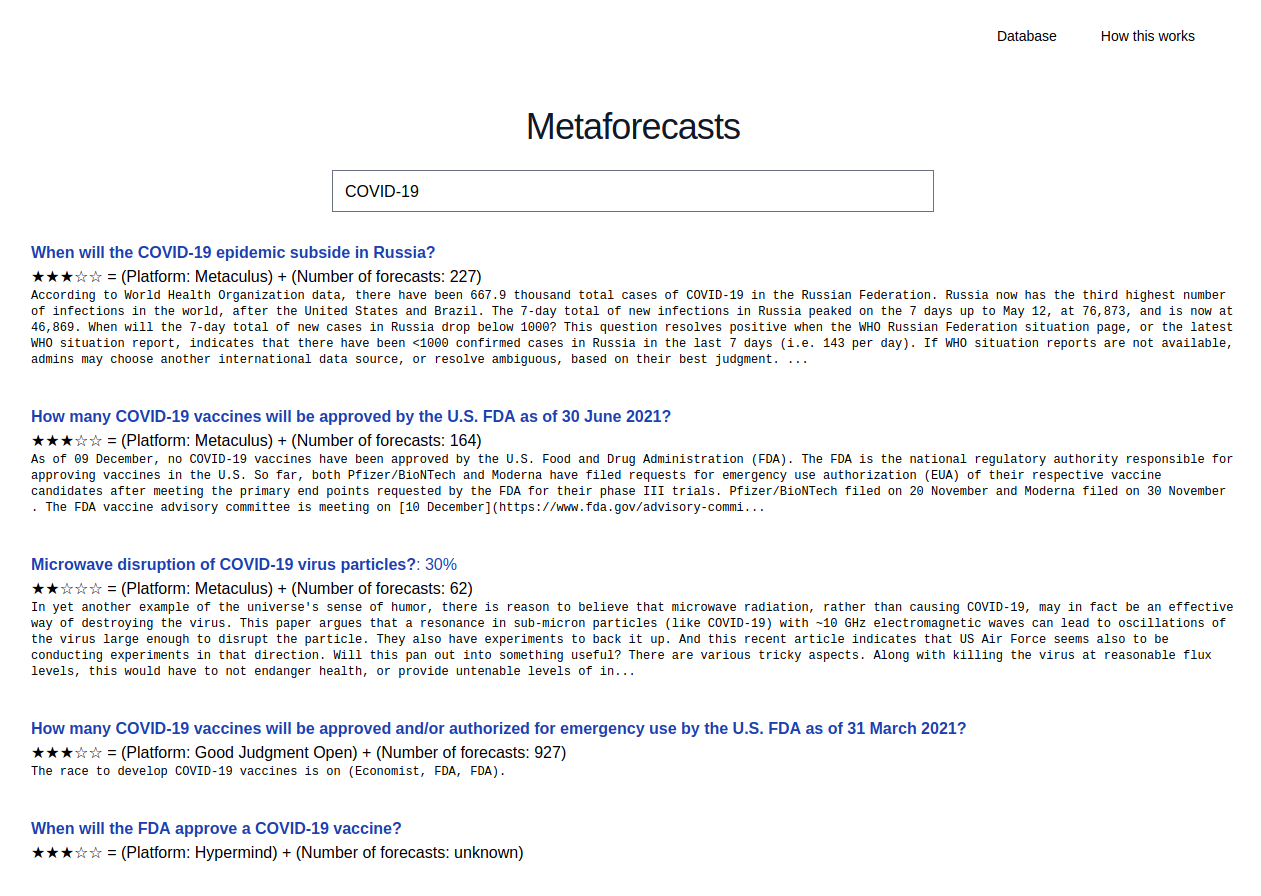
These forecasts are then used to power a search engine for probabilities, which can be found here (try searching "Trump", "China" or "Semiconductors") (source code here). A json endpoint can be found here.
I also created a search engine using Elicit's IDE, which uses GPT-3 to deliver vastly superior semantic search (as opposed to fuzzy word matching). If you have access to the Elicit IDE, you can use the action "Search Metaforecast database".
How to run
1. Download this repository
git clone https://github.com/QURIresearch/metaforecasts
2. Enter your own cookies
Private session cookies are necessary to query CSET-foretell, Good Judgment Open and Hypermind. You can get these cookies by creating an account in said platforms and then making and inspecting a request (e.g., by making a prediction, or browsing questions). After doing this, you should create a src/privatekeys.json, in the same format as src/privatekeys_example.json
3. Actually run
From the top level directory, enter: npm run start
What are "stars" and how are they computed
Star ratings—e.g. ★★★☆☆—are an indicator of the quality of an aggregate forecast for a question. These ratings currently try to reflect my own best judgment based on my experience forecasting on these platforms. Thus, stars have a strong subjective component which could be formalized and refined in the future.
Currently, stars are computed using a simple rule dependent on both the platform and the number of forecasts:
- CSET-foretell: ★★☆☆☆, but ★☆☆☆☆ if a question has less than 100 forecasts
- Elicit: ★☆☆☆☆
- Good Judgment (various superforecaster dashboards): ★★★★☆
- Good Judgment Open: ★★★☆☆, ★★☆☆☆ if a question has less than 100 forecasts
- Hypermind: ★★★☆☆
- Metaculus: ★★★★☆ if a question has more than 300 forecasts, ★★★☆☆ if it has more than 100, ★★☆☆☆ otherwise.
- Omen: ★☆☆☆☆
- Polymarket: ★★☆☆☆
- PredictIt: ★★☆☆☆
Various notes
- Right now, I'm fetching only a couple of common properties, such as the title, url, platform, whether a question is binary (yes/no), its percentage, and the number of forecasts. However, the code contains more fields commented out, such as trade volume, liquidity, etc.
- A note as to quality: Tentatively, Good Judgment >> Good Judgment Open ~ Metaculus > CSET > PredictIt ~> Polymarket >> Elicit > Omen.
- I'm not really sure where Hypermind falls in that spectrum.
- Prediction markets rarely go above 95% or below 5%.
- For elicit and metaculus, this library currently filters questions with <10 predictions.
- Omen does have very few active predictions at the moment; this is not a mistake.