update imgur stuff
{kind=link}
|
Before Width: | Height: | Size: 131 KiB After Width: | Height: | Size: 131 KiB |
{kind=link}
|
Before Width: | Height: | Size: 85 KiB After Width: | Height: | Size: 85 KiB |
{kind=link}
|
Before Width: | Height: | Size: 114 KiB After Width: | Height: | Size: 114 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB After Width: | Height: | Size: 15 KiB |
|
|
@ -39,11 +39,11 @@ A two-sentence version would be:
|
|||
|
||||
> Forecasters predicted the conclusions that would be reached by Elizabeth van Norstrand, a generalist researcher, before she conducted a study on the accuracy of various historical claims. We randomly sampled a subset of research claims for her to evaluate, and since we can set that probability arbitrarily low this method is not bottlenecked by her time.
|
||||
|
||||

|
||||
|
||||
|
||||
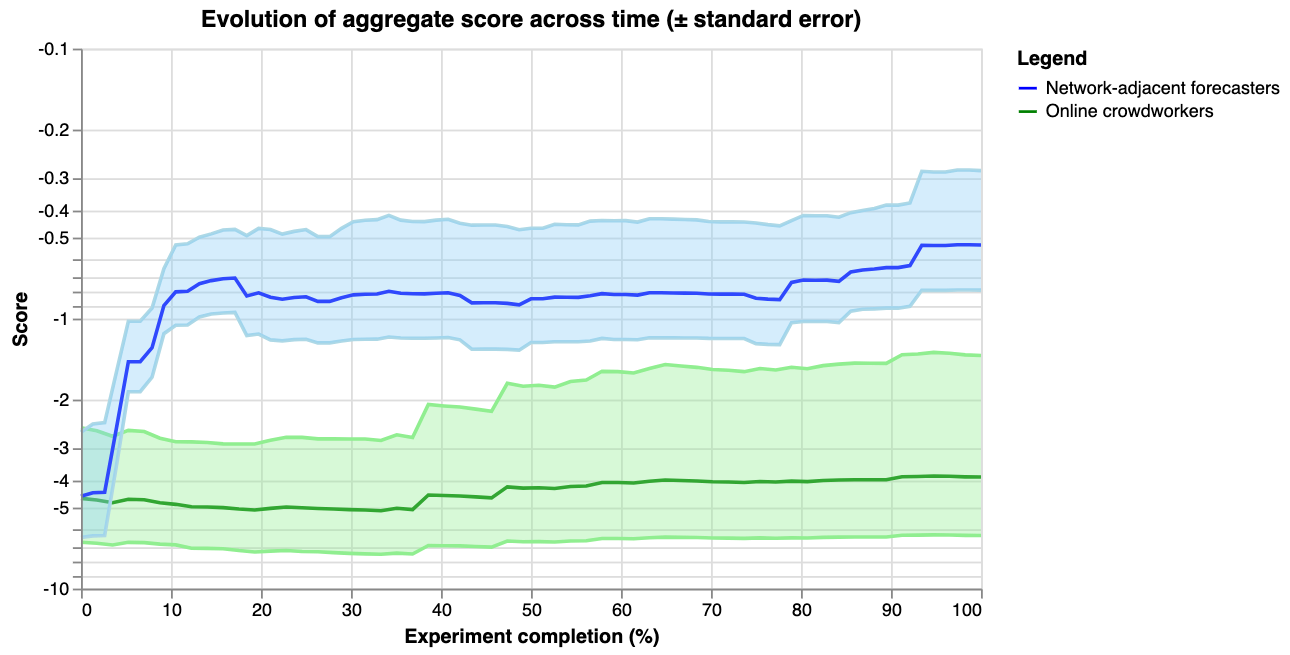
The below graph shows the evolution of the accuracy of the crowd prediction over time, starting from Elizabeth Van Nostrand’s prior. Predictions were submitted separately by two groups of forecasters: one based on a mailing list with participants interested in participating in forecasting experiments (recruited from effective altruism-adjacent events and other forecasting platforms), and one recruited from Positly, an online platform for crowdworkers.
|
||||
|
||||

|
||||
|
||||
|
||||
The y-axis shows the accuracy score on a logarithmic scale, and the x-axis shows how far along the experiment is. For example, 14 out of 28 days would correspond to 50%. The thick lines show the average score of the aggregate prediction, across all questions, at each time-point. The shaded areas show the standard error of the scores, so that the graph might be interpreted as a guess of how the two communities would predict a random new question.
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ We measured “value provided” as the reduction in uncertainty weighted by the
|
|||
|
||||
Results were as follows.
|
||||
|
||||

|
||||

|
||||
|
||||
In other words, each unit of resource invested in the network-adjacent forecasters provided 72% as much returns as investing it in Elizabeth directly, and each unit invested in the crowdworkers provided negative returns, as they tended to be less accurate than Elizabeth’s prior.
|
||||
|
||||
|
|
@ -229,7 +229,7 @@ For future experiments, we’re considering obtaining an objective data-set with
|
|||
|
||||
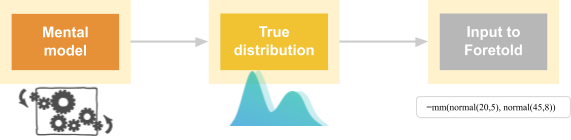
In order to participate in the experiment, a forecaster has to turn their mental models (represented in whichever way the human brain represents models) into quantitative distributions (which is a format quite unlike that native to our brains), as shown in the following diagram:
|
||||
|
||||

|
||||
|
||||
|
||||
Each step in this chain is quite challenging, requires much practice to master, and can result in a loss of information.
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 379 KiB After Width: | Height: | Size: 379 KiB |
{kind=link}
|
Before Width: | Height: | Size: 131 KiB After Width: | Height: | Size: 131 KiB |
{kind=link}
|
Before Width: | Height: | Size: 85 KiB After Width: | Height: | Size: 85 KiB |
{kind=link}
|
Before Width: | Height: | Size: 269 KiB After Width: | Height: | Size: 269 KiB |
{kind=link}
|
Before Width: | Height: | Size: 177 KiB After Width: | Height: | Size: 177 KiB |
{kind=link}
|
Before Width: | Height: | Size: 131 KiB After Width: | Height: | Size: 131 KiB |
{kind=link}
|
Before Width: | Height: | Size: 164 KiB After Width: | Height: | Size: 164 KiB |
{kind=link}
|
Before Width: | Height: | Size: 164 KiB After Width: | Height: | Size: 164 KiB |
{kind=link}
|
Before Width: | Height: | Size: 361 KiB After Width: | Height: | Size: 361 KiB |
{kind=link}
|
Before Width: | Height: | Size: 114 KiB After Width: | Height: | Size: 114 KiB |
{kind=link}
|
Before Width: | Height: | Size: 48 KiB After Width: | Height: | Size: 48 KiB |
|
|
@ -37,7 +37,7 @@ A two-sentence version would be:
|
|||
|
||||
> Forecasters predicted the conclusions that would be reached by Elizabeth van Norstrand, a generalist researcher, before she conducted a study on the accuracy of various historical claims. We randomly sampled a subset of research claims for her to evaluate, and since we can set that probability arbitrarily low this method is not bottlenecked by her time.
|
||||
|
||||

|
||||
|
||||
|
||||
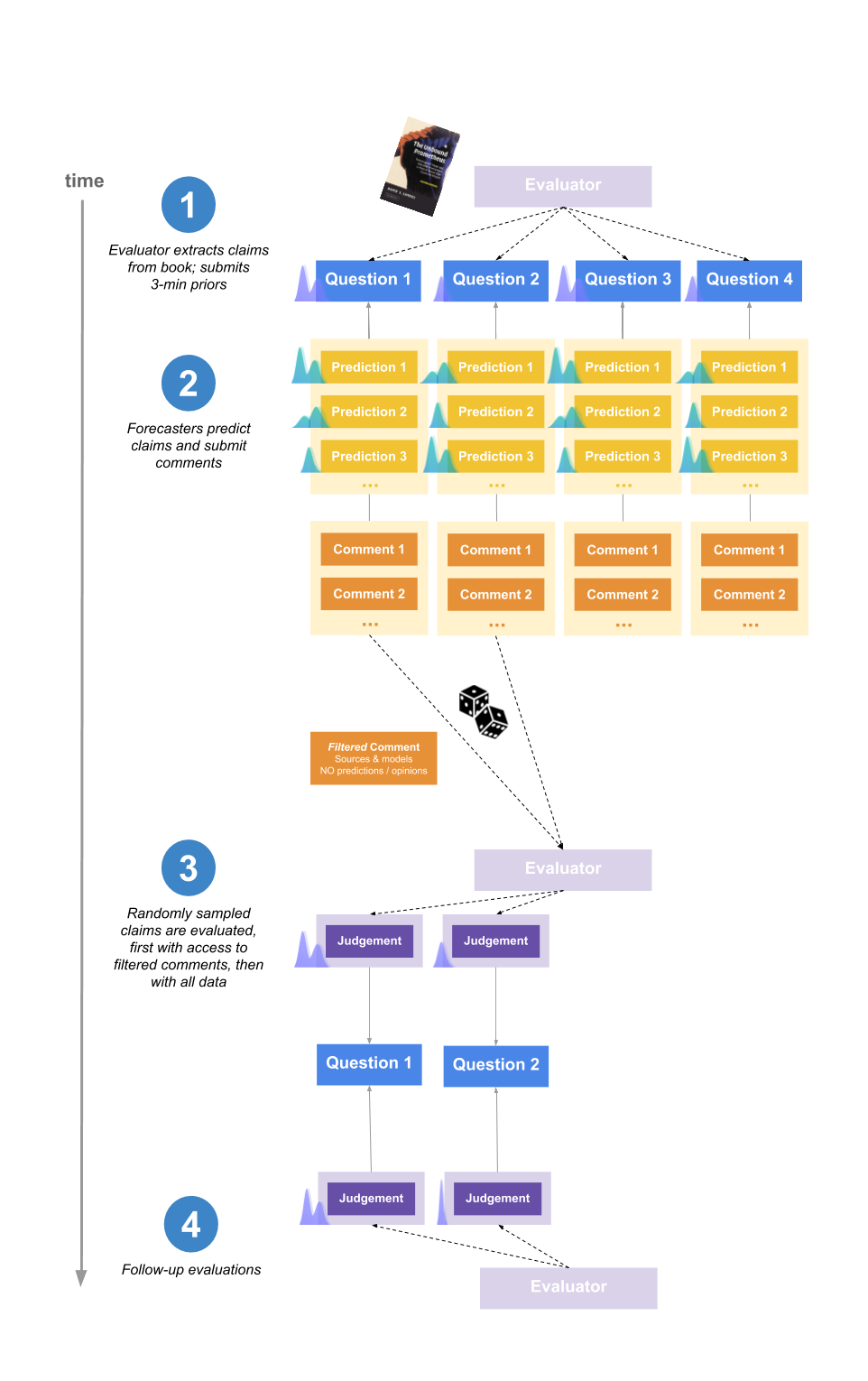
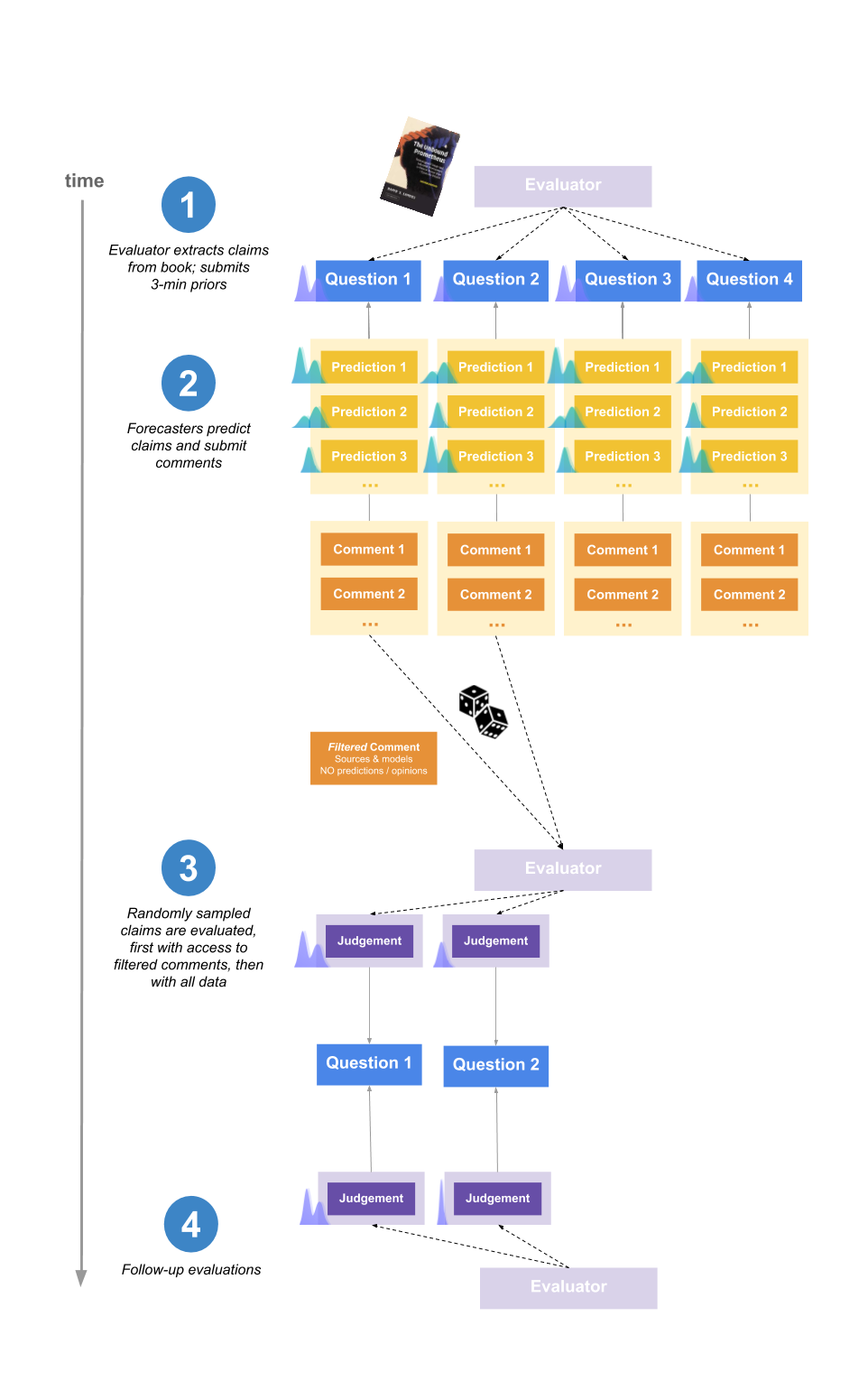
**1\. Evaluator extracts claims from the book and submits priors**
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ All claims were assigned an importance rating from 1-10 based on their relevance
|
|||
|
||||
Elizabeth also spent 3 minutes per claim submitting an initial estimate (referred to as a “prior”).
|
||||
|
||||

|
||||
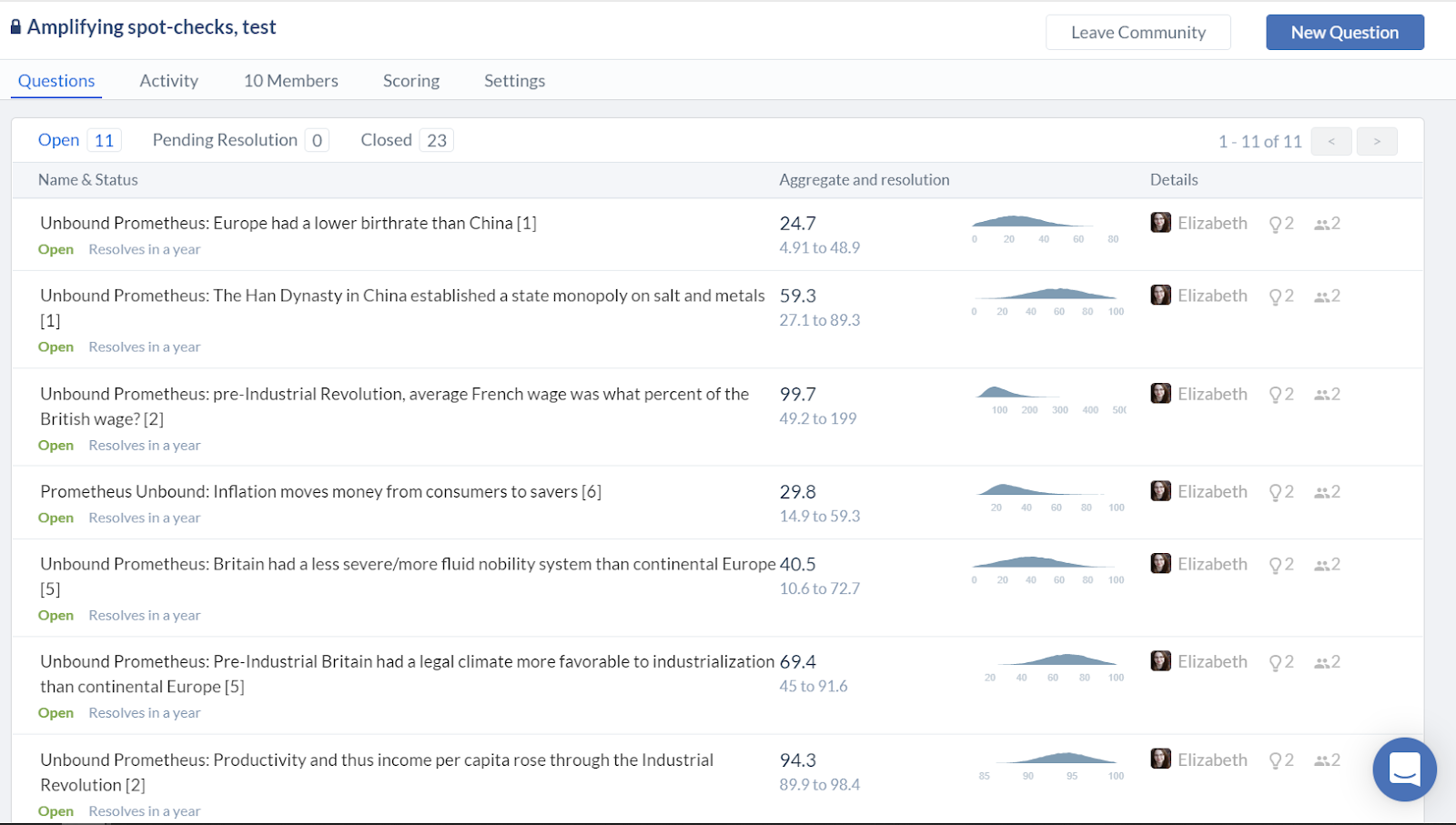
|
||||
|
||||
Beliefs were typically encoded as distributions over the range 0% to 100%, representing where Elizabeth expected the mean of her posterior credence in the claim to be after 10 more hours of research_._ For more explanation, see this footnote \[4\].
|
||||
|
||||
|
|
@ -63,7 +63,7 @@ A key part of the design was that that forecasters _did_ _not know_ which questi
|
|||
|
||||
Two groups of forecasters participated in the experiment: one based on a mailing list with participants interested in participating in forecasting experiments (recruited from effective altruism-adjacent events and other forecasting platforms) \[6\], and one recruited from Positly, an online platform for crowdworkers. The former group is here called “Network-adjacent forecasters” and the latter “Online crowdworkers”.
|
||||
|
||||

|
||||
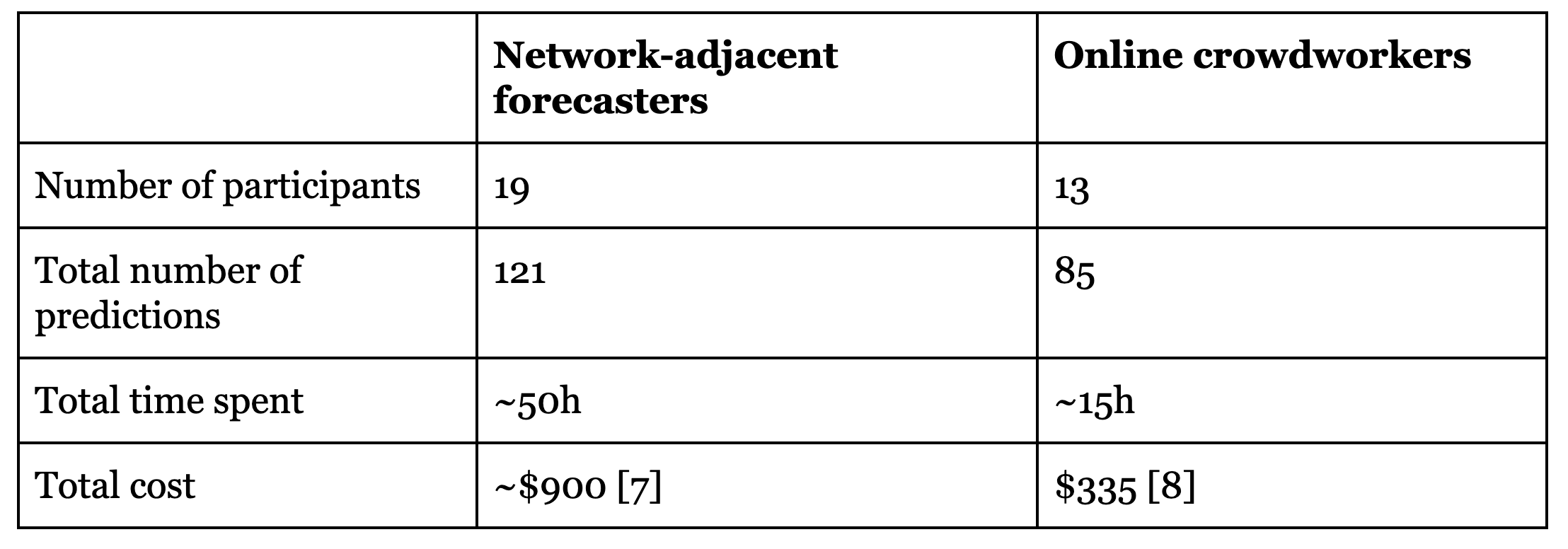
|
||||
|
||||
**3\. The evaluator judges the claims**
|
||||
|
||||
|
|
@ -108,7 +108,7 @@ _You can find all the data and interactive tools for exploring it yourself,_ _[h
|
|||
|
||||
We were interested in comparing the performance of our pool of forecasters to “generic” participants with no prior interest or experience forecasting.
|
||||
|
||||
Hence, after the conclusion of the original experiment, we reran a slightly modified form of the experiment with a group of forecasters recruited through an online platform that sources high quality crowdworkers (who perform microtasks like filling out surveys or labeling images for machine learning models).
|
||||
Hence, after the conclusion of the original experiment, we reran a slightly modified form of the experiment with a group of forecasters recruited through an online platform that sources high quality crowdworkers (who perform microtasks like filling out surveys or labelinghttps://images.nunosempere.com/blog/2019/12/20/amplifying-general-research-via-forecasting-ii for machine learning models).
|
||||
|
||||
However, it should be mentioned that these forecasters were operating under a number of disadvantages relative to other participants, which means we should be careful when interpreting their performance. In particular:
|
||||
|
||||
|
|
@ -125,17 +125,17 @@ The aggregate prediction was computed as the average of all forecasters' final p
|
|||
|
||||
The following graph shows how the aggregate performed on each question:
|
||||
|
||||

|
||||
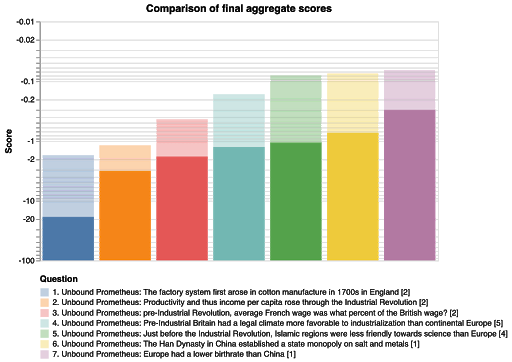
|
||||
|
||||
The opaque bars represent the scores from the crowdworkers, and the translucent bars, which have higher scores throughout, represent the scores from the network-adjacent forecasters. It's interesting that the order is preserved, that is, that the question difficulty was the same for both groups. Finally we don’t see any correlation between question difficulty and the importance weights Elizabeth assigned to the questions.
|
||||
|
||||
However, the comparison is confounded by the fact that more effort was spent from the network-adjacent forecasters. The above graph also doesn’t compare performance to Elizabeth’s priors. Hence we also plot the evolution of the aggregate score over prediction number and time (the first data-point in the below graphs represent Elizabeth’s priors):
|
||||
|
||||

|
||||
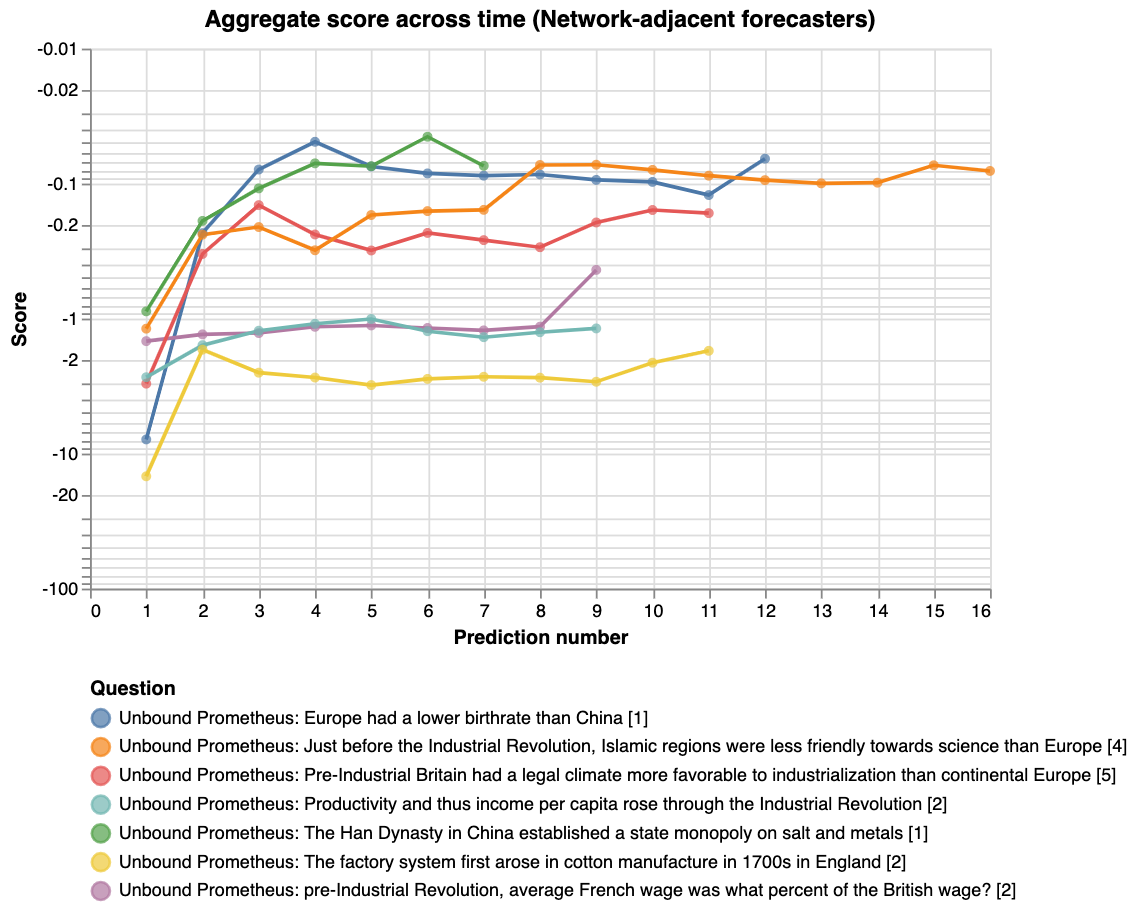
|
||||
|
||||

|
||||
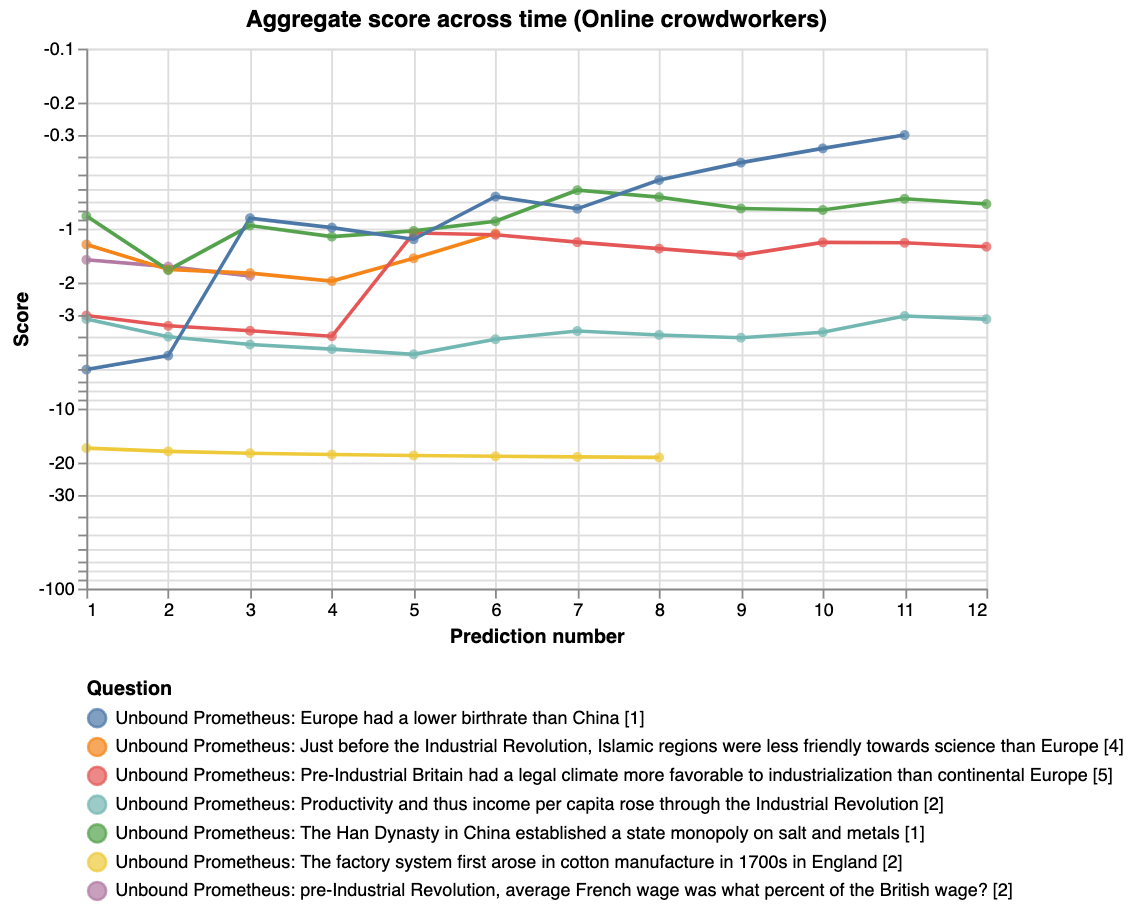
|
||||
|
||||

|
||||
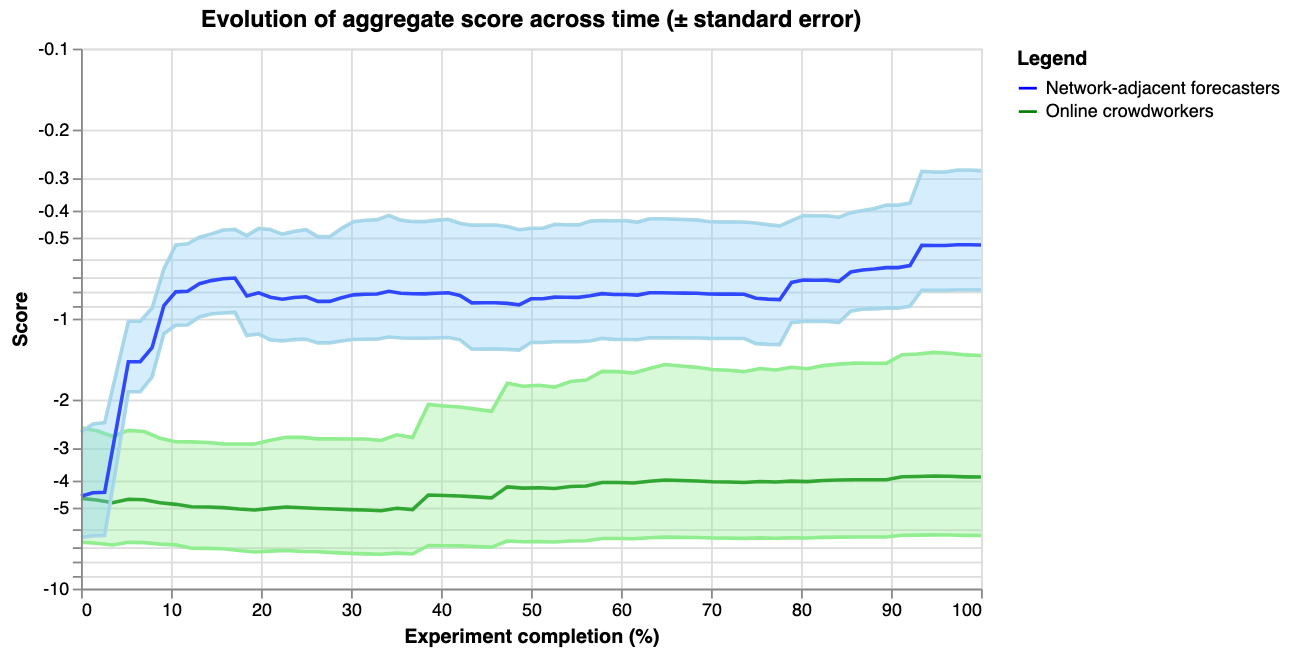
|
||||
|
||||
For the last graph, the y-axis shows the score on a logarithmic scale, and the x-axis shows how far along the experiment is. For example, 14 out of 28 days would correspond to 50%. The thick lines show the average score of the aggregate prediction, across all questions, at each time-point. The shaded areas show the standard error of the scores, so that the graph might be interpreted as a guess of how the two communities would predict a random new question \[10\].
|
||||
|
||||
|
|
@ -147,9 +147,9 @@ One way to see this qualitatively is by observing the graphs below, where we dis
|
|||
|
||||
The x-axis \[12\] refers to the Elizabeth’s best estimate of the accuracy of a claim, from 0% to 100% (see section “Mechanism design, 1. Evaluator extracts claims” for more detail).
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
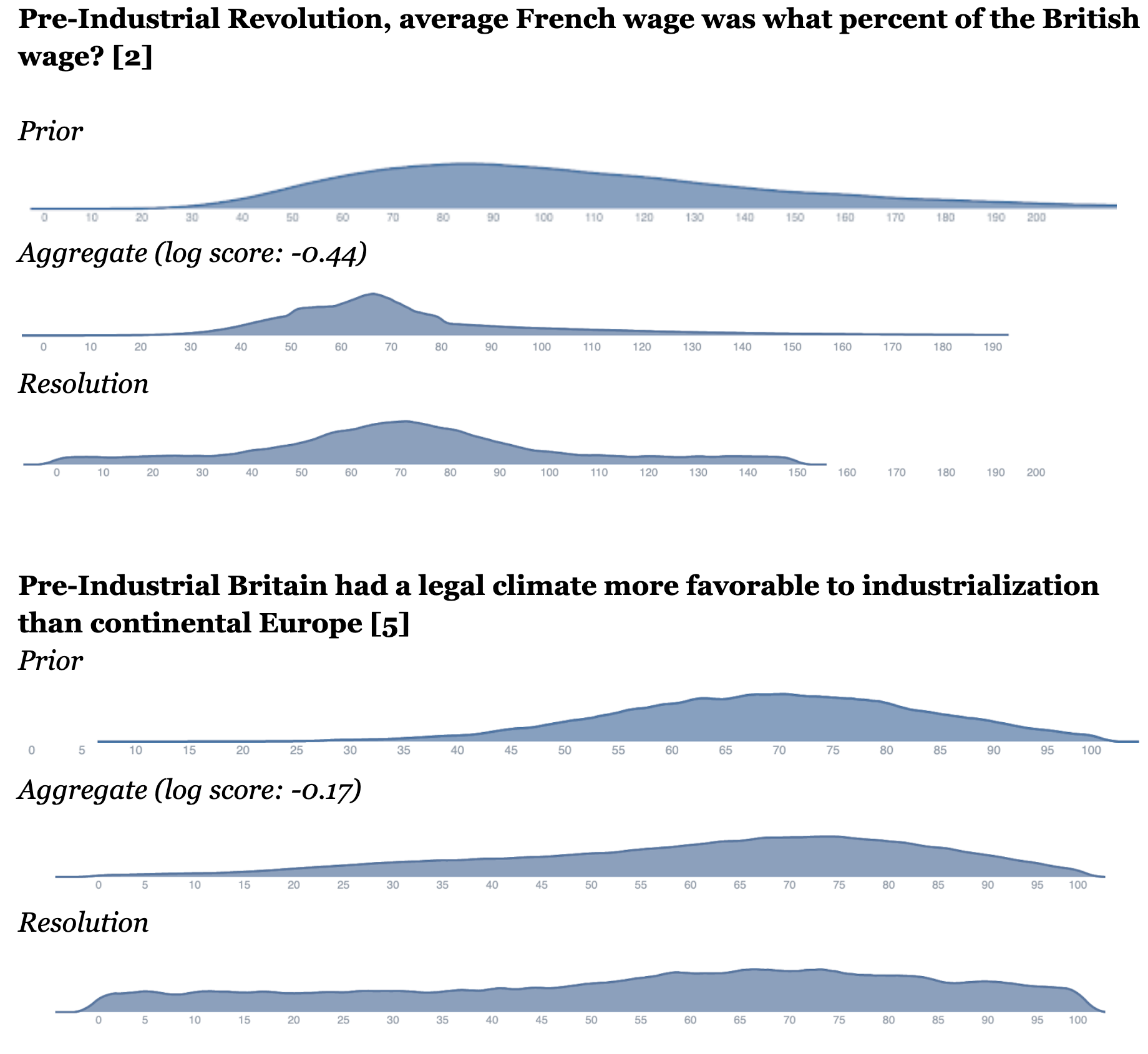
|
||||
|
||||
Another way to understand the performance of the aggregate is to note that the aggregate of network-adjacent forecasters had an average log score of -0.5. To get a rough sense of what that means, it's the score you'd get by being 70% confident in a binary event, and being correct (though note that this binary comparison merely serves to provide intuition, there are technical details making the comparison to a distributional setting a bit tricky).
|
||||
|
||||
|
|
@ -189,7 +189,7 @@ The value is computed using the following model (interactive calculation linked
|
|||
|
||||
Results were as follows.
|
||||
|
||||

|
||||

|
||||
|
||||
_(Links to models: network-adjacent_ _[cost ratio](https://www.getguesstimate.com/models/14521)_ _and_ _[value ratio](https://observablehq.com/@jjj/amplification-effectiveness), online crowdworker_ _[cost ratio](https://www.getguesstimate.com/models/14614)_ _and_ _[value ratio](https://observablehq.com/@jjj/amplification-effectiveness-positly).)_
|
||||
|
||||
|
|
@ -199,7 +199,7 @@ This observation is in tension with the some of the above graphs, which show a t
|
|||
|
||||
Another question to consider when thinking about cost-effectiveness is diminishing returns. The following graph shows how the information gain from additional predictions diminished over time.
|
||||
|
||||

|
||||
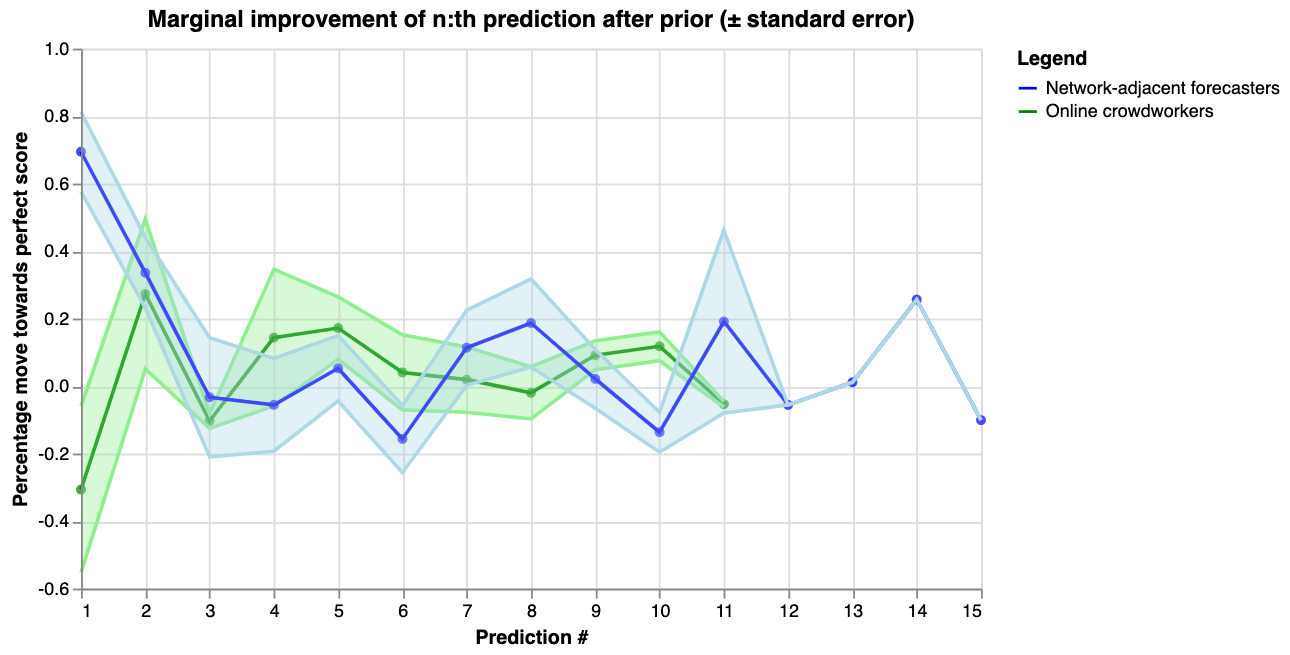
|
||||
|
||||
The x-axis shows the number of predictions after Elizabeth’s prior (which would be prediction number 0). The y-axis shows how much closer to a perfect score each prediction moved the aggregate, as a percentage of the distance between the previous aggregate and the perfect log score of 0 \[15\].
|
||||
|
||||